
[딥러닝 분석 2편] 어텐션 — LLM이 문장을 읽는 방법
Query는 질문, Key는 색인, Value는 내용. 모델이 어디를 볼지 스스로 결정하는 Attention 메커니즘을 다뤄봤습니다. Q/K/V 행렬 연산부터 소프트맥스 어텐션 가중치, Multi-Head의 각 헤드가 보는 것까지 시각화로 정리했습니다.
1편에서 Transformer 전체 구조를 다뤘는데, 이번엔 그 안에서 핵심 역할을 하는 Attention을 봅니다.
"어텐션"이라는 말은 많이 들어봤어도 실제로 어떻게 계산되는지는 의외로 설명이 부족한 경우가 많아서요. ㅎㅎ
Attention의 Q, K, V — 도서관에서 책 찾는 것과 뭐가 비슷할까요?
Attention은 Q(Query, 내가 찾는 정보), K(Key, 각 단어의 색인), V(Value, 실제 단어 내용) 세 가지로 작동합니다. 도서관에서 "파이썬 입문서"를 들고 책장 라벨과 비교해서 가장 맞는 책을 꺼내는 과정과 똑같은 원리인데, 이 Q/K/V는 입력 벡터에 각각 다른 가중치 행렬을 곱해서 만들어요.
2017년 구글 연구팀이 발표한 논문 "Attention is All You Need"는 제목부터 도발적이었습니다.
Vaswani 등 8명의 저자가 발표한 이 논문은, RNN을 완전히 없애고 Attention 메커니즘만으로 번역 SOTA를 달성했습니다.
당시 NLP 연구자들 사이에서는 "설마 RNN 없이도 된다고?" 하는 반응이 많았습니다.
그 결과가 바로 Transformer였고, 이후 모든 LLM의 기반이 됐습니다.
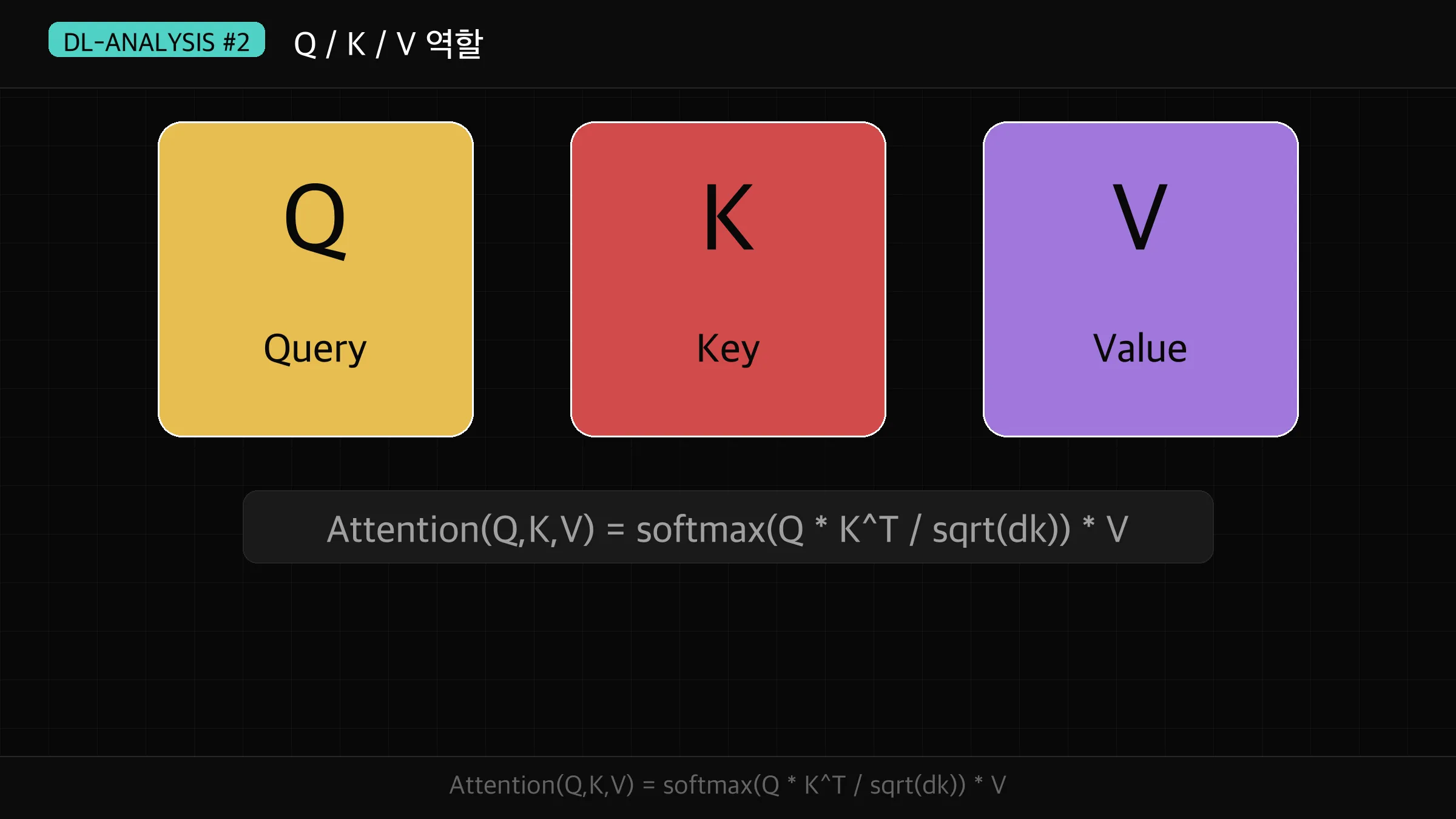
Attention의 핵심 아이디어는 Q(Query), K(Key), V(Value)라는 세 가지 개념으로 설명됩니다.
도서관에서 "파이썬 입문서"를 찾는다고 해봅시다.
내가 찾으려는 것(Query: "파이썬 입문서")을 들고,
책장에 붙은 라벨(Key: "파이썬", "입문", "프로그래밍")과 비교하고,
가장 잘 맞는 책(Value: 실제 책 내용)을 꺼내는 거죠.
