
[딥러닝 분석 4편] VLM — LLM이 이미지를 인식하는 방법
LLM이 텍스트 밖으로 나가는 이야기입니다. 스마트폰 카메라로 음식을 찍으면 칼로리를 알려주고, PDF 스캔 이미지에서 텍스트를 뽑아내는 게 어떻게 가능한 걸까요? 이미지 패치 토크나이징, ViT 구조, MLP Projector, 통합 시퀀스 처리까지 VLM 아키텍처 전체를 정리했습니다.
1~3편으로 LLM 내부 구조를 다뤘는데, 이번엔 밖으로 나가는 내용을 다뤄보려고 합니다.
LLM에서 음성, 이미지 등을 인식하면 다룰 수 있는 부분이 확장되어서 좋은 것 같습니다. ㅎㅎ
스마트폰이 음식 사진을 보고 칼로리를 계산한다?
VLM(Vision Language Model)은 이미지를 작은 패치로 쪼개서 텍스트 토큰처럼 취급한 뒤, 텍스트와 합쳐서 LLM에 넣는 방식으로 작동합니다. Vision Encoder가 이미지를 이해하고, MLP Projector가 시각 정보를 언어 공간으로 변환해서, LLM이 사진과 질문을 한꺼번에 처리할 수 있게 되는 거예요.
다이어트 앱에 오늘 먹은 비빔밥 사진을 찍으면 자동으로 칼로리를 알려줍니다.
책 표지를 카메라로 비추면 제목과 저자를 텍스트로 뽑아냅니다.
PDF 스캔 이미지에서 "이 계약서 몇 년 몇 월 날짜야?"라고 물으면 바로 찾아줍니다.
이게 어떻게 가능한 걸까요?
LLM은 원래 텍스트만 처리합니다.
그런데 이미지를 "텍스트처럼" 다루면 어떨까요?
그게 VLM(Vision Language Model)의 핵심 아이디어입니다.
이미지를 토큰으로 쪼개서, 텍스트 토큰과 함께 LLM에 넣는 겁니다.
(쉽게 말하면: "나는 학교에 간다"를 [나는, 학교에, 간다]로 쪼개듯, 이미지도 작은 조각으로 쪼개서 각 조각을 단어처럼 취급합니다.)
이미지를 토큰으로 만들려면 어떻게 패치를 분할할까요?
텍스트 토크나이징은 익숙합니다.
"나는 학교에 간다" → [나는, 학교에, 간다] 3개 토큰.
이미지는 어떻게 토큰으로 만들까요?
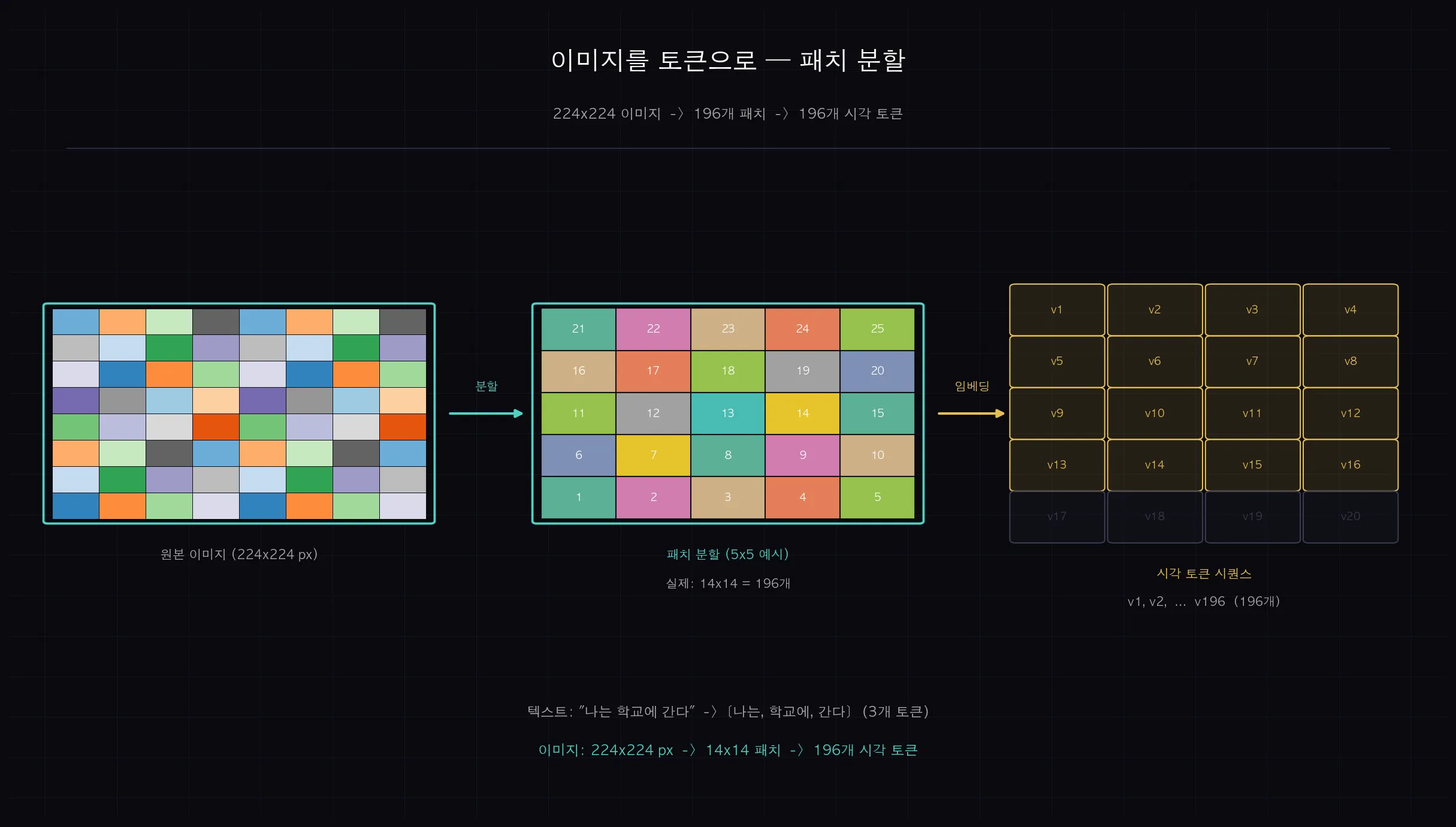
224×224 픽셀 이미지가 있다고 해봅시다.
