
[딥러닝 분석 3편] MLP — LLM이 지식을 저장하는 곳
GPT가 '파리는 프랑스의 수도'라는 사실을 어디에 저장할까요? Transformer 블록의 FFN(Feed-Forward Network)이 그 역할을 담당합니다. 활성화 함수 비교, 512→2048→512 차원 변화, 지식 저장 방식까지 FFN 구조를 정리해봤습니다.
1편 Transformer, 2편 Attention에 이어 마지막 3편입니다.
이번엔 FFN(MLP) 구조를 다루는데, "LLM 지식이 어디에 저장되는가"라는 질문이 여기서 나오거든요. 이게 꽤 재밌는 부분이라서요. ㅎㅎ
GPT는 어디에 지식을 저장하나요?
LLM의 지식은 Transformer 블록 안의 FFN(Feed-Forward Network)에 저장됩니다. Attention이 "어떤 정보를 가져올지" 결정하는 라우터라면, FFN은 실제 지식을 담고 있는 처리 장치예요. 각 뉴런이 "파리 → 프랑스 수도" 같은 패턴을 키-밸류 메모리 형태로 기억하고 있습니다.
"파리는 어느 나라 수도야?"라고 물으면 ChatGPT가 바로 "프랑스"라고 답합니다.
이 지식은 대체 어디에 저장되어 있는 걸까요?
Attention이 "나는 파리에 관한 정보가 필요하다"고 결정한다면,
그 정보를 실제로 꺼내는 역할은 누가 하는 걸까요?
답은 FFN(Feed-Forward Network)입니다.
Transformer 블록에서 Attention 다음에 오는 구조입니다.