Attention이 정확히 이 방식으로 작동합니다.
Q(Query)는 내가 찾는 정보, K(Key)는 각 단어의 색인 정보, V(Value)는 실제 단어 내용입니다.
이 세 가지가 어디서 오는지도 중요합니다.
Q, K, V는 입력 벡터에 각각 다른 가중치 행렬 W_Q, W_K, W_V를 곱해서 만듭니다.
Self-Attention에서는 Q, K, V 모두 같은 입력 벡터에서 만들어집니다.
"나는 학교에 간다"라는 문장이 있으면,
각 단어의 벡터를 세 방향으로 선형 변환해서 Q, K, V를 각각 생성합니다.
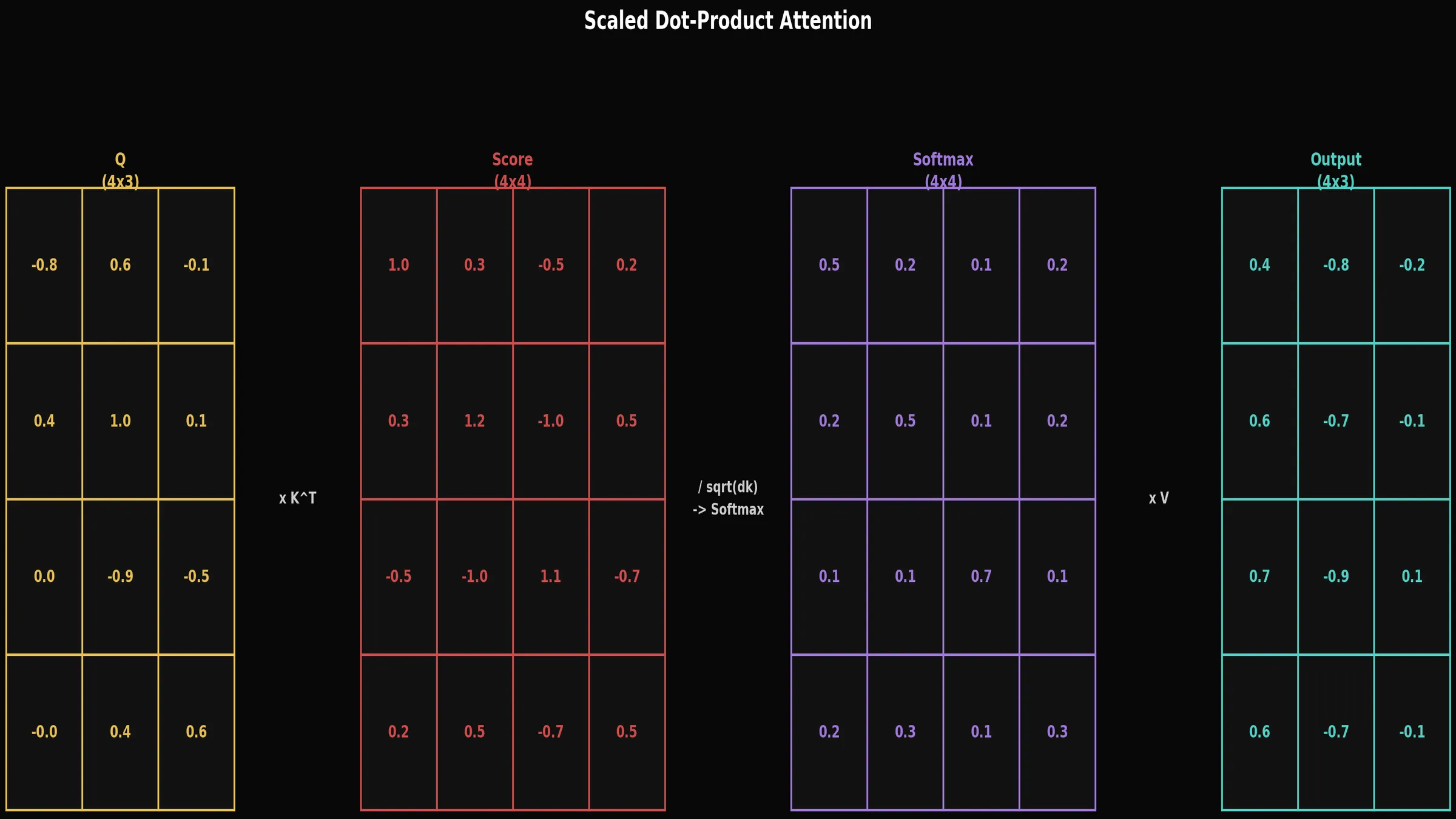
Attention 계산 — 구체적으로 어떤 4단계를 거칠까요?
Q, K, V가 준비됐으면 다음 4단계로 Attention을 계산합니다.
각 단계가 왜 필요한지 함께 살펴봅시다.
- Q * K^T: 쿼리와 모든 키의 유사도를 내적(dot product)으로 계산합니다. 내적은 두 벡터가 얼마나 같은 방향을 가리키는지 측정합니다. 값이 클수록 두 단어가 서로 관련이 깊다는 신호입니다. (쉽게 말하면: 두 벡터를 "얼마나 같은 방향을 가리키는가"로 비교하는 계산입니다. 방향이 비슷할수록 내적값이 크게 나옵니다.)
- / sqrt(d_k): 차원 크기(d_k)의 제곱근으로 나눠서 값이 너무 커지지 않게 조정합니다. 이 단계가 왜 필요한지는 조금 뒤에 자세히 설명합니다.
- Softmax: 유사도를 0~1 사이 확률 값(어텐션 가중치)으로 변환합니다. 모든 단어에 대한 가중치의 합은 항상 1이 됩니다. "이 단어에 70% 집중하고, 저 단어에 20% 집중하겠다"는 분포를 만드는 겁니다.
- * V: 가중치만큼 각 단어의 Value를 가져옵니다. 어텐션이 높은 단어의 정보를 더 많이 반영한 최종 표현이 만들어집니다.
수식으로 한 줄로 표현하면 이렇습니다.
Attention(Q, K, V) = softmax(Q * K^T / sqrt(d_k)) * V
sqrt(d_k)로 나누는 이유를 좀 더 설명하면,
차원(d_k)이 커질수록 내적값의 크기도 같이 커집니다.