이 이미지를 16×16 픽셀 크기의 작은 조각(패치)으로 잘라냅니다.
224÷16 = 14, 가로 14개, 세로 14개, 총 196개 패치가 나옵니다.
각 패치 하나가 시각 토큰 하나입니다.
196개 패치 = 196개 시각 토큰.
(쉽게 말하면: 이미지를 격자무늬로 잘라서, 각 격자 칸을 단어 하나처럼 취급하는 겁니다.)
해상도가 높을수록 토큰이 많아집니다.
고해상도 이미지일수록 더 세밀하게 쪼개져서 토큰이 많아지는 구조입니다.
이 방식을 Native Resolution이라고 하는데, 이미지 크기에 따라 토큰 수를 동적으로 조정합니다.
Vision Encoder — ViT는 패치를 어떻게 "이해"할까요?
196개 패치를 만들었는데, 이 패치들을 그냥 쭉 나열하면 될까요?
안 됩니다. 각 패치 사이의 관계를 파악해야 합니다.
왼쪽 상단 패치와 오른쪽 하단 패치가 어떻게 연결되는지 알아야 이미지를 "이해"할 수 있습니다.
여기서 ViT(Vision Transformer)가 등장합니다.
텍스트에서 Attention이 "나는"과 "학교"의 관계를 파악하듯,
ViT는 이미지 패치들 사이의 관계를 Attention으로 파악합니다.
(쉽게 말하면: 텍스트에서 단어들이 서로 얼마나 관련 있는지 파악하듯, 이미지에서는 패치들이 서로 얼마나 관련 있는지 파악합니다. 예를 들어 사람 얼굴 사진에서 눈 패치와 코 패치, 입 패치는 서로 강하게 연결됩니다.)
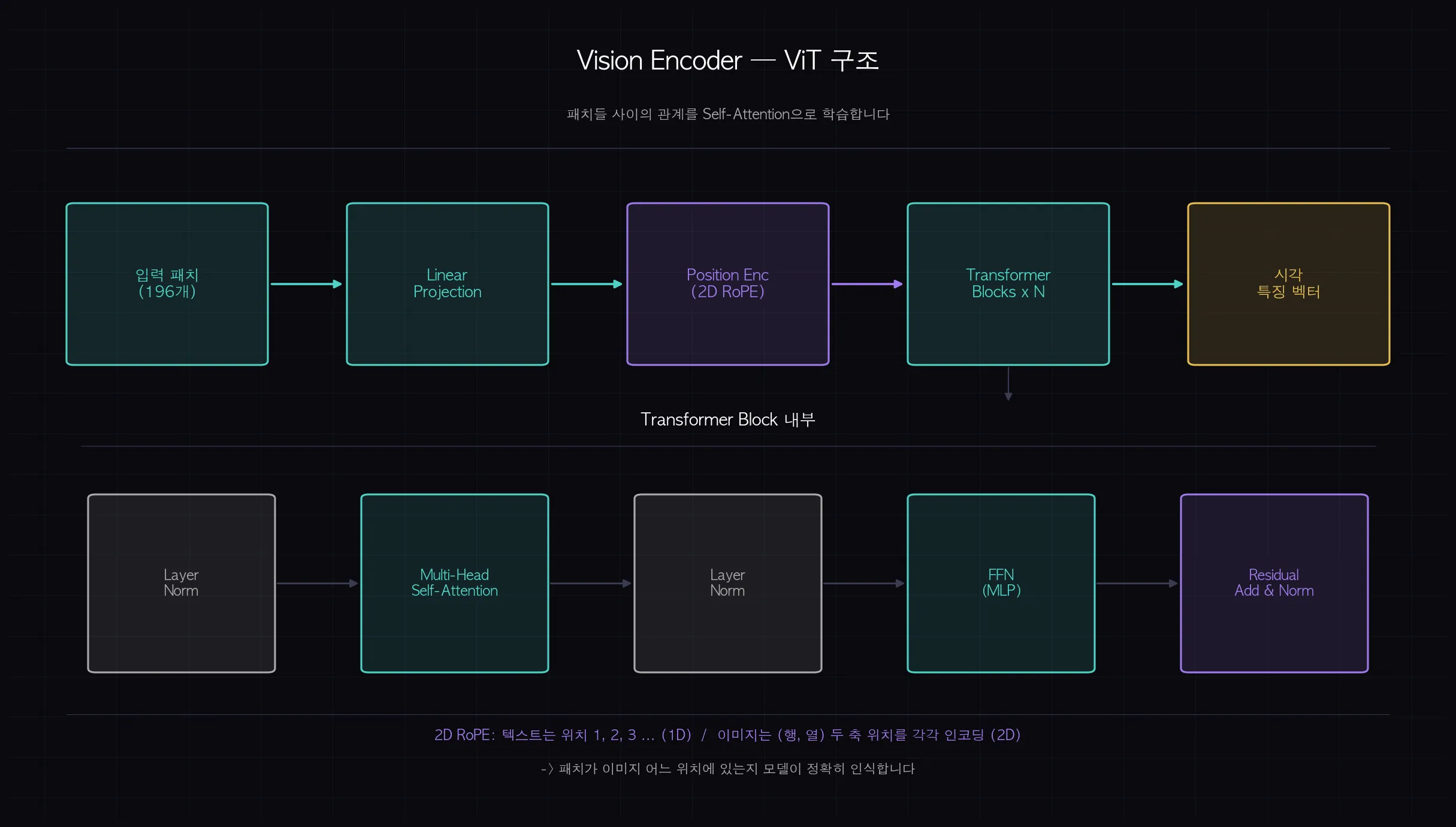
한 가지 다른 점이 있습니다. 위치 인코딩입니다.