FFN은 MLP(Multi-Layer Perceptron)와 본질적으로 같은 구조입니다.
두 단어를 구분해서 쓰는 경우도 있지만, Transformer 문헌에서는 FFN과 MLP를 같은 의미로 사용합니다.
Transformer 블록 하나를 보면 Multi-Head Attention → Add&Norm → FFN(MLP) → Add&Norm 순서로 구성됩니다.
Attention이 "어떤 정보를 어디서 가져올지" 결정하는 라우터라면,
FFN은 그 정보를 처리하고 지식을 활용해서 출력을 만드는 처리 장치입니다.
2021년 Geva 등의 연구("Transformer Feed-Forward Layers Are Key-Value Memories")에 따르면,
FFN의 각 뉴런이 특정 지식 패턴을 저장하는 "키-밸류 메모리" 역할을 한다는 것이 밝혀졌습니다.
뉴런 하나하나가 "이런 패턴이 들어오면(Key) 이런 값을 반환한다(Value)"는 형태로 지식을 저장합니다.
(쉽게 말하면: 사전처럼 "파리 → 프랑스 수도", "도쿄 → 일본 수도" 같은 패턴을 뉴런 하나하나가 기억하고 있다는 뜻입니다.)
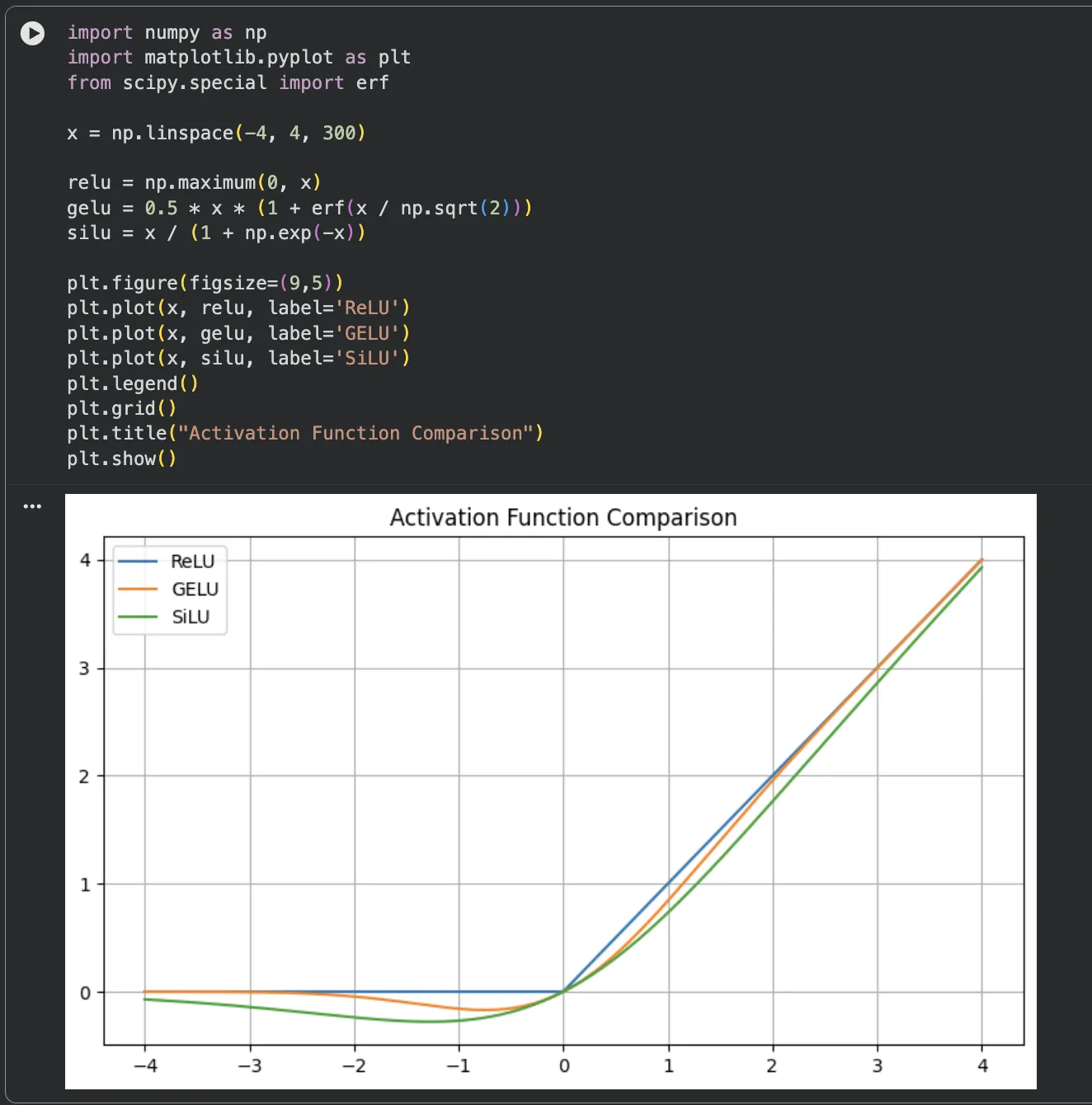
ReLU, GELU, SiLU — LLM은 왜 ReLU를 안 쓸까요?
초기 딥러닝은 ReLU를 많이 썼습니다.
0 이하는 완전히 0, 0 이상은 그대로 통과. 간단하고 빠르지만
0에서 꺾이는 지점이 있어서, 그 경계에서 기울기가 불연속적으로 변합니다.