예를 들어 d_k=64이면 내적값이 평균적으로 8배 정도 커집니다.
이 상태로 Softmax를 적용하면 가장 큰 값 하나에 확률이 거의 몰리는 "날카로운" 분포가 만들어지고,
나머지 단어들의 기울기가 거의 0에 가까워집니다.
이를 방지하기 위해 sqrt(d_k)로 나눠서 내적값의 스케일을 조정합니다.
(쉽게 말하면: 값이 너무 커지면 Softmax가 한 곳에 지나치게 몰려버립니다. 예를 들어 [100, 1, 1]에 Softmax를 하면 거의 [1, 0, 0]이 됩니다. 이걸 [10, 0.1, 0.1]로 스케일을 줄이면 좀 더 골고루 분포되죠.)
처음 접했을 때 sqrt(d_k)로 나눈다는 게 왜 필요한지 바로 납득이 안 됐어요. Scaling이라는 단어의 뜻풀이를 하면 "크기를 조절한다"는 뜻입니다. 숫자가 너무 크면 Softmax가 제 역할을 못 한다는 걸 알고 나서야, 이 단계가 그냥 형식적인 게 아니라 학습이 안 터지게 하는 안전장치라는 게 보이더라고요.
sqrt(d_k)로 나누는 이유를 좀 더 설명하면,
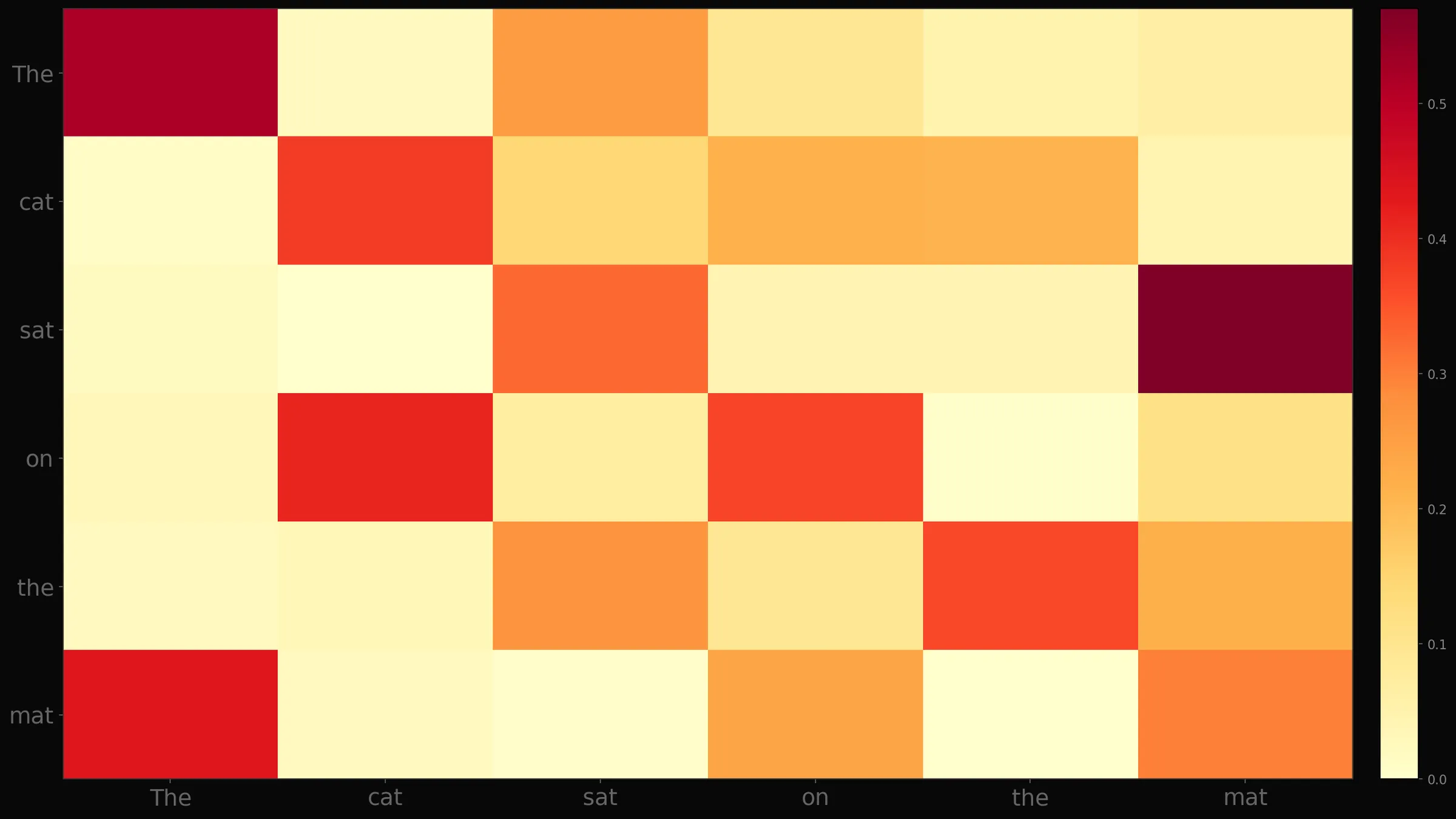
어텐션 가중치 히트맵 — 모델이 어디를 보는지 어떻게 확인할까요?