텍스트는 1차원 순서가 있습니다. 1번 단어, 2번 단어, 3번 단어.
이미지는 2차원입니다. (행 3, 열 5)처럼 x, y 위치가 모두 필요합니다.
그래서 ViT는 2D RoPE(Rotary Position Embedding)를 사용합니다.
텍스트의 1D RoPE와 달리, 행 위치와 열 위치를 각각 인코딩합니다.
(쉽게 말하면: 텍스트는 "몇 번째 단어인지"만 알면 되지만, 이미지는 "몇 행, 몇 열에 있는 패치인지" 둘 다 알아야 합니다.)
요즘 주요 VLM 모델들(LLaVA, Qwen-VL, EXAONE 등)은 보통 300M~1.5B 파라미터 규모의 Vision Encoder를 사용하는 것 같습니다..!
이 Vision Encoder가 196개 패치를 받아서 각 패치의 시각 특징 벡터를 출력합니다.
입력: 196개 패치. 출력: 196개 시각 특징 벡터 (각각 1024차원).
MLP Projector — 이미지 세계와 언어 세계를 어떻게 연결할까요?
Vision Encoder가 196개 시각 특징 벡터를 만들었습니다.
이걸 그냥 LLM에 넣으면 될까요?
안 됩니다. 차원이 맞지 않습니다.
Vision Encoder 출력: 1024차원 벡터.
LLM 입력: 4096차원 벡터 (모델 크기마다 다름).
전혀 다른 공간에 있는 벡터입니다. 바로 연결하면 아무 의미가 없습니다.
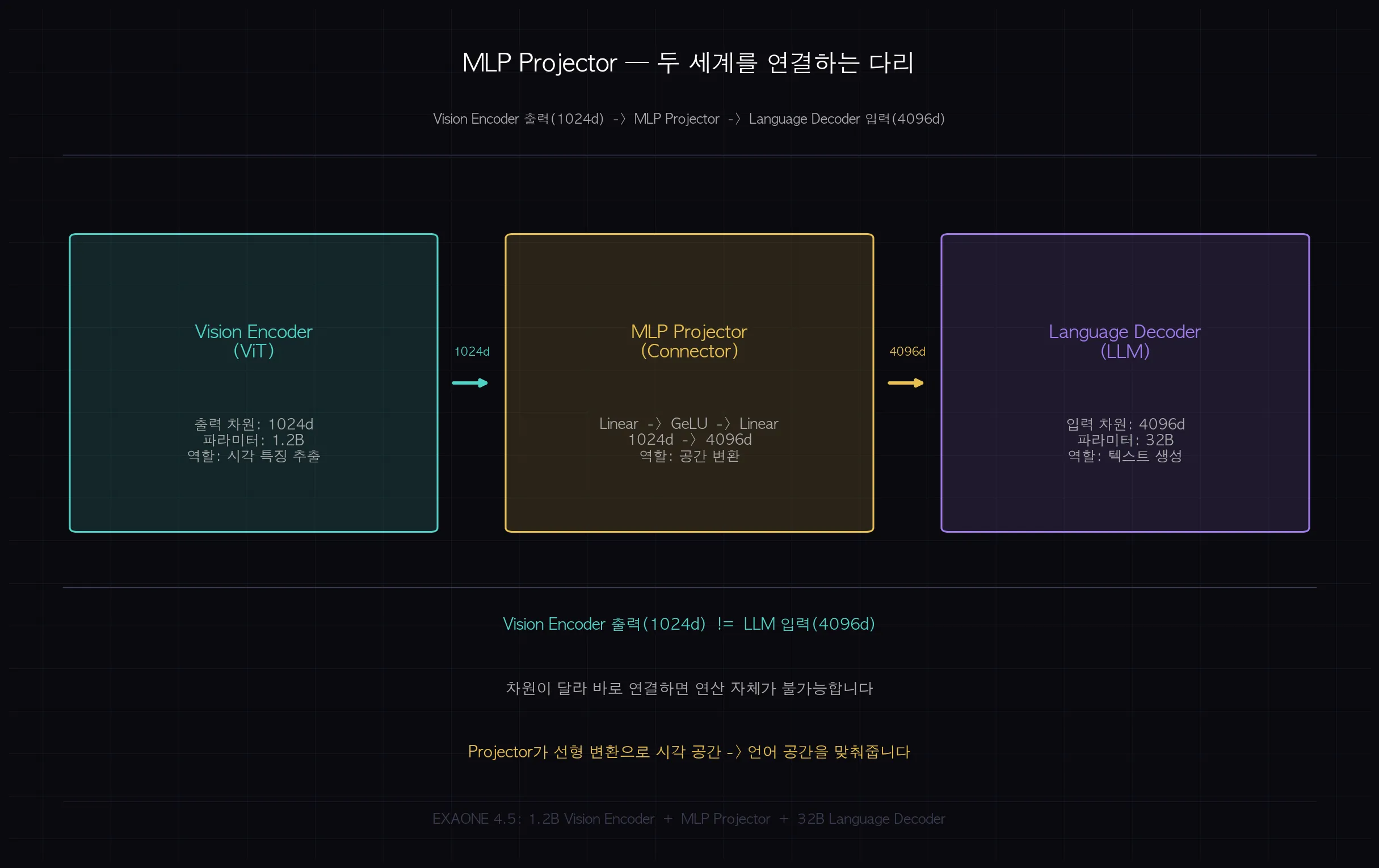
MLP Projector는 간단한 선형 변환 레이어입니다.
1024차원 시각 벡터를 받아서 4096차원 언어 벡터로 변환합니다.
이 Projector는 학습 과정에서 "어떻게 변환해야 LLM이 잘 이해하는지" 자동으로 배웁니다.