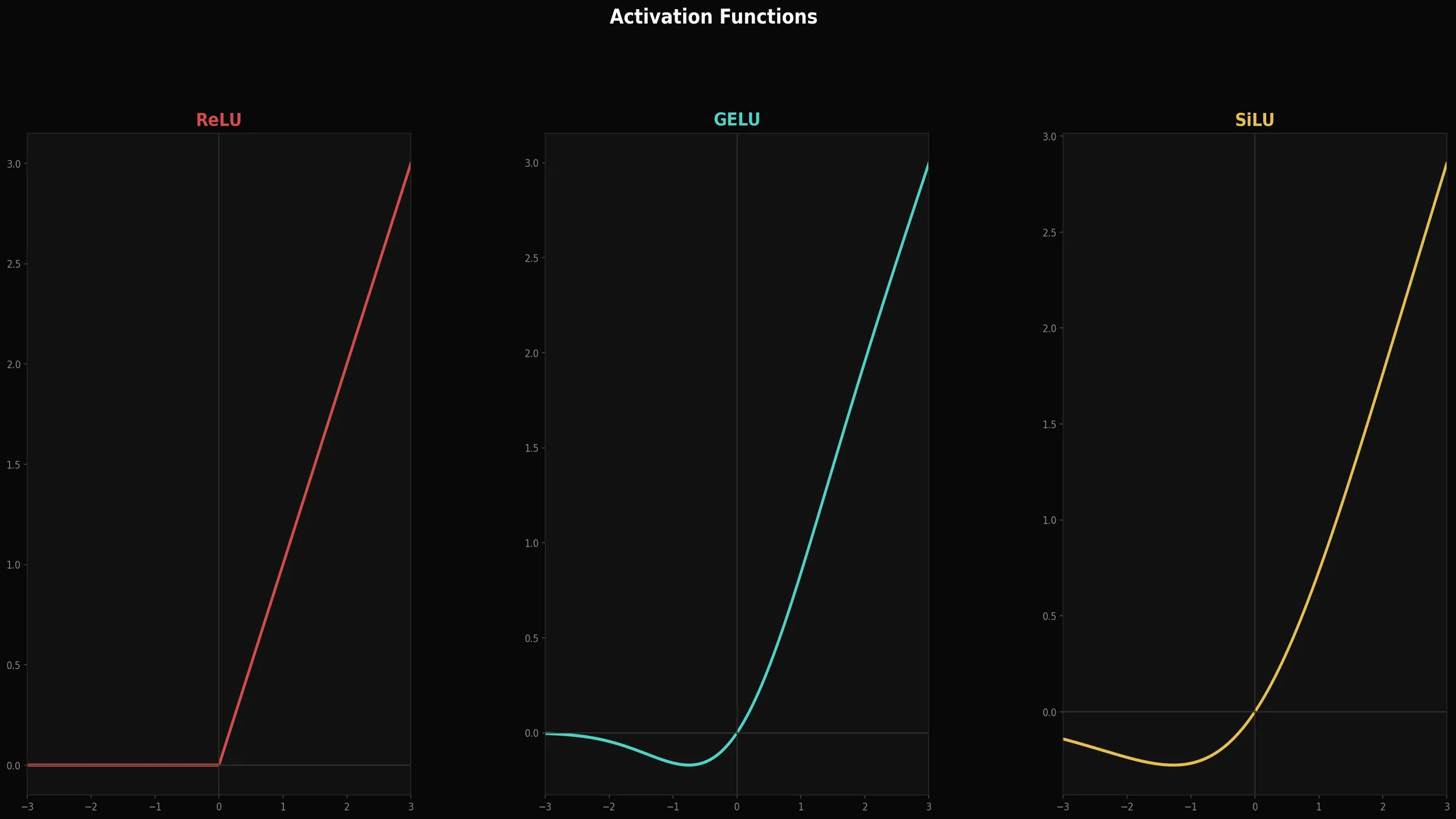
하지만 최신 LLM은 GELU나 SiLU를 사용합니다. 이유는 두 가지입니다.
첫째, 부드러운 전환입니다.
ReLU는 0에서 날카롭게 꺾이지만, GELU/SiLU는 곡선으로 부드럽게 전환됩니다.
기울기가 더 안정적이고 학습이 원활해집니다.
둘째, 약한 음수 허용입니다.
GELU/SiLU는 음수 범위에서도 아주 작은 값을 통과시킵니다.
ReLU는 음수 입력에서 기울기가 완전히 0이 되는 "죽은 뉴런" 문제가 생길 수 있는데, GELU/SiLU는 이를 완화합니다.
(쉽게 말하면: ReLU는 음수 입력에서 출력이 완전히 0이 되어 그 뉴런은 영영 학습이 안 되는 "죽은 뉴런" 상태가 됩니다. GELU/SiLU는 음수 구간에서도 아주 작은 값을 내보내서 이 문제를 줄입니다.)
수식으로 보면 이렇습니다.
GELU는 GELU(x) ≈ 0.5x(1 + tanh(sqrt(2/π)(x + 0.044715x³)))로 정의됩니다.
SiLU는 훨씬 간결하게 SiLU(x) = x * sigmoid(x)입니다.
sigmoid를 곱하면 자연스럽게 음수에서는 작은 값이, 양수에서는 입력에 가까운 값이 나옵니다.
이런 미세한 차이가 왜 중요할까요?
GPT-2는 GELU, LLaMA 2/3는 SiLU(Swish)를 사용합니다.
수백억 파라미터 규모의 모델에서는 모든 FFN 블록에 이 함수가 적용됩니다.