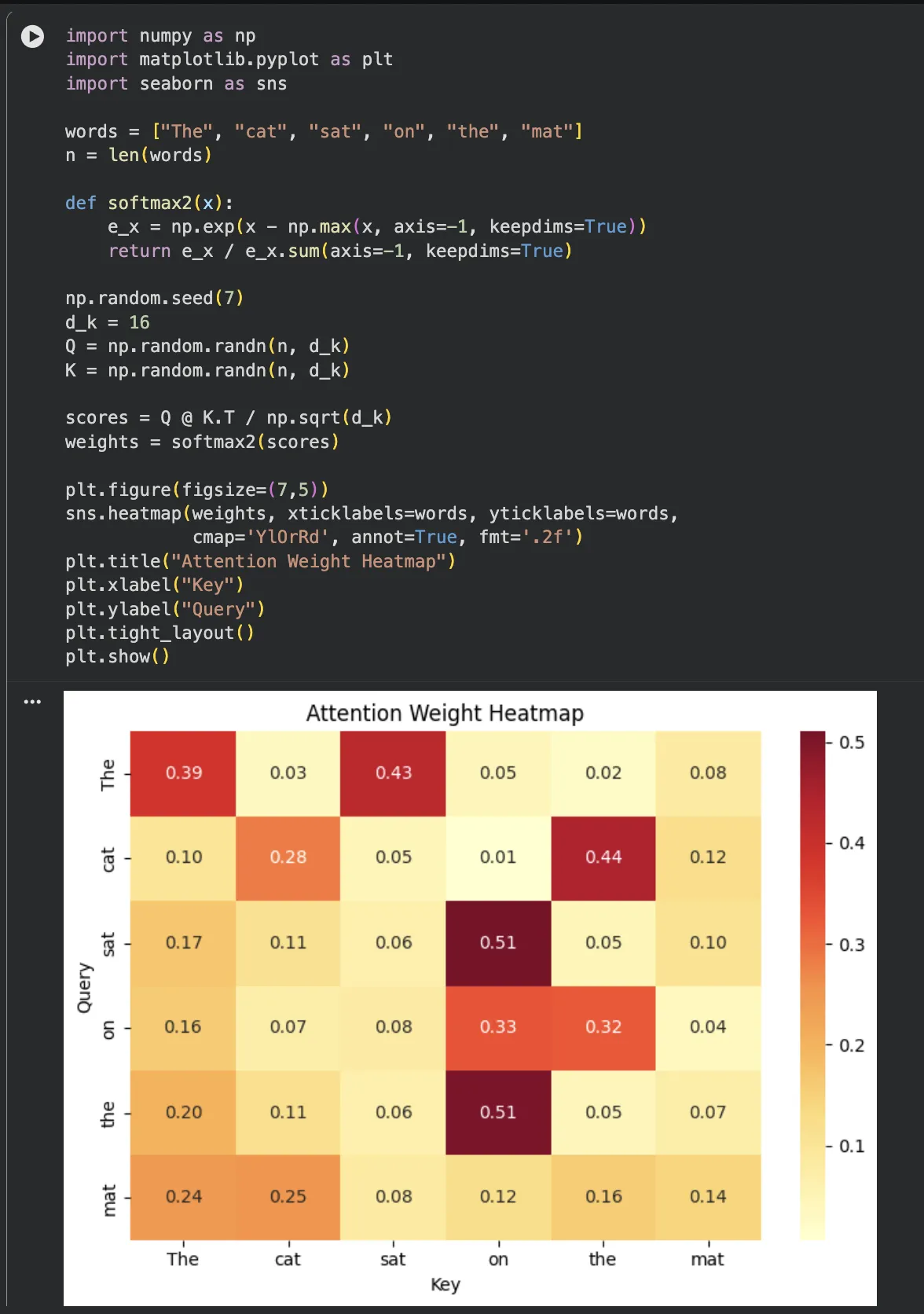
"The cat sat on the mat"이라는 문장에서 Softmax 이후 어텐션 가중치를 시각화하면 이렇습니다.
색이 밝을수록 높은 어텐션 가중치를 가집니다.
"cat"이 "sat"를 볼 때 가중치가 높은 건, 주어-동사 관계를 파악했다는 신호입니다.
예를 들어 "on"이 "mat"를 강하게 본다면 전치사-명사 관계를 학습한 신호입니다.
이렇게 히트맵으로 모델이 어떤 언어적 관계를 파악하는지 직접 눈으로 확인할 수 있다는 점이
Attention의 장점 중 하나입니다.
Clark et al.(2019) 연구에서 BERT의 어텐션 헤드를 분석한 결과, 흥미로운 패턴들이 발견됐습니다.
어떤 헤드는 항상 바로 직전 단어만 봤고, 어떤 헤드는 항상 문장 끝의 [SEP] 토큰에 집중했습니다.
특정 헤드는 주어를 찾는 데 특화됐고, 또 다른 헤드는 동사의 목적어를 추적했습니다.
모델이 스스로 학습하면서 자연스럽게 이런 역할 분담이 생겨났습니다.
이처럼 어텐션 가중치는 단순한 연산 결과가 아니라,
모델이 언어를 어떻게 이해하는지를 들여다볼 수 있는 창이기도 합니다.
물론 히트맵이 모델의 내부 표현을 완전히 설명해주지는 않지만,
해석 가능성(interpretability) 연구에서 중요한 출발점이 됩니다.
(쉽게 말하면: "이 AI가 왜 이런 답을 냈는지" 사람이 이해할 수 있게 해주는 연구 분야입니다. Attention 히트맵이 그 단서 역할을 합니다.)
Self-Attention vs Cross-Attention — 뭐가 다른가요?
