
[딥러닝 분석 5편] DiT — 이미지를 생성하는 Transformer
4편에서 LLM이 이미지를 '인식'하는 방법을 봤습니다. 5편은 반대 방향입니다. 노이즈에서 이미지를 만들어내는 Diffusion의 원리, U-Net을 Transformer로 교체한 DiT, VAE 잠재 공간, adaLN Timestep 주입, 텍스트 Cross-Attention, 그리고 FLUX.1과 Sora까지 정리했습니다.
미드저니, FLUX, Stable Diffusion에 "석양 아래 고양이"라고 입력하면 사진처럼 실제감 있는 그림이 나옵니다.
어떻게 텍스트 몇 글자로 이미지를 만들어낼 수 있는 건지 초기에 나왔을 땐 진짜 마법같았습니다...ㅎㅎ
4편은 이미지를 읽는 방법(VLM)이었습니다. 5편은 반대 방향입니다. 이미지를 만드는 방법입니다.
핵심 질문은 하나입니다. "노이즈에서 그림이 나온다는 게 무슨 의미인가요?"
(쉽게 말하면: 노이즈란 픽셀 값이 완전히 무작위로 섞인 상태입니다. TV 화면에서 채널이 없을 때 보이는 "지직거리는 화면"이 순수 노이즈에 가깝습니다. Diffusion 모델은 이 상태에서 시작해서 조금씩 노이즈를 제거하면서 원하는 이미지를 만들어냅니다.)
완전한 노이즈에서 어떻게 이미지를 복원할까요?
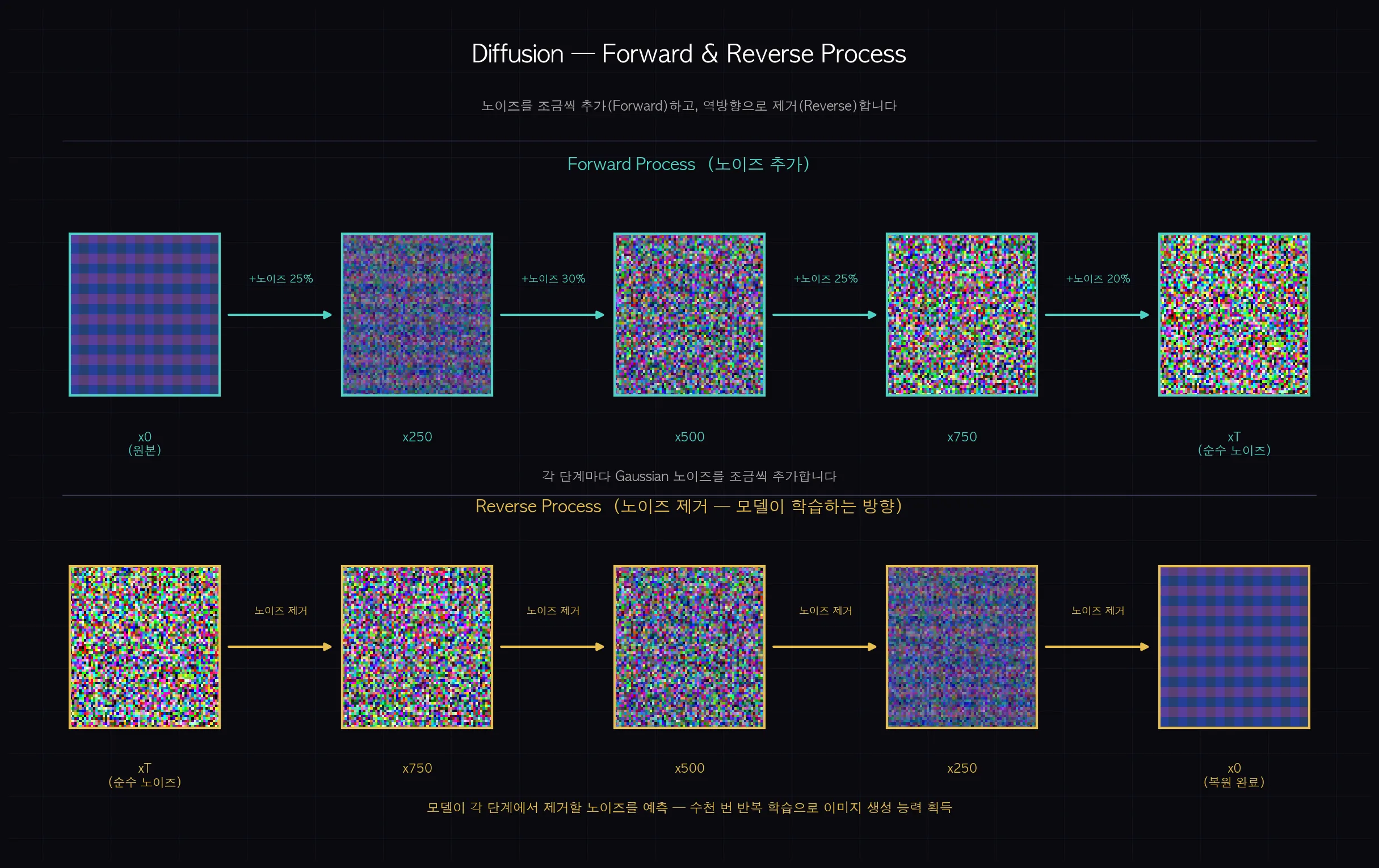
Diffusion 모델은 Forward Process로 이미지에 노이즈를 점진적으로 추가하고, Reverse Process로 노이즈를 단계별로 제거해서 이미지를 만들어냅니다. 모델이 학습하는 건 "현재 노이즈 상태에서 어떤 노이즈를 제거해야 하는가"이고, 이걸 1000단계에 걸쳐 반복하면 순수 노이즈가 선명한 이미지로 바뀌는 거예요.