수십 층, 수백만 개의 뉴런에서 미세한 차이가 누적되면 최종 성능에 의미 있는 영향을 줍니다.
소규모 모델에서는 눈에 띄지 않던 차이가 대규모에서는 중요해지는 이유입니다.
FFN이 지식을 저장하는 방식은 뭘까요?
"파리는 어느 나라 수도야?" 예시로 생각해봅시다.
"파리"라는 단어가 입력되면 FFN의 특정 뉴런들이 강하게 활성화됩니다.
이 뉴런들이 "파리 → 프랑스", "파리 → 에펠탑", "파리 → 유럽" 같은 연관 지식을 담고 있습니다.
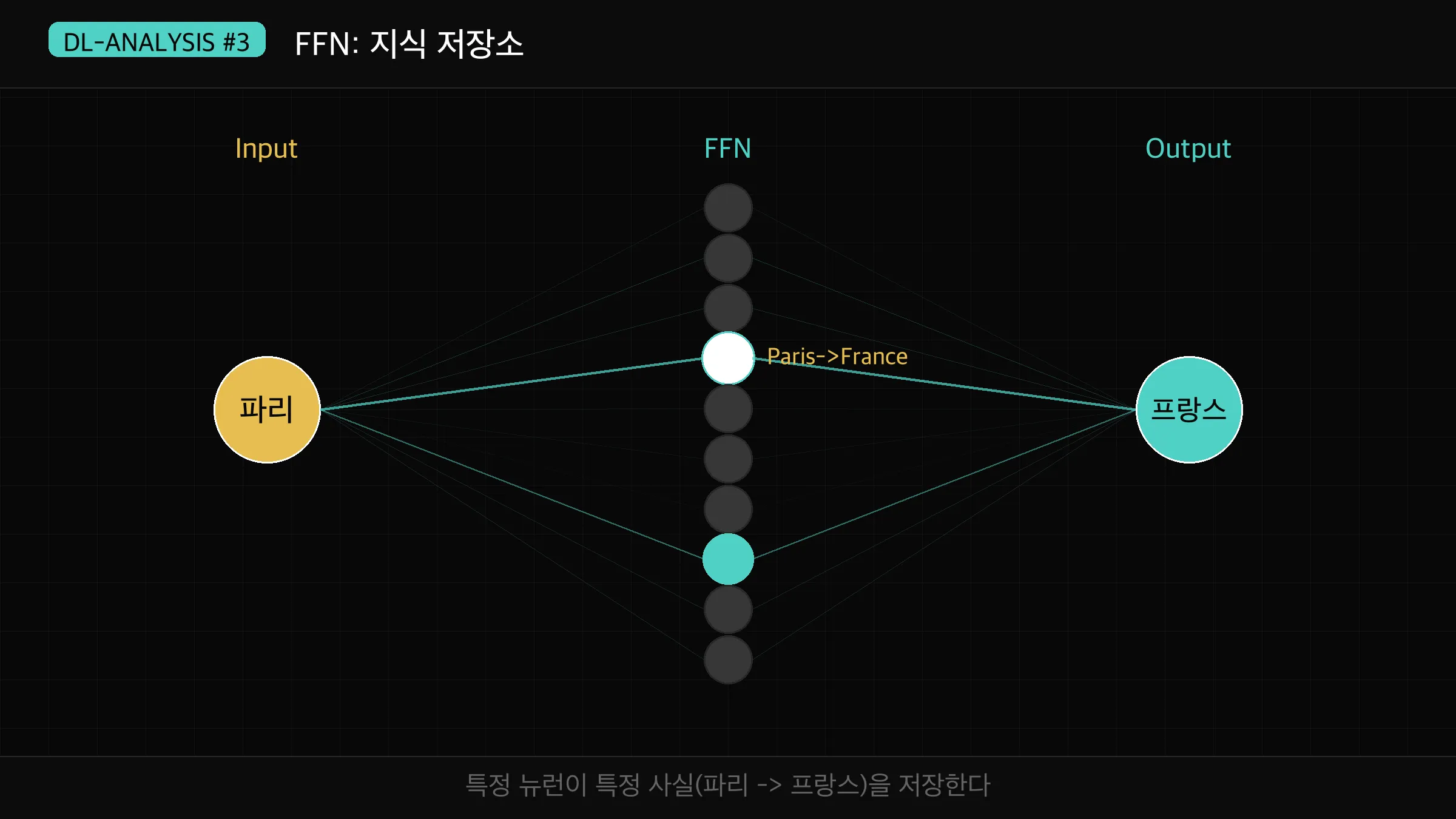
각 뉴런은 "어떤 패턴이 들어오면(Key) 어떤 값을 반환할지(Value)"를 학습합니다.