VLM을 접했을 때 Projector라는 단어가 생소했는데, 뜻 그대로 "투영하다"는 의미예요. 수학에서 한 공간의 벡터를 다른 공간으로 옮길 때 쓰는 표현입니다. 이미지 세계의 언어와 텍스트 세계의 언어가 서로 달라서, 통역사 역할을 하는 레이어가 중간에 필요하다고 생각하니까 왜 이 단계가 빠질 수 없는지 이해가 됐어요.
업계에서는 MLP Projector, MLP Connector, Visual Projector 등 다양한 이름을 씁니다.
모델마다 표기는 달라도 본질은 같습니다. 시각 공간 → 언어 공간 변환을 담당하는 MLP 레이어입니다.
좀 더 정교한 방식도 있습니다.
Vision Encoder의 마지막 레이어 출력만 쓰는 게 아니라, 중간 레이어 특징까지 함께 추출해서 융합하는 구조입니다.
저해상도 세부 정보까지 언어 모델에 전달할 수 있어서 복잡한 이미지 이해에 유리합니다.
왜 Projector가 필요한가?
시각 공간과 언어 공간은 전혀 다른 차원에 존재합니다.
(쉽게 말하면: 한국어 통역사가 영어를 한국어로 바꿔주듯, Projector가 이미지 공간의 벡터를 언어 모델 공간의 벡터로 변환해줍니다.)

기존 LLM 아키텍처는 어떤 구조일까요?
VLM을 이해하려면 기존 LLM 구조를 먼저 떠올려야 합니다.
텍스트 입력 → 토크나이저 → 임베딩 → Transformer 블록 반복 → 출력 토큰.
처음부터 끝까지 텍스트만 다루는 단일 파이프라인입니다.

VLM 아키텍처 — 이미지 트랙은 어떻게 추가될까요?
VLM은 텍스트 파이프라인에 이미지 파이프라인이 합류하는 구조입니다.
이미지 트랙: 이미지 입력 → 패치 분할 → Vision Encoder → MLP Projector → 시각 토큰.
텍스트 트랙: 텍스트 입력 → 토크나이저 → 텍스트 임베딩.
두 트랙이 합류해서 하나의 시퀀스가 되고, 그 다음부터 LLM이 처리합니다.
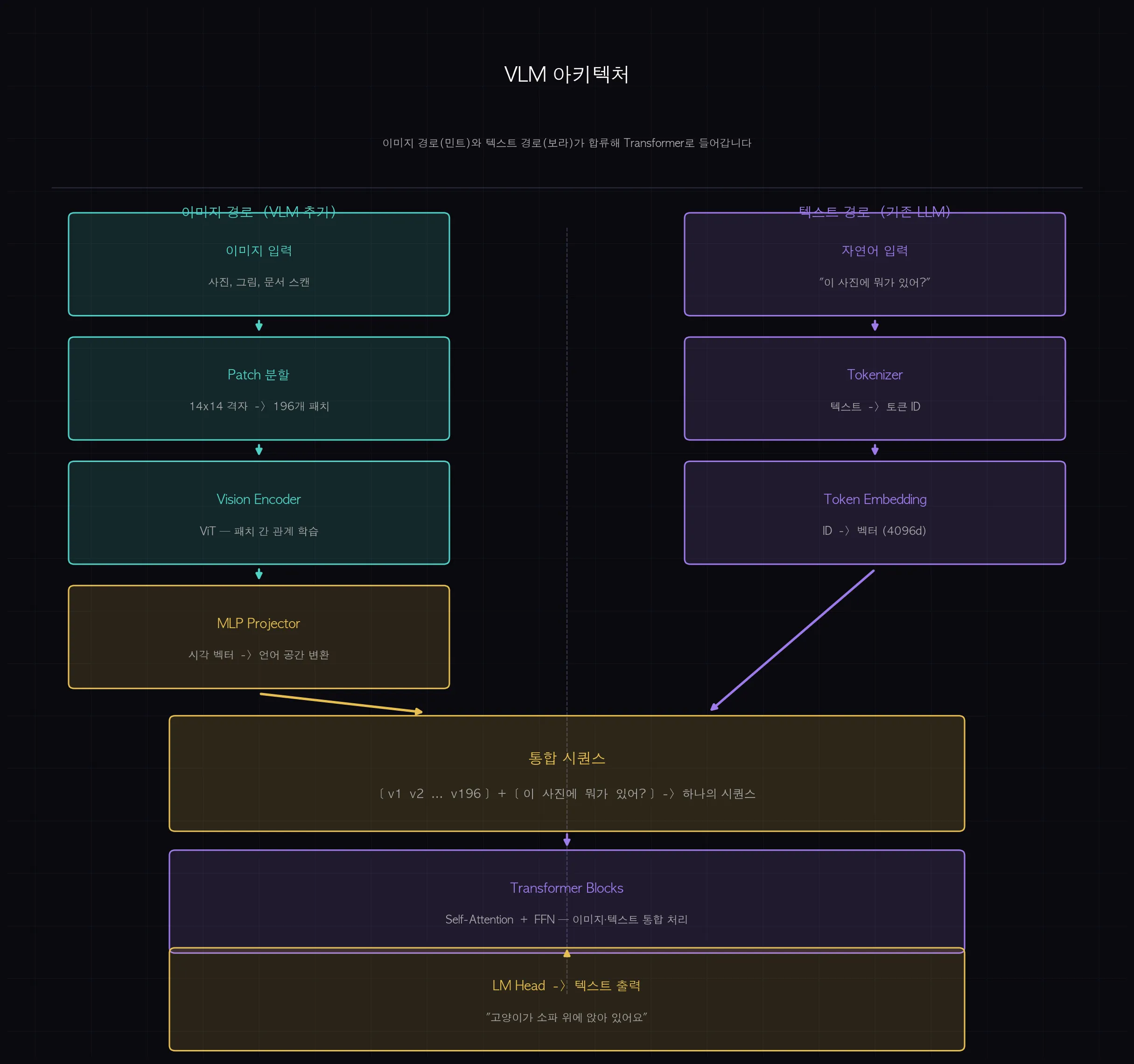
Language Decoder — 이미지와 텍스트를 어떻게 하나의 시퀀스로 처리할까요?