Diffusion 모델의 핵심은 두 과정입니다. Forward Process와 Reverse Process입니다.
Forward Process: 원본 이미지에 Gaussian 노이즈를 조금씩 추가합니다. 단계를 반복하면 결국 순수 노이즈 상태가 됩니다.
Reverse Process: 반대로 순수 노이즈에서 시작해서 각 단계마다 노이즈를 조금씩 제거합니다. 충분히 반복하면 원본 이미지가 복원됩니다.
(쉽게 말하면: 사진에 모래폭풍 필터를 1%씩 1000번 올리면 결국 아무것도 안 보이는 노이즈가 됩니다. 역방향으로 되감으면 사진이 나옵니다. 모델이 학습하는 것은 "이 노이즈 상태에서 다음 단계는 어떤 노이즈를 제거해야 하는가"입니다.)
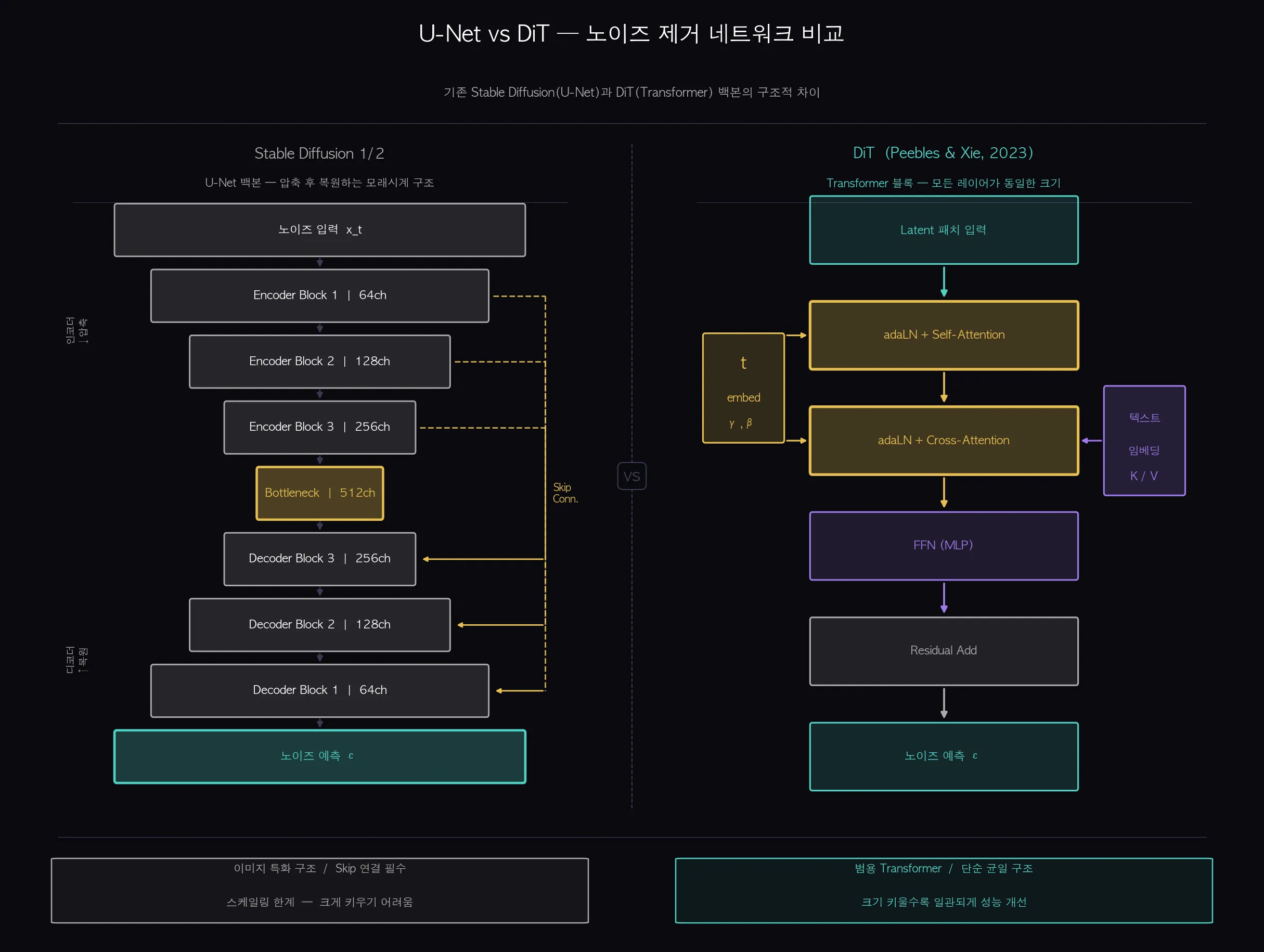
왜 U-Net을 썼고, DiT는 왜 Transformer로 바꿨을까요?