방대한 수의 뉴런이 각자 다른 지식 조각을 저장하고 있는 거죠.
흥미로운 점은 층마다 저장하는 지식의 수준이 다르다는 겁니다.
초반 층은 주로 구문과 문법적 패턴을 저장합니다. "이 단어 뒤에는 명사가 온다"는 식의 표면적 규칙들입니다.
중간 층은 의미 관계를 저장합니다. "파리"와 "도시", "유럽"의 연관성 같은 것들입니다.
후반 층은 사실적 지식을 저장합니다. "파리는 프랑스의 수도다"와 같은 구체적인 팩트입니다.
이 발견은 지식 편집(knowledge editing) 연구와 연결됩니다.
(쉽게 말하면: 모델 전체를 다시 학습시키지 않고, "이 한 가지 사실만 바꾸고 싶다"고 할 때 해당 뉴런만 찾아서 수정하려는 연구입니다.)
"파리는 프랑스의 수도다"라는 사실을 모델에서 수정하고 싶다면,
전체 모델을 다시 학습할 필요 없이
해당 지식을 저장한 특정 FFN 뉴런들을 찾아서 수정하는 방법을 연구하고 있습니다.
ROME, MEMIT 같은 연구들이 이 방향으로 진행되고 있습니다.
공부하면서 Feed-Forward Network라는 이름이 막막했는데, 단어 그대로 풀면 "앞으로 흘려보내는 네트워크"에요. 뒤로 돌아가지 않고 입력이 한 방향으로만 흐른다는 뜻입니다. Transformer 안에서 어텐션이 단어 간 관계를 파악하고 나면, FFN이 그 정보를 받아서 최종적으로 가공하는 역할이라고 보면 역할 분담이 좀 더 명확하게 보이는 것 같아요.
왜 FFN은 4배로 확장할까요?
일반적인 Transformer의 FFN 구조를 보면 이상한 점이 있습니다.
입력 차원이 512라면 FFN 내부에서 2048로 4배 확장했다가 다시 512로 줄어듭니다.
왜 굳이 부풀렸다가 다시 줄이는 걸까요?