MLP Projector를 거친 시각 토큰과 텍스트 토큰이 하나의 시퀀스로 합쳐집니다.
"이 사진에 뭐가 있어?"라는 질문을 처리한다고 해봅시다.
시퀀스는 이렇게 구성됩니다.
[v1, v2, v3, ..., v196, "이", "사진에", "뭐가", "있어", "?"]
앞쪽 196개는 시각 토큰, 뒤쪽은 텍스트 토큰입니다.
LLM은 이 전체 시퀀스를 하나로 보고 Attention을 계산합니다.
(쉽게 말하면: 텍스트 "뭐가"가 시각 토큰 v47(고양이 패치)에 주목하면서 "고양이가 있다"는 답변을 생성하는 식입니다.)
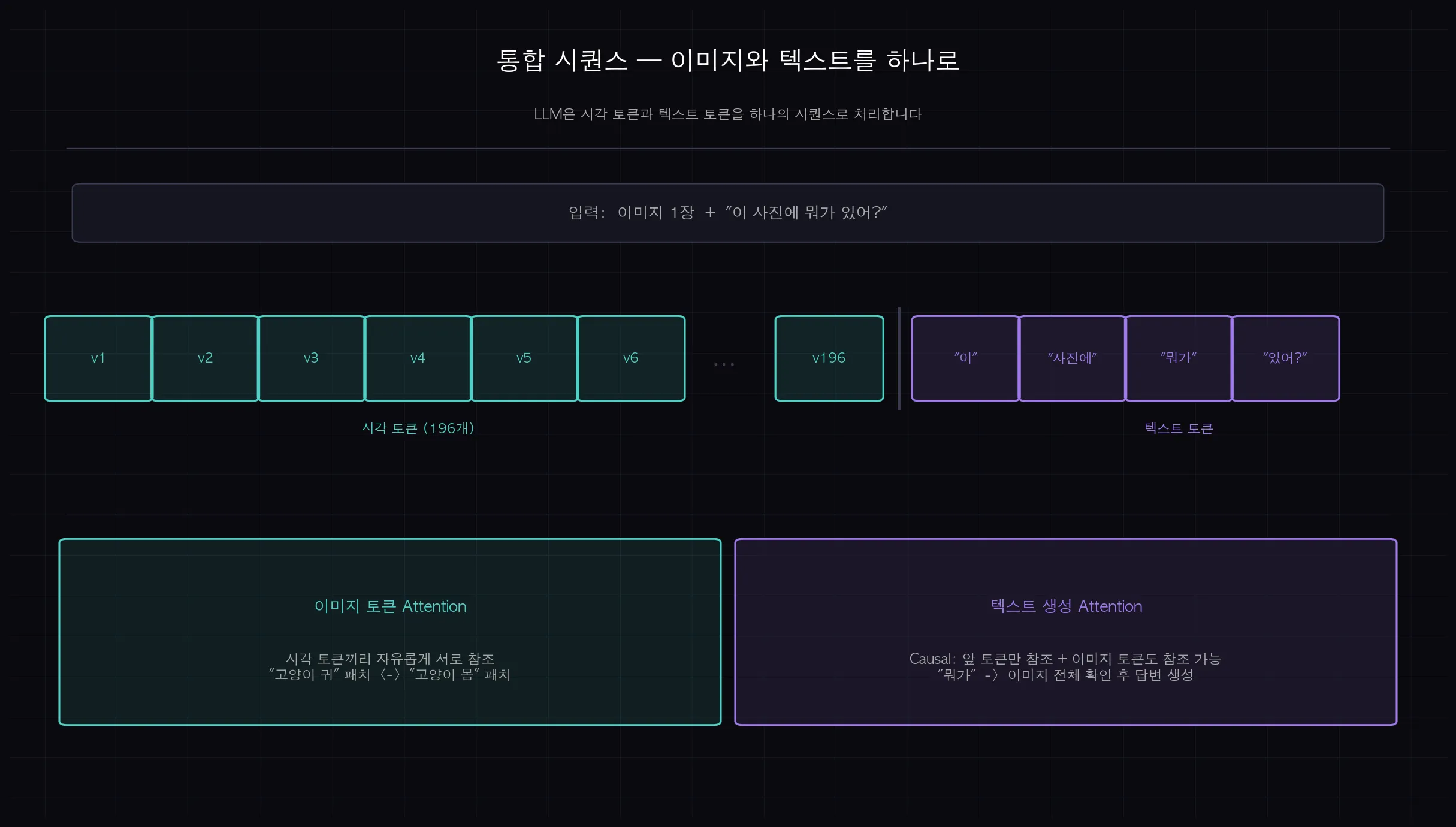
Attention 처리 방식도 텍스트와 약간 다릅니다.
이미지 토큰들은 서로 자유롭게 참조할 수 있습니다. (Bidirectional)
텍스트 토큰은 앞 방향만 참조합니다. (Causal / Autoregressive)
이미지는 한 번에 다 주어지는 정보이고, 텍스트는 순서가 있는 생성 과정이기 때문입니다.
일부 VLM은 여기서 추론 토큰(Reasoning Token) 방식을 추가로 사용하기도 합니다.
LLM이 최종 답변을 생성하기 전에 내부적으로 추론 과정을 거치도록 하는 학습 가능 토큰입니다.
"이미지를 보고 → 생각하고 → 답변한다"는 흐름을 명시적으로 학습시키는 방식입니다.
(쉽게 말하면: 시험 답을 바로 쓰는 게 아니라 먼저 풀이 과정을 적고 나서 최종 답을 쓰도록 훈련하는 것과 비슷합니다.)
VLM 전체 파이프라인 정리
처음부터 끝까지 정리하면 이렇습니다.