초기 Stable Diffusion(1/2 버전)은 Reverse Process를 담당하는 네트워크로 U-Net을 사용했습니다.
U-Net은 이미지 분할(Segmentation) 분야에서 검증된 구조로, 인코더와 디코더 사이에 Skip Connection이 있어서 이미지 세부 정보를 잘 보존합니다.
그런데 U-Net에는 한계가 있었습니다. 모델 크기를 키울수록 성능이 일관되게 향상되지 않았습니다.
GPT, LLaMA처럼 크기를 키우면 예측 가능하게 성능이 좋아지는 Transformer의 스케일링 법칙을 따르지 못했습니다.
2023년 Peebles & Xie가 발표한 DiT(Diffusion Transformer)는 U-Net을 Transformer로 교체했습니다.
결과는 명확했습니다. 크기를 키울수록 FID(생성 품질 지표)가 일관되게 개선됐습니다.
(쉽게 말하면: 특화된 이미지 도구(U-Net) 대신 범용 도구(Transformer)로 바꿨더니 오히려 더 잘 됐습니다. "텍스트에서 통한 방법이 이미지에서도 통한다"는 원리가 확인된 것입니다.)
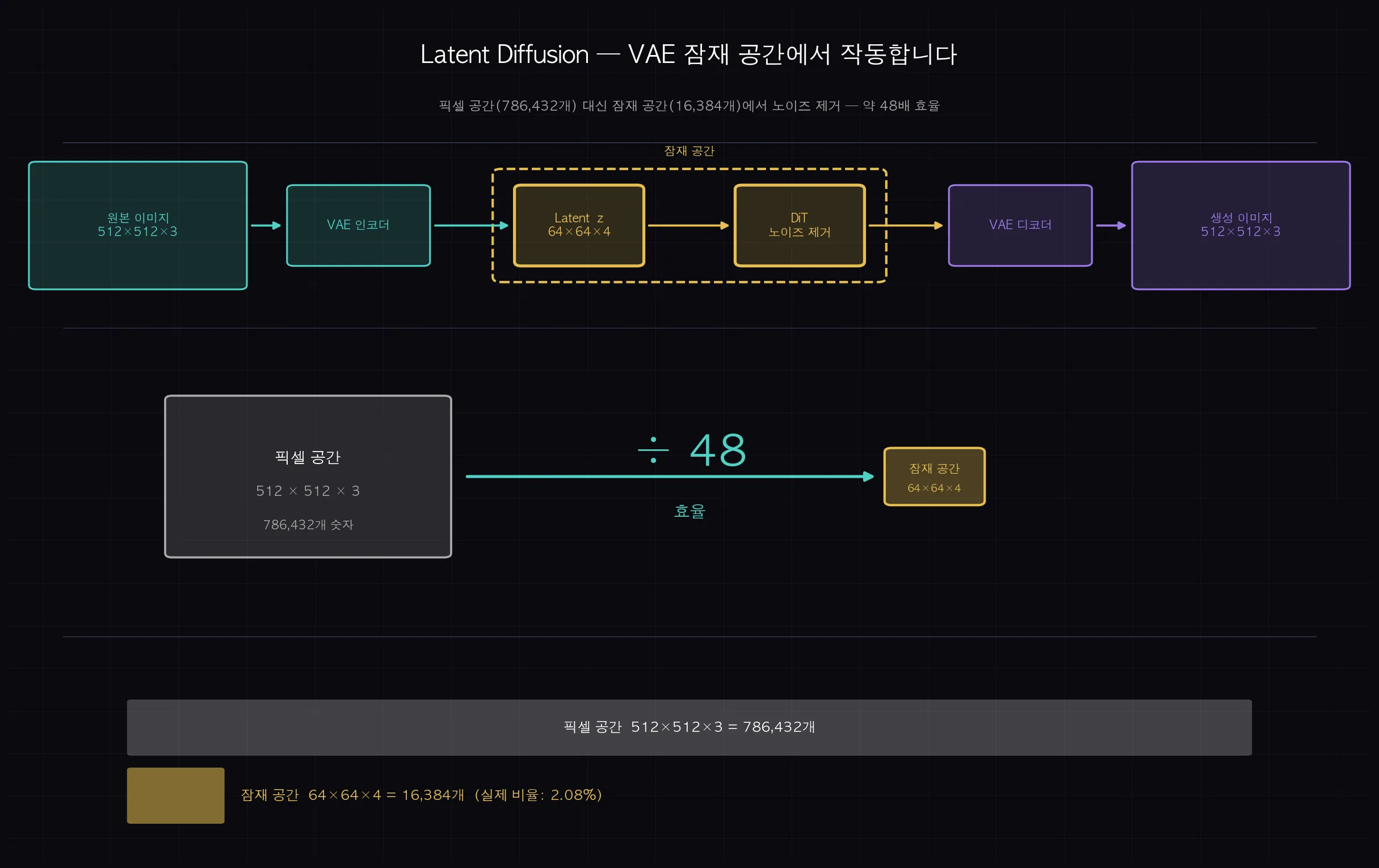
픽셀 공간 말고 Latent 공간에서 처리하면 뭐가 달라질까요?