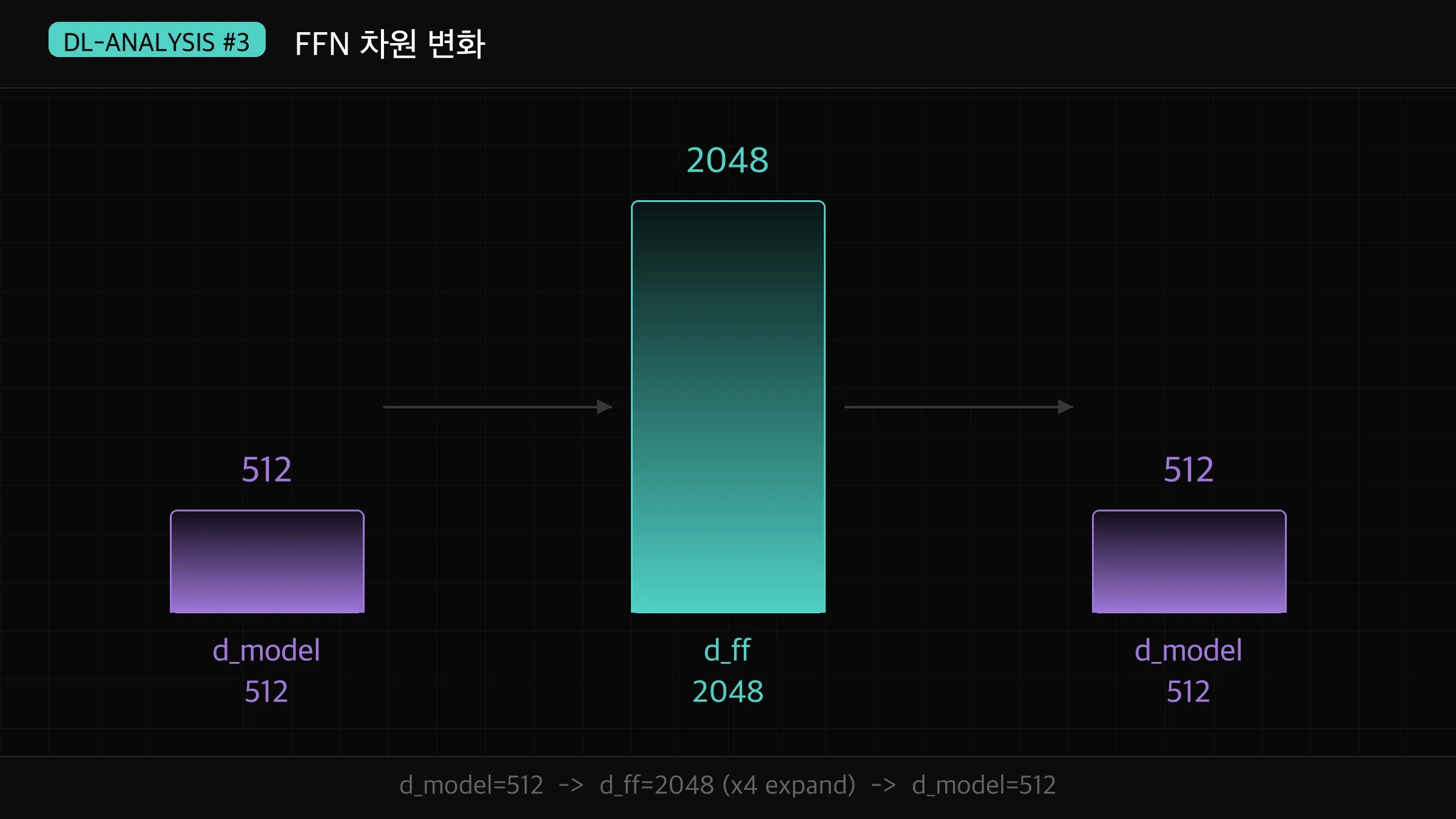
실제 모델 수치를 보면 이 패턴이 일관됩니다.
GPT-2 small은 d_model=768, d_ff=3072(4배)입니다.
GPT-3는 d_model=12288, d_ff=49152(4배)입니다.
거의 모든 Transformer 모델이 이 4배 확장을 따릅니다.
이 "확장-압축" 구조는 의도적 설계입니다.
- 더 많은 표현 공간: 4배 확장 구간에서 다양한 지식 패턴을 동시에 처리할 수 있습니다. 차원이 높을수록 더 많은 뉴런이 각자 다른 지식 조각을 담을 수 있습니다. (쉽게 말하면: 방이 넓을수록 더 많은 가구를 둘 수 있는 것처럼, 차원이 높을수록 더 많은 지식 패턴을 저장할 수 있습니다.)
- 비선형성 극대화: 높은 차원에서 활성화 함수를 적용하면 더 복잡한 패턴을 학습합니다. 저차원에서 비선형 변환을 하는 것보다 훨씬 표현력이 풍부합니다.
- 압축으로 일반화: 다시 원래 차원으로 줄이면서 핵심 정보만 남깁니다. 과잉 정보를 걸러내는 이 구조가 일반화 성능을 높입니다.
현대 LLM은 이 FFN 블록을 수십에서 수백 번 쌓습니다.
GPT-2 small은 12층, GPT-3는 96층, LLaMA-3 405B는 126층입니다.
각 층의 FFN이 서로 다른 수준의 지식을 처리하면서, 전체 모델이 방대한 지식을 저장하고 활용할 수 있게 됩니다.
Transformer 블록 안에서 MLP는 어디에 있을까요?
Transformer 블록 하나를 전체적으로 보면 이렇습니다.
Multi-Head Attention이 먼저 실행되고, Add&Norm을 거친 뒤,
FFN(MLP)이 뒤따라 실행되고, 다시 Add&Norm이 붙습니다.

Attention과 FFN은 서로 다른 역할을 담당합니다.