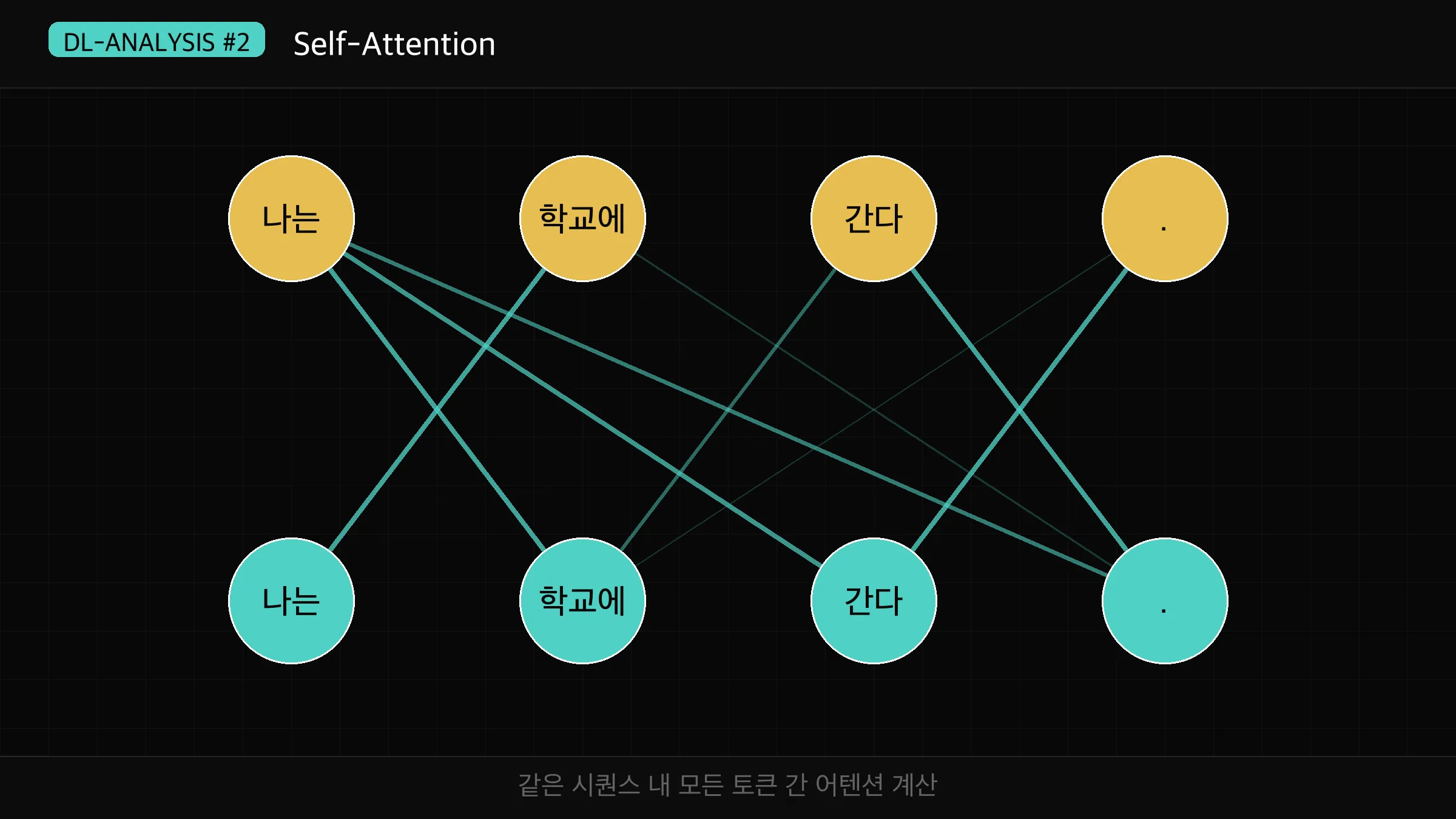
Self-Attention은 같은 문장 안에서 단어끼리 서로를 봅니다.
인코더에서 입력 문장의 단어들이 서로의 관계를 파악할 때 사용합니다.
"나는 학교에 간다"라는 문장에서 "나는"이 "간다"와 어떤 관계인지,
"학교에"가 문장 전체에서 어떤 역할을 하는지를 파악합니다.
Q, K, V가 모두 같은 입력에서 오기 때문에 Self-Attention이라고 부릅니다.
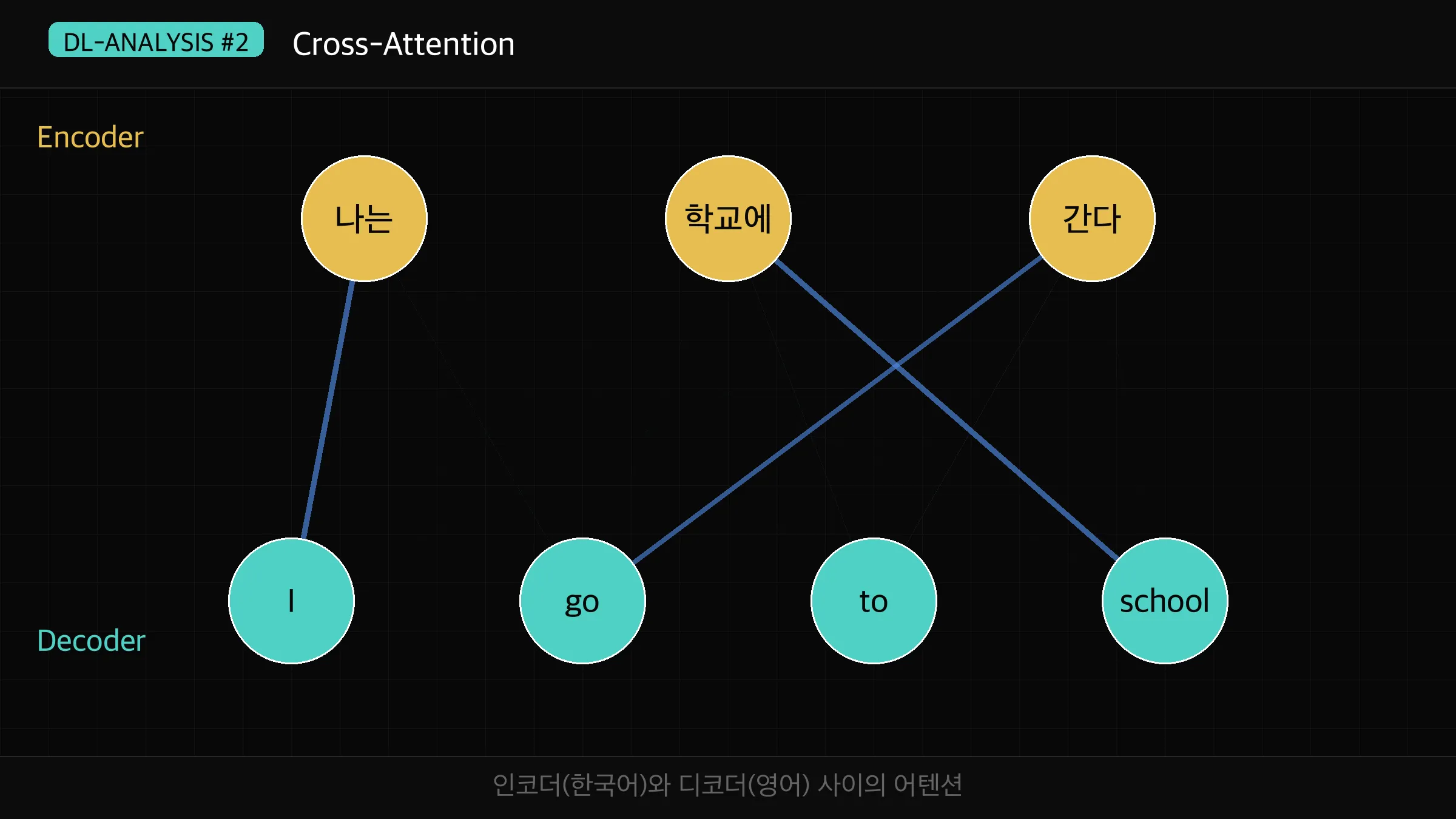
Cross-Attention은 디코더가 인코더의 출력을 참고할 때 사용합니다.