512×512 이미지를 픽셀 단위로 처리하면 786,432개의 숫자를 다뤄야 합니다. 이걸 1000단계 반복하면 계산량이 너무 큽니다.
그래서 Latent Diffusion 방식이 등장했습니다. 픽셀이 아닌 잠재 공간(Latent Space)에서 노이즈를 추가하고 제거합니다.
핵심은 VAE(Variational Autoencoder)입니다.
- VAE 인코더: 512×512×3 이미지 → 64×64×4 잠재 벡터로 압축 (786,432개 → 16,384개)
- DiT: 압축된 잠재 공간에서 1000단계 노이즈 제거 수행
- VAE 디코더: 64×64×4 잠재 벡터 → 다시 512×512×3 이미지로 복원
약 48배 계산량 감소입니다. 고해상도 이미지 생성이 현실적으로 가능해진 이유입니다.
(쉽게 말하면: A4 문서를 원본 그대로 편집하기 어려울 때 압축 파일(.zip)로 만들어서 편집하고 다시 압축 해제하는 것과 같습니다. 핵심 정보는 유지하면서 처리 용량을 크게 줄입니다.)
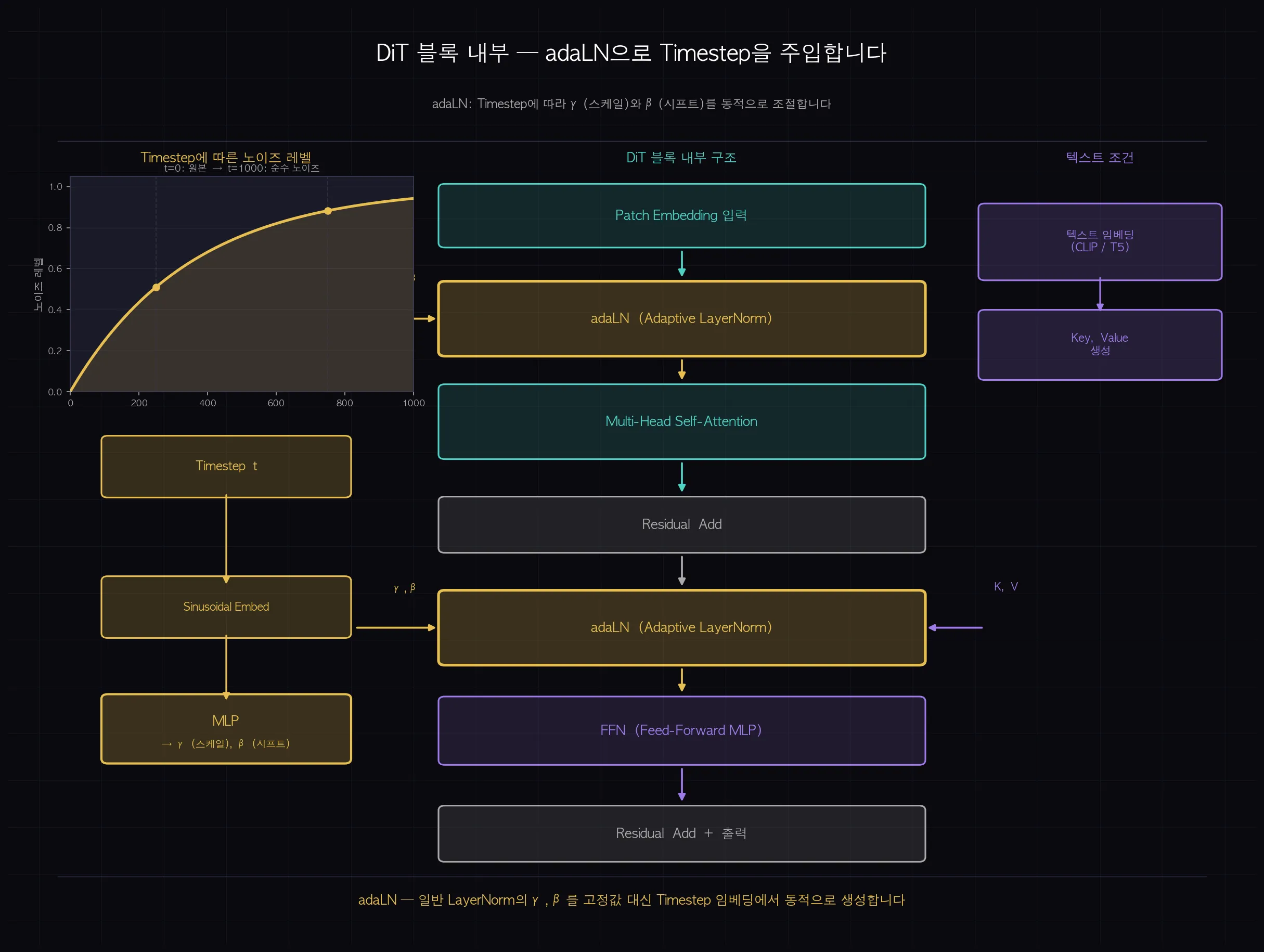
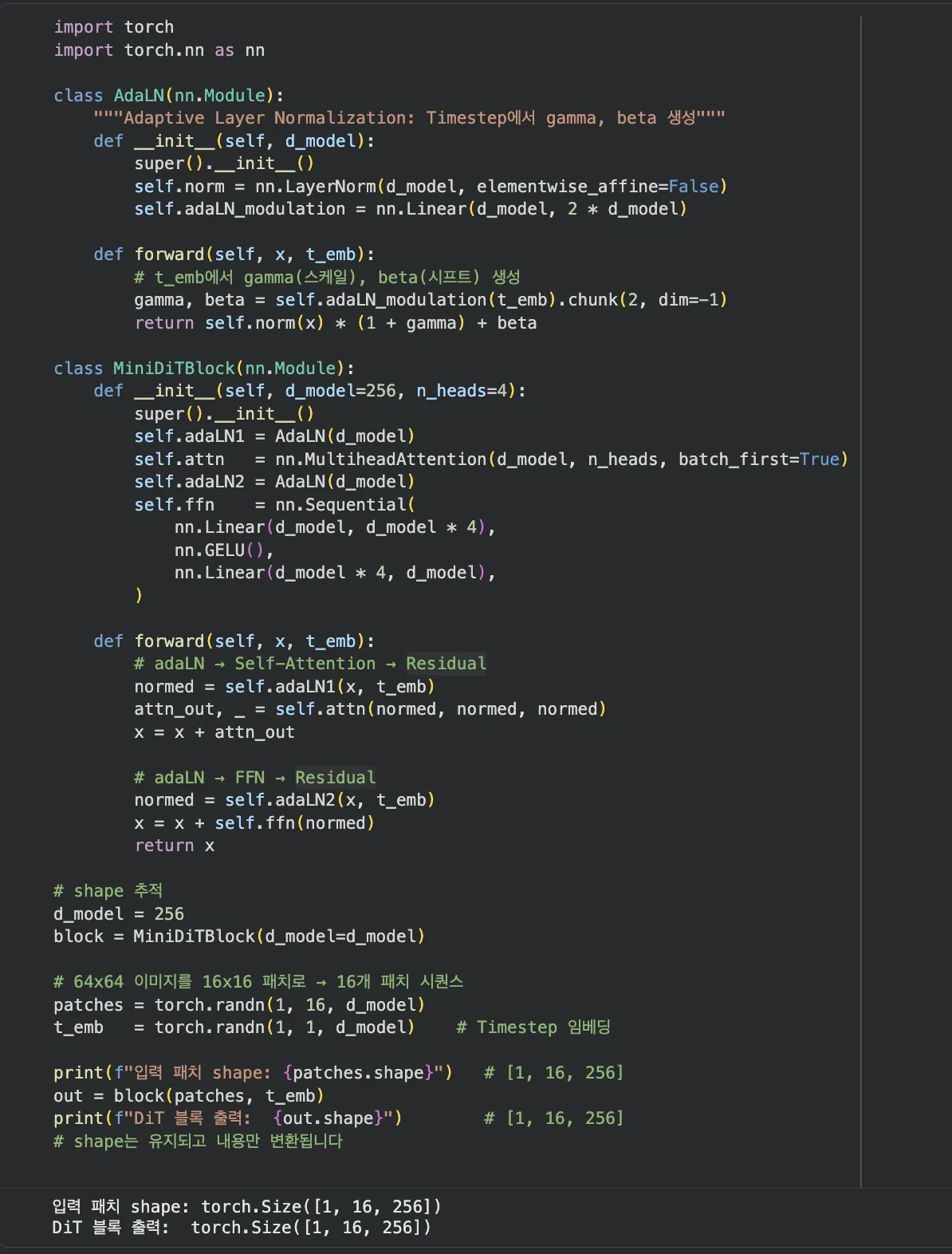
DiT 블록 내부 — Timestep은 어떻게 조건으로 들어갈까요?