Attention은 "라우터" 역할입니다.
문장 안에서 어떤 단어 정보를 가져올지, 어떤 위치의 표현을 참조할지 결정합니다.
전체 시퀀스를 보면서 정보를 모아오는 과정입니다.
FFN은 "처리 및 저장" 역할입니다.
Attention이 모아온 정보를 뉴런 패턴으로 처리하고, 학습된 지식을 활용해서 출력을 만듭니다.
각 위치를 독립적으로 처리하기 때문에 시퀀스 전체를 볼 필요가 없습니다.
이 역할 분담이 Transformer를 강력하게 만드는 핵심입니다.
Attention은 문맥을 파악하는 데 집중하고, FFN은 지식을 활용하는 데 집중합니다.
둘이 반복해서 쌓이면서 점점 더 정교한 표현이 만들어집니다.
직접 실습해보려면
개념을 글로 읽는 것과 코드로 직접 돌려보는 건 전혀 다른 경험입니다.
아래 세 가지를 Jupyter Notebook에서 순서대로 해보면 MLP가 훨씬 구체적으로 느껴집니다.
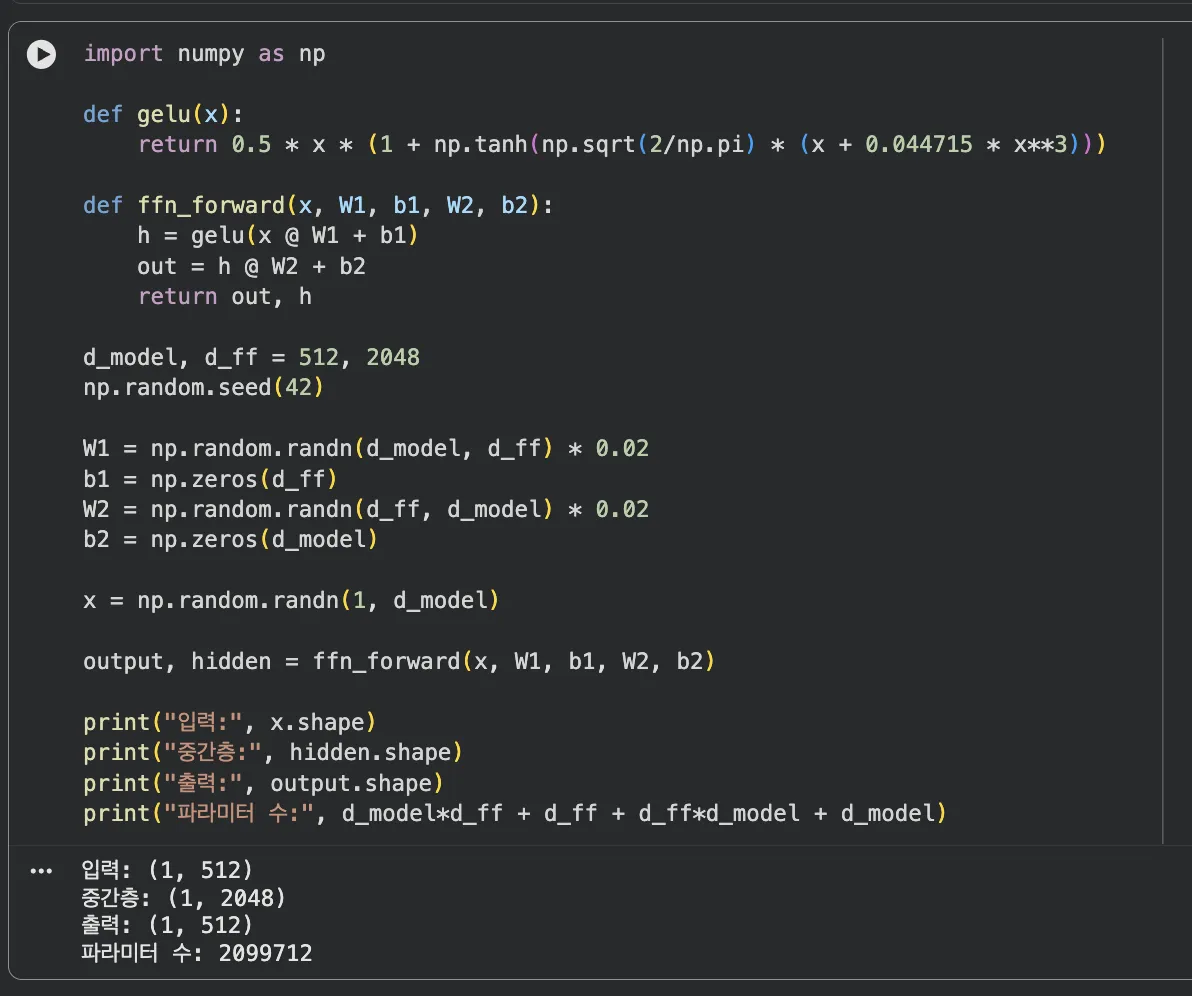
- 실습 1 — numpy로 FFN forward pass 구현: 입력 벡터 → W1 행렬 곱 → GELU 활성화 → W2 행렬 곱 → 출력 벡터. 이 흐름을 numpy로 직접 짜보면 FFN이 결국 "두 번의 행렬 곱 + 활성화 함수"임을 체감할 수 있습니다. d_model=512, d_ff=2048로 설정하고 shape를 찍어보세요.