- 이미지 입력: 224×224 픽셀 이미지 (또는 다양한 해상도)
- 패치 분할: 16×16 패치로 분할 → 196개 패치 (= 196개 시각 토큰)
- Vision Encoder (ViT): 196개 패치 → 196개 시각 특징 벡터 (1024d), 2D RoPE로 위치 인코딩
- MLP Projector: 1024d 시각 벡터 → 4096d 언어 벡터로 공간 변환
- 통합 시퀀스: [196개 시각 토큰] + [텍스트 토큰] 합치기
- Language Decoder: 통합 시퀀스를 Transformer 블록으로 처리 → 텍스트 출력 생성
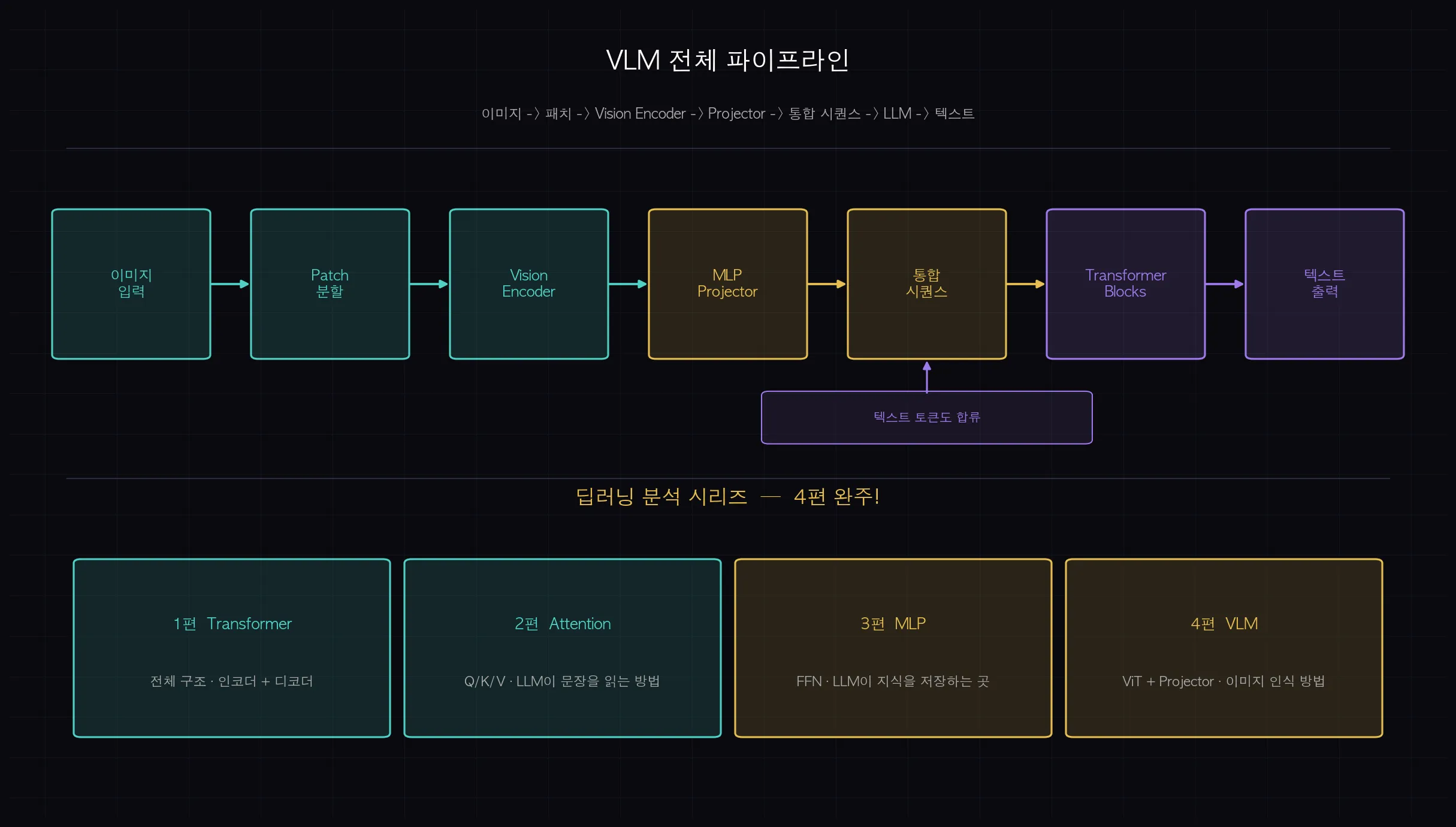
이 구조가 EXAONE 4.5, LLaVA, GPT-4V, Gemini 같은 현대 VLM 모델들의 공통 골격입니다.
모델마다 Vision Encoder 크기, Projector 설계, 학습 데이터가 다르지만,
"이미지를 토큰으로 변환 → 텍스트와 합쳐서 LLM에 넣는다"는 흐름은 동일합니다.
직접 실습해보려면
아래 세 가지를 Jupyter에서 해보면 VLM의 각 단계가 구체적으로 잡힙니다.