Q는 디코더에서 오고, K와 V는 인코더의 출력에서 옵니다.
번역 시 디코더가 "I"를 생성하려 할 때, 인코더가 만든 "나는"의 표현을 참조하는 방식입니다.
이 구조 차이가 현대 LLM들의 계열을 나눕니다.
GPT 계열은 디코더만 사용합니다. 텍스트를 왼쪽에서 오른쪽으로 생성하는 데 특화됐고,
Masked Self-Attention으로 미래 토큰을 보지 않습니다.
반면 BERT 계열은 인코더만 사용합니다.
양방향으로 문장 전체를 보기 때문에 문맥 이해에 강하고,
분류나 질의응답 같은 태스크에 적합합니다.
번역처럼 입력과 출력이 명확히 구분되는 경우에는 인코더-디코더 구조(T5, BART)가 사용됩니다.
Multi-Head — 왜 여러 관점으로 동시에 볼까요?
하나의 Attention은 하나의 관점만 볼 수 있습니다.
Multi-Head는 서로 다른 가중치 행렬로 초기화된 헤드를 여러 개 병렬로 실행합니다.
각 헤드는 독립된 W_Q, W_K, W_V 행렬을 가지고 있어서, 입력을 서로 다른 방식으로 변환합니다.
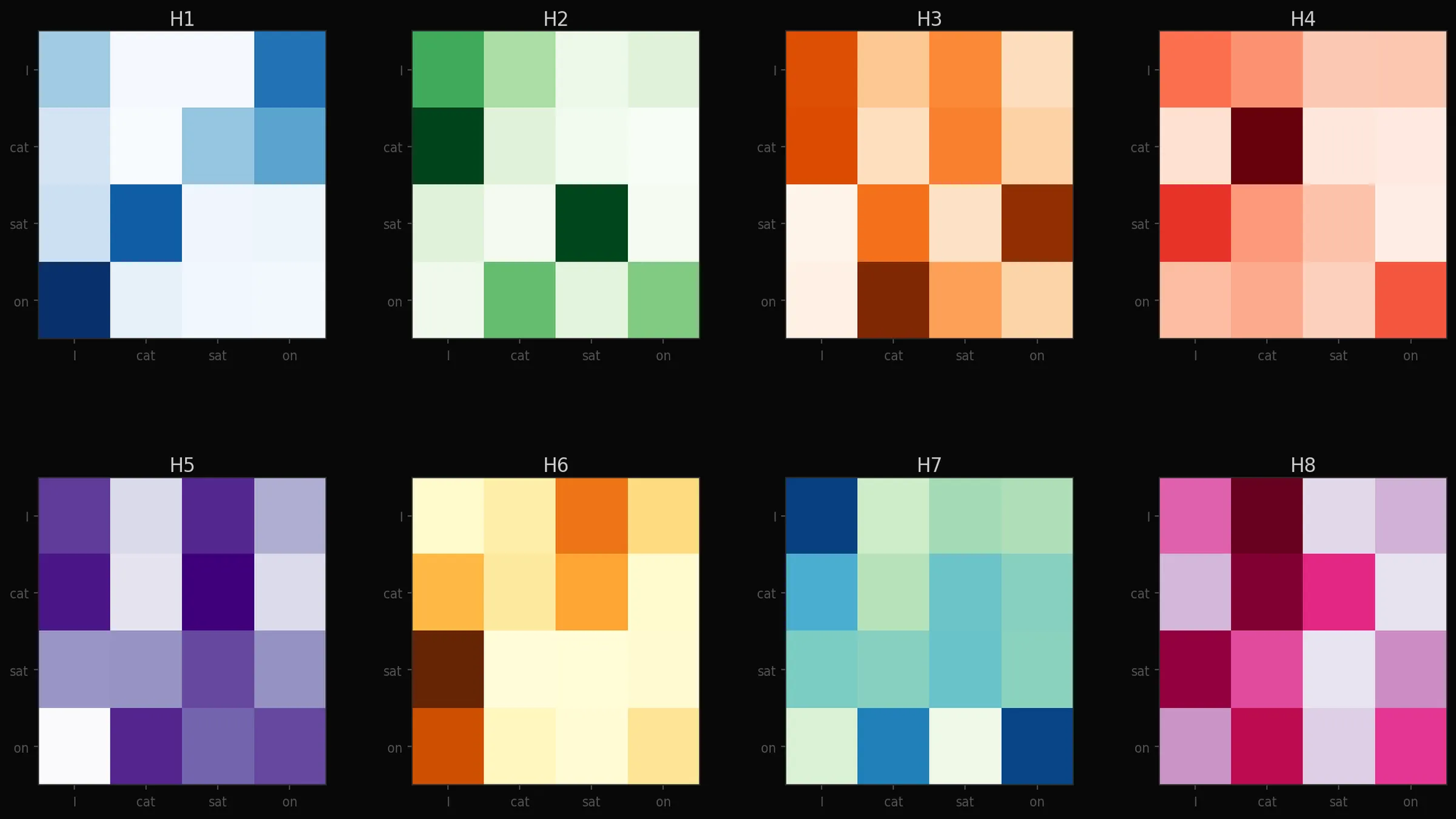
각 헤드가 학습하면서 자연스럽게 다른 언어 패턴을 전담하게 됩니다.