Reverse Process는 1000단계를 거칩니다. 각 단계마다 "지금 몇 번째 단계인가"를 모델이 알아야 합니다.
단계 번호를 Timestep t라고 부릅니다. 이 정보를 모델에 주입하는 방법이 adaLN(Adaptive Layer Normalization)입니다.
처리 흐름은 이렇습니다.
- Timestep t를 Sinusoidal Embedding으로 벡터화합니다. (4편의 위치 인코딩과 동일한 원리)
- MLP로 γ(스케일)와 β(시프트) 두 값을 생성합니다.
- Layer Normalization 단계에서 고정 파라미터 대신 이 γ, β를 동적으로 적용합니다.
일반 LayerNorm이 "항상 같은 방식으로 정규화"한다면, adaLN은 "현재 노이즈 단계에 맞게 정규화 방식을 조정"합니다.
(쉽게 말하면: "지금 90% 노이즈 상태야"라고 알려주면 모델이 그 상태에 맞는 처리 방식을 선택합니다. 처음 단계(거의 순수 노이즈)와 마지막 단계(세부 디테일 조정)는 다른 방식으로 처리해야 하기 때문입니다.)
adaLN이라는 약어를 처음 봤을 때 이름만으로는 감이 잘 안 왔는데요. Adaptive는 "상황에 맞게 적응한다"는 뜻이고, Layer Normalization은 각 레이어 내부의 값 분포를 고르게 맞추는 기법이에요. 결국 고정된 방식으로 정규화하는 게 아니라, 지금 노이즈가 얼마나 남아있느냐에 따라 정규화 방식이 바뀐다는 거예요. 이름이 기능을 설명하고 있더라고요.
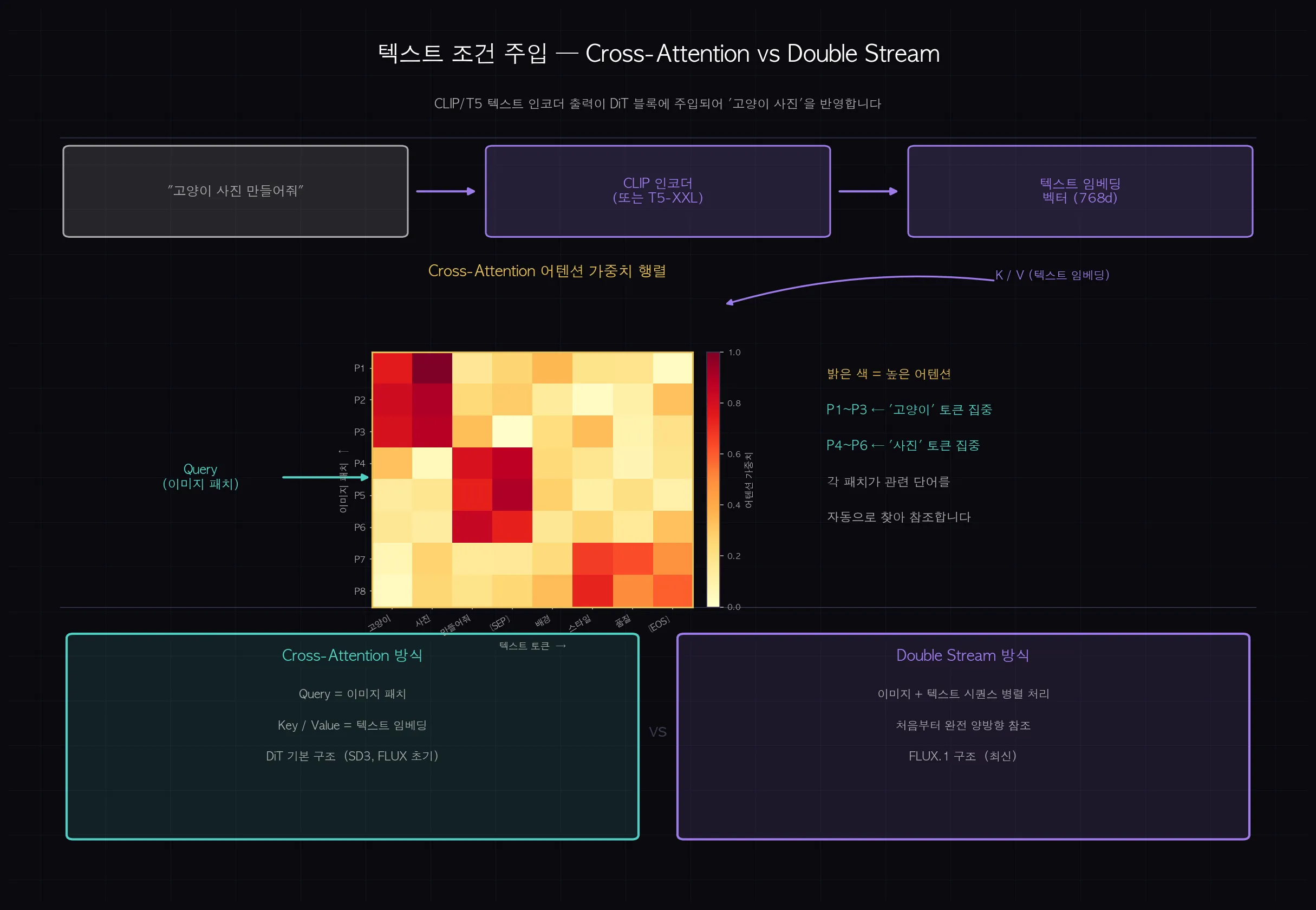
텍스트 조건 주입 — '고양이 사진'을 어떻게 반영할까요?
"석양 아래 고양이"라는 텍스트가 이미지 생성에 반영되는 과정을 살펴봅니다.
- 텍스트 인코딩: CLIP 또는 T5 텍스트 인코더가 입력 텍스트를 768차원 숫자 배열(벡터)로 변환합니다. "고양이"라는 단어가 768개의 숫자로 표현되는 것입니다.