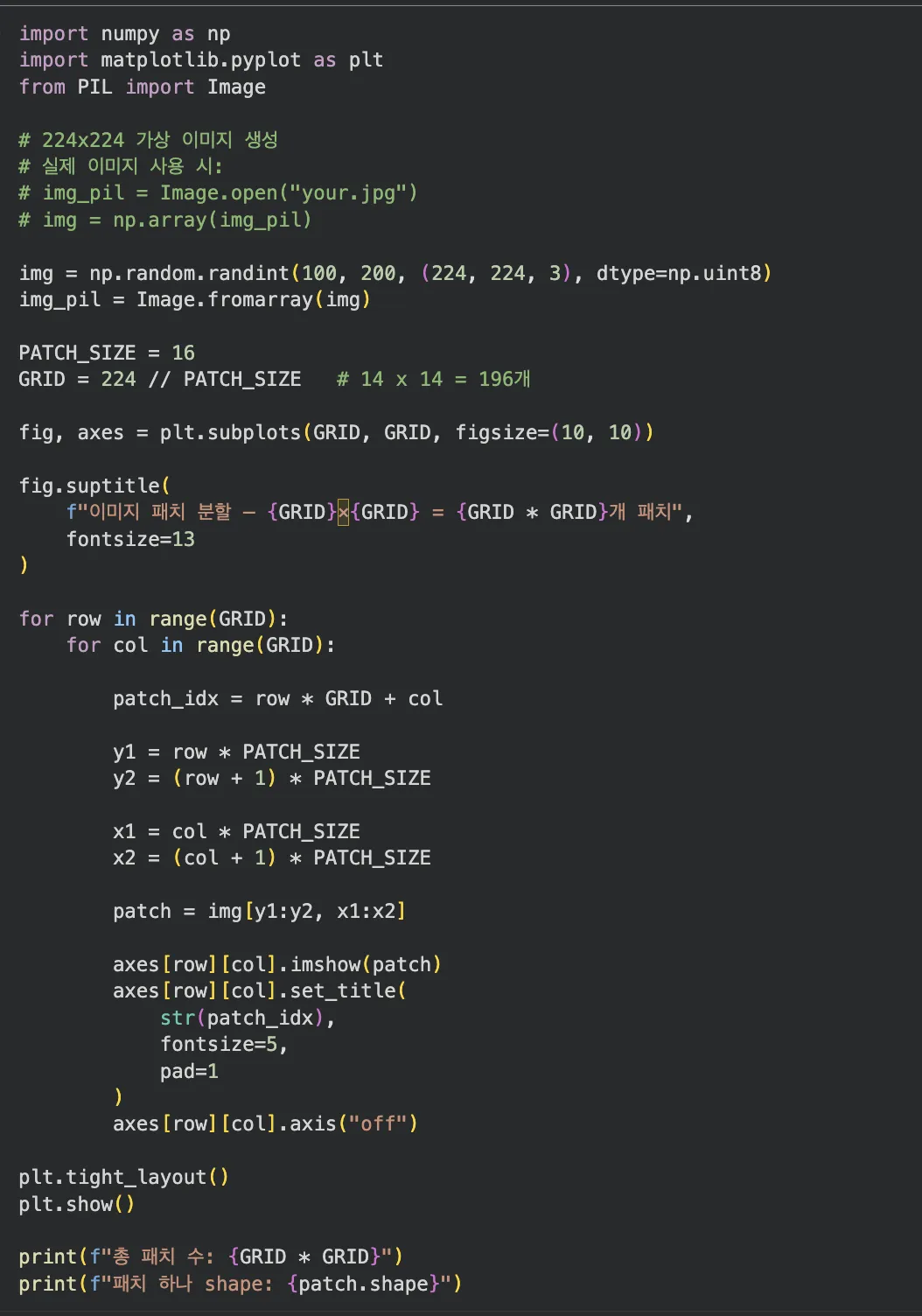
- 실습 1 — 이미지 패치 분할 시각화: PIL로 이미지 로드 후 14×14 격자로 분할하고, 각 패치에 번호를 붙여서 시각화. "196개 토큰"이 어디서 나오는지 직접 확인할 수 있습니다.
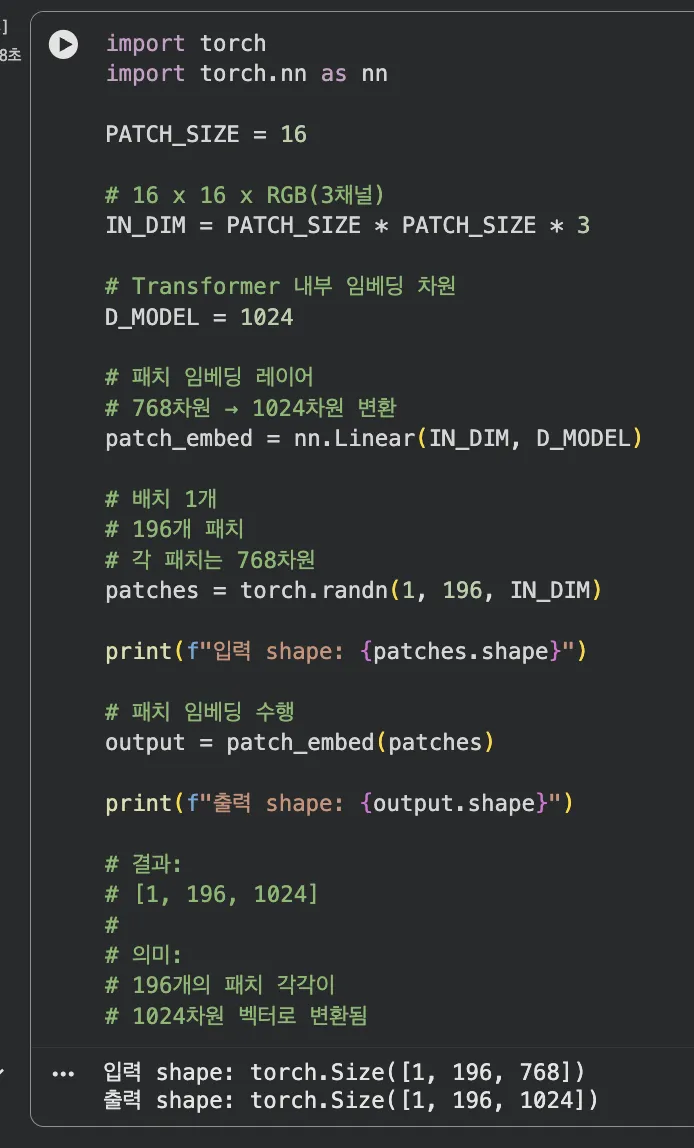
- 실습 2 — 간단한 ViT 패치 임베딩 구현: PyTorch로 16×16 패치를 1024차원 벡터로 임베딩하는 선형 레이어 구현.