헤드 1은 주어-동사, 헤드 2는 수식어-명사, 헤드 3은 지시어-참조 같은 식으로요.
이 역할 분담은 사람이 정해준 게 아니라 학습 데이터에서 자연스럽게 나타나는 결과입니다.
h개 헤드의 결과를 이어 붙여서(Concatenate) W_O라는 선형 변환 행렬을 곱하면 최종 출력이 나옵니다.
(쉽게 말하면: 8개 헤드의 결과를 이어 붙인 긴 벡터를 다시 원래 차원으로 압축해주는 행렬입니다.)
계산량은 단일 헤드와 비슷하지만, 다양한 관점의 정보를 통합하기 때문에 표현력이 훨씬 풍부해집니다.
원래 Transformer 논문에서는 8개의 헤드를 사용했고, GPT-3는 96개의 헤드를 사용합니다.
Attention 수식 한 줄로 정리
지금까지 설명한 내용을 수식 하나로 압축하면 이렇습니다.
Attention(Q, K, V) = softmax(Q * K^T / sqrt(d_k)) * V
이 수식이 단순해 보여도, 안에는 꽤 많은 아이디어가 담겨 있습니다.
내적으로 유사도를 측정하고, 스케일을 조정하고, Softmax로 분포를 만들고, 가중합으로 최종 표현을 추출합니다.
이 네 단계가 Attention의 전부입니다.
코드로 직접 구현해보기
Attention은 외부 라이브러리 없이 numpy만으로 구현할 수 있습니다.
수식 그대로를 코드로 옮기면 되기 때문에, 직접 짜보면 개념이 훨씬 명확해집니다.
실습은 세 파트로 구성됩니다.
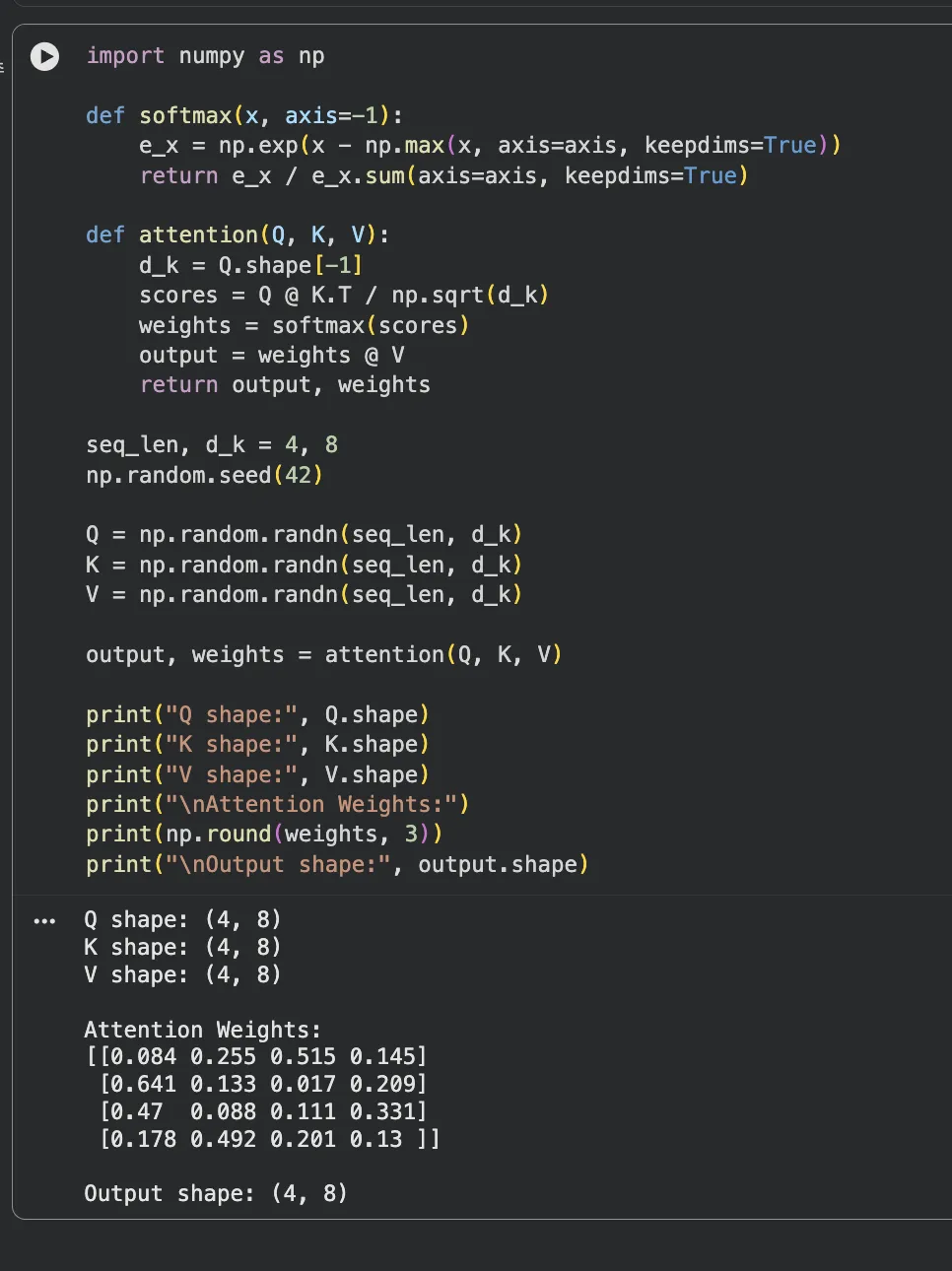
- 파트 1 — numpy로 Attention 구현 (약 20줄): Q, K, V 행렬을 랜덤으로 만들고, 수식 그대로 내적 → 스케일 → Softmax → 가중합을 직접 계산합니다. 어느 단계에서 어떤 모양의 행렬이 나오는지 shape를 찍어보면 전체 흐름이 한눈에 들어옵니다.
- 파트 2 — 어텐션 가중치 히트맵 시각화: "The cat sat on the mat" 문장에 대해 Softmax 이후 어텐션 가중치를 seaborn 히트맵으로 그립니다. 어떤 단어 쌍의 가중치가 높은지 직접 확인해보세요.