- 실습 2 — 3D 뉴럴넷 시각화: matplotlib의 3D scatter + plot으로 레이어별 노드를 공간에 그리고, 레이어 간 엣지를 선으로 이어보면 "뉴럴넷이 왜 저렇게 생겼는지"가 직관적으로 잡힙니다. 노드 수와 레이어 수를 바꿔가며 시각화해보세요.
- 실습 3 — 활성화 함수 비교 차트: ReLU, GELU, SiLU를 같은 x 범위에서 그려서 겹쳐보면, 음수 구간에서의 차이가 얼마나 미묘한지 바로 보입니다.
scipy.special.erf로 GELU를 정확하게 계산할 수도 있습니다.
특히 실습 1에서 d_ff를 512(1배), 2048(4배), 8192(16배)로 바꿔가며 forward pass를 돌려보면,
"왜 4배 확장이 표준인가"에 대한 감을 직접 잡을 수 있습니다.
Jupyter 실행 결과 보기 — 파트 1: FFN forward pass 구현
Jupyter 실행 결과 보기 — 파트 2: 3D 뉴럴넷 시각화

Jupyter 실행 결과 보기 — 파트 3: 활성화 함수 비교 차트
딥러닝 분석 1~3편 정리
- Transformer: 전체 문장을 한 번에 보는 병렬 처리 아키텍처. RNN의 순차 처리 한계를 극복하고 GPU를 제대로 활용할 수 있게 했습니다.
- Attention: Q/K/V 행렬 연산으로 단어 관계를 포착하는 메커니즘. 거리에 관계없이 직접 연결하고, 히트맵으로 해석도 가능합니다.
- MLP(FFN): 뉴런 패턴으로 지식을 저장하는 키-밸류 메모리. 층마다 다른 수준의 지식을 담고, 4배 확장-압축 구조로 표현력을 극대화합니다.
GPT, BERT, LLaMA — 이름은 다 달라도 내부는 이 세 가지 구성요소의 반복입니다.
인코더만 쓰느냐, 디코더만 쓰느냐, 둘 다 쓰느냐의 차이는 있지만, 블록 하나의 구조는 Attention + FFN입니다.
수십에서 수백 번 쌓은 이 블록들이 수조 개의 텍스트를 학습하면서, 우리가 지금 쓰는 LLM이 됐습니다.
이제 "LLM이 어떻게 작동하나?"라는 질문에 코드 수준에서 답할 수 있게 됐습니다.
다음에 LLM 관련 논문이나 코드를 마주쳤을 때,
Attention 레이어가 뭘 하는지, FFN이 왜 그 자리에 있는지 바로 파악할 수 있을 겁니다.
그런데 LLM은 여기서 멈추지 않습니다.
텍스트만 처리하던 모델이 이미지, 음성까지 다룰 수 있게 확장됩니다.
스마트폰으로 음식 사진을 찍으면 칼로리를 알려주고, PDF 스캔에서 텍스트를 뽑아내는 것들이 그 결과입니다.
다음 4편에서는 LLM이 이미지를 인식하는 방법, VLM(Vision Language Model)을 다룹니다.