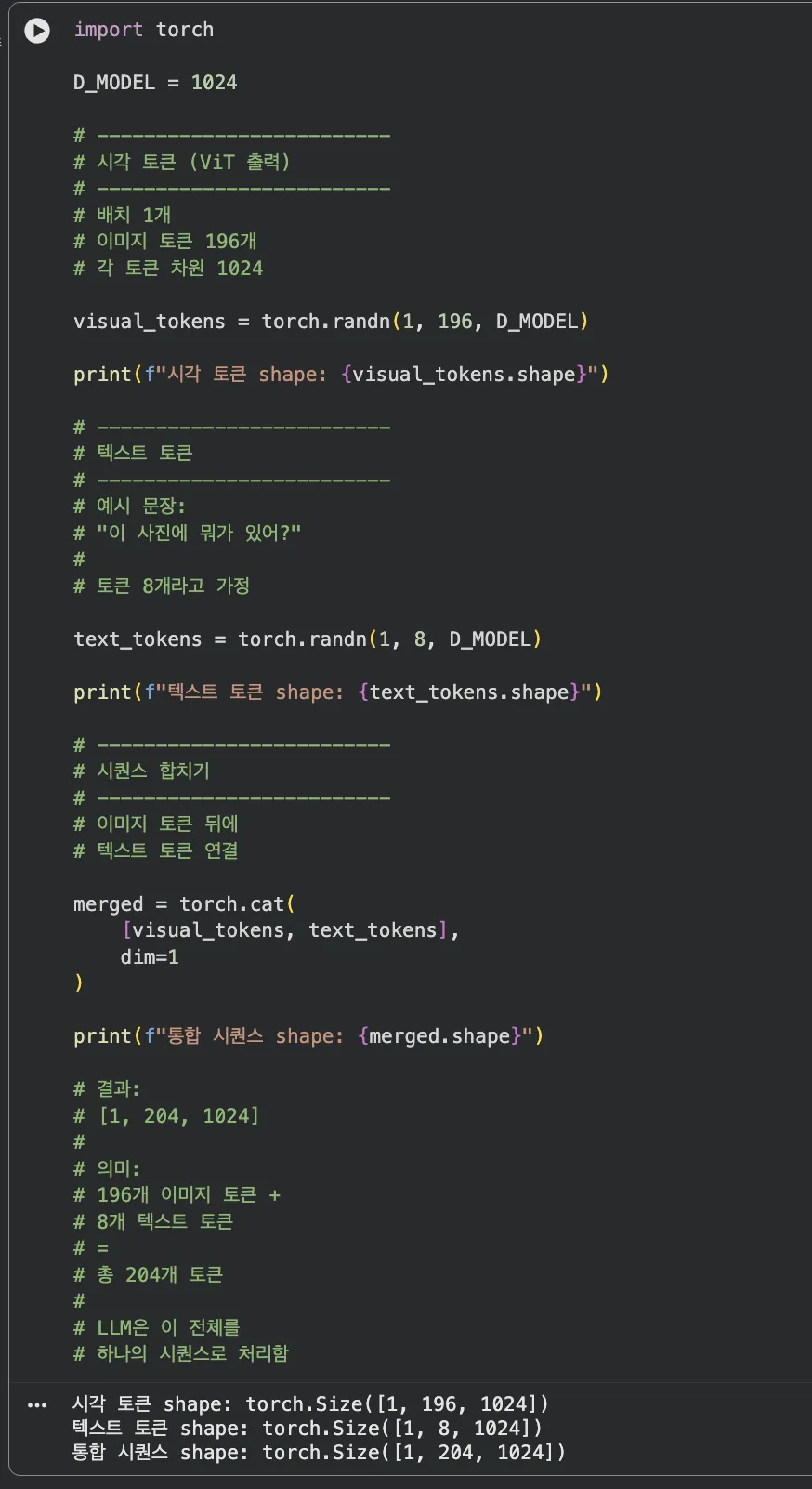
nn.Linear(16*16*3, 1024)가 패치 임베딩의 본질입니다. - 실습 3 — 텍스트+이미지 토큰 시퀀스 합치기: 196개 시각 토큰 텐서와 텍스트 토큰 텐서를
torch.cat으로 concat하는 시뮬레이션. shape 변화를 찍어보면 통합 시퀀스 구조가 바로 보입니다.
Jupyter 실행 결과 보기 — 파트 1: 이미지 패치 분할 시각화

Jupyter 실행 결과 보기 — 파트 2: ViT 패치 임베딩 구현
Jupyter 실행 결과 보기 — 파트 3: 텍스트+이미지 시퀀스 합치기
정리
- 이미지 토크나이징: 이미지를 16×16 패치로 분할해서 각 패치를 시각 토큰으로 변환합니다. 224×224 이미지 → 196개 시각 토큰.
- Vision Encoder (ViT): 패치들 사이의 관계를 Attention으로 파악합니다. 2D RoPE로 x, y 위치를 인코딩하는 점이 텍스트 처리와 다릅니다.
- MLP Projector: 시각 공간(1024d)과 언어 공간(4096d)이 달라서 선형 변환 레이어로 연결합니다. 통역사 역할입니다.
- 통합 시퀀스 처리: 시각 토큰 + 텍스트 토큰을 하나의 시퀀스로 합쳐서 LLM이 처리합니다. Causal Attention으로 텍스트를 자동 회귀 방식으로 생성합니다.
1~3편에서 LLM 내부 구조를 다뤘고, 4편에서 LLM이 이미지로 확장되는 원리를 봤습니다.
텍스트, 이미지를 통합 처리하는 멀티모달 모델의 핵심은 결국 "이미지를 텍스트처럼 다루는 것"입니다.
이 구조 위에 오디오, 비디오가 추가되면 진정한 멀티모달 모델이 됩니다.
4편까지는 이미지를 인식하는 방향이었습니다. 다음 5편은 반대 방향입니다.
노이즈에서 이미지를 만들어내는 Diffusion 원리와, U-Net을 Transformer로 교체한 DiT를 다룹니다.
미드저니, Stable Diffusion, FLUX.1이 어떤 구조인지 5편에서 이어집니다.