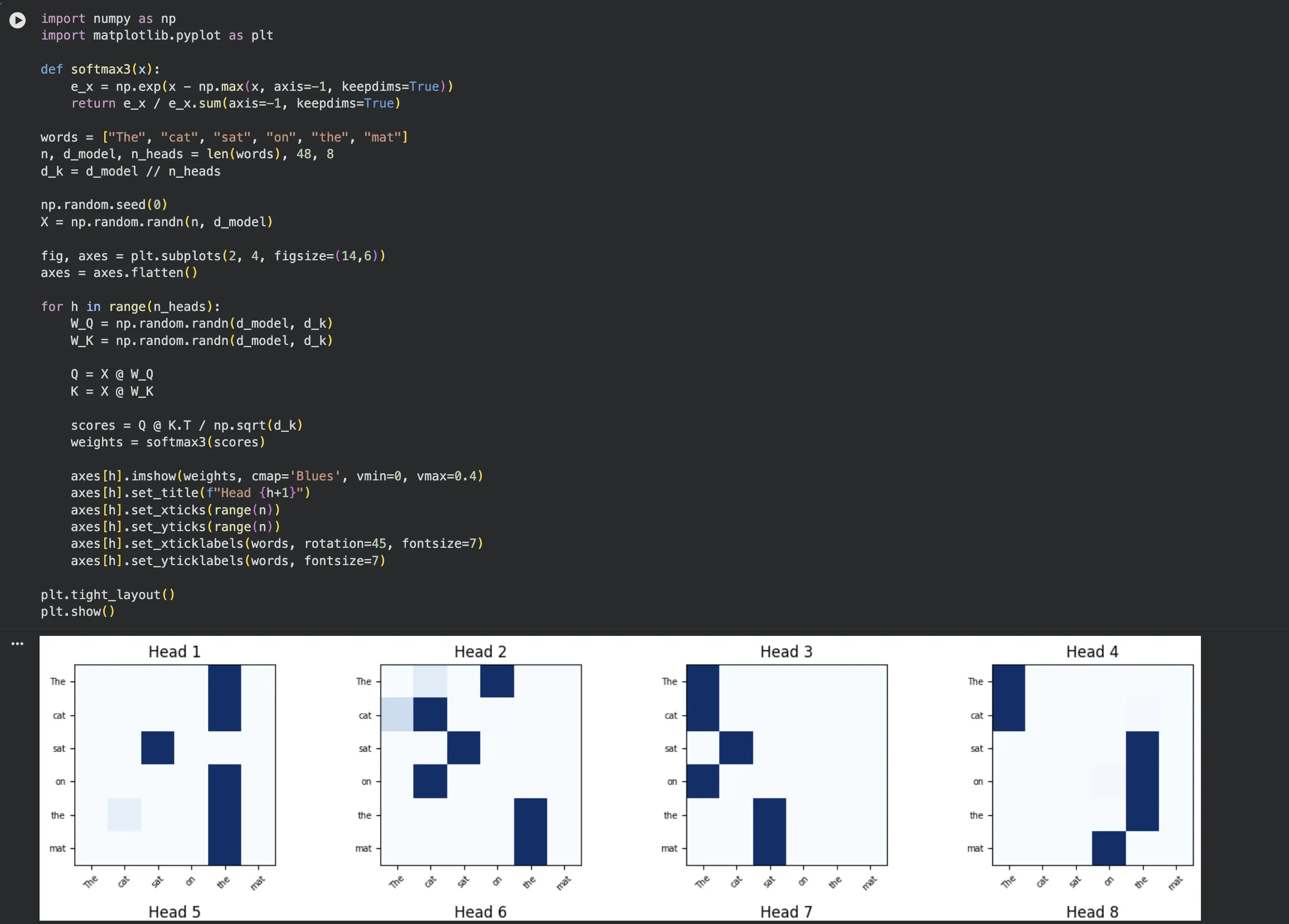
- 파트 3 — Multi-Head Attention 구현 + 헤드별 비교: 8개의 헤드를 병렬로 실행하고, 각 헤드의 가중치 패턴이 얼마나 다른지 나란히 시각화합니다. 헤드마다 다른 언어 패턴에 집중한다는 것을 직접 눈으로 확인할 수 있습니다.
Jupyter 실행 결과 보기 — 파트 1: numpy로 Attention 구현
Jupyter 실행 결과 보기 — 파트 2: 어텐션 가중치 히트맵
Jupyter 실행 결과 보기 — 파트 3: Multi-Head 헤드별 패턴 비교
특히 파트 1에서 scores = Q @ K.T / np.sqrt(d_k) 한 줄이
수식의 Q * K^T / sqrt(d_k)와 1:1로 대응된다는 걸 보면,
Attention이 결국 "행렬 곱 + 나누기 + softmax"로 이루어진 단순한 연산임을 체감할 수 있습니다.
정리 — Attention이 왜 LLM의 핵심인가
- 거리에 관계없이 단어 사이 관계를 직접 포착합니다. RNN처럼 중간 단계를 경유하지 않습니다.
- 해석 가능성: 히트맵으로 모델이 어디를 보는지 시각화할 수 있습니다. 블랙박스가 조금이나마 열립니다.
- 병렬 처리: Q, K, V 행렬 연산은 GPU에서 완전히 병렬로 실행됩니다. 긴 문장도 짧은 문장과 같은 연산 단계 수로 처리합니다.
Attention의 영향력은 NLP에서 멈추지 않았습니다.
이미지를 패치 단위로 나눠 시퀀스로 취급하는 Vision Transformer(ViT),
음성 신호를 토큰화해서 처리하는 Whisper,
단백질 구조를 예측하는 AlphaFold2까지 모두 Attention 메커니즘을 활용합니다.
"모든 것을 시퀀스로 보고, Attention으로 관계를 파악한다"는 아이디어가 이렇게 광범위하게 퍼졌습니다.
다음 편에서는 Transformer 블록에서 Attention 다음에 오는 FFN(Feed-Forward Network)을 다룹니다.
LLM이 학습한 지식이 실제로 어디에 저장되는지, 이 부분이 생각보다 흥미로워서 따로 정리해봤습니다.