- Cross-Attention 주입: DiT 블록 내부에서 이미지 패치가 Query, 텍스트 임베딩이 Key/Value 역할을 합니다.
- 결과: 각 이미지 패치가 텍스트 설명 중 어느 부분을 참조할지 학습합니다. "고양이" 영역은 고양이 관련 텍스트를, "석양" 영역은 석양 관련 텍스트를 참조합니다.
FLUX.1은 더 나아가 Double Stream 방식을 사용합니다.
이미지 패치 시퀀스와 텍스트 시퀀스를 처음부터 병렬로 처리해서 양방향 참조가 가능합니다.
(쉽게 말하면: 화가가 그림을 그리는 매 순간 지시서를 참조하는 것과 같습니다. 전체 그림의 방향을 잡을 때도, 세부 색상을 결정할 때도 "석양 아래 고양이"라는 지시서를 계속 확인합니다.)
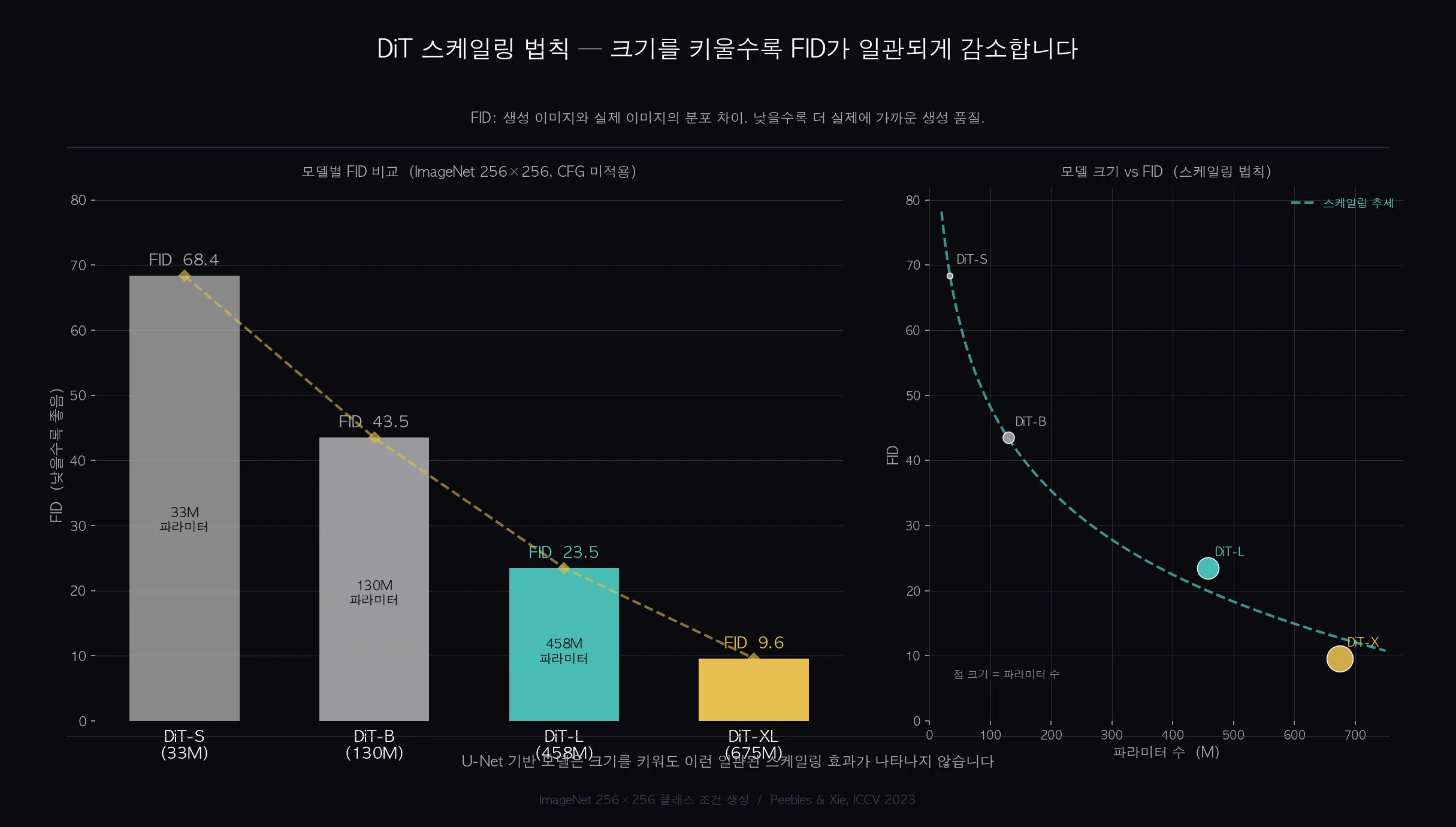
크기를 키울수록 왜 일관되게 좋아질까요?
DiT의 핵심 장점은 Transformer의 스케일링 법칙을 그대로 따른다는 점입니다.
ImageNet 256×256 기준 FID 수치를 보면 명확합니다.
(FID는 생성된 이미지가 실제 이미지와 얼마나 비슷한지 측정하는 수치입니다. 낮을수록 더 실제 이미지에 가깝습니다. Classifier-Free Guidance는 품질을 인위적으로 높이는 기법인데, 여기서는 그것 없이 순수 모델 성능만 비교합니다.)
- DiT-S (33M 파라미터): FID 68.4
- DiT-B (130M 파라미터): FID 43.5
- DiT-L (458M 파라미터): FID 23.5
- DiT-XL (675M 파라미터): FID 9.6
모델 크기를 키울수록 FID가 일관되게 감소합니다.
GPT 계열에서 확인된 스케일링 법칙이 이미지 생성에서도 동일하게 작동한 것입니다.
U-Net 기반 모델에서는 이런 일관된 패턴이 나타나지 않았습니다.
실사례 — FLUX, Stable Diffusion 3, Sora는 어떤 구조일까요?
우리가 이름을 아는 주요 이미지/비디오 생성 모델들이 대부분 DiT 계열입니다.
- Stable Diffusion 3: MMDiT(Multimodal DiT) 구조를 사용합니다. T5-XXL 텍스트 인코더를 도입해서 긴 텍스트 이해와 글자 렌더링 품질이 개선됐습니다.
- FLUX.1 (Black Forest Labs): 12B 파라미터 규모의 DiT 계열 모델로, 현재 오픈소스 이미지 생성 모델 중 가장 높은 품질로 평가됩니다. Stable Diffusion 팀 출신 연구자들이 만든 모델입니다. Double Stream Transformer로 이미지와 텍스트를 처음부터 병렬 처리합니다.
- Sora (OpenAI): 2024년 공개 당시 사실적인 영상 생성 능력으로 큰 화제가 됐던 모델입니다. 시간 축을 추가한 시공간 패치(Spacetime Patch)로 DiT를 비디오로 확장했습니다. 이미지 패치가 프레임×공간으로 확장된 구조입니다.
세 모델 모두 핵심 설계는 DiT 계열입니다. Transformer 기반 + 잠재 공간 Diffusion + 텍스트 Cross-Attention이라는 공통 골격을 공유합니다.
(쉽게 말하면: 미드저니, FLUX, Sora 모두 "노이즈 → 이미지" 과정을 Transformer로 처리한다는 점에서 같은 계열입니다. SD3는 텍스트와 이미지를 동등하게 처리, FLUX는 규모를 12B까지 키운 것, Sora는 이미지 대신 영상 프레임을 패치로 쓴 것입니다. 뼈대는 동일합니다.)
직접 실습해보려면
아래 세 가지를 Jupyter에서 해보면 DiT의 각 단계가 구체적으로 잡힙니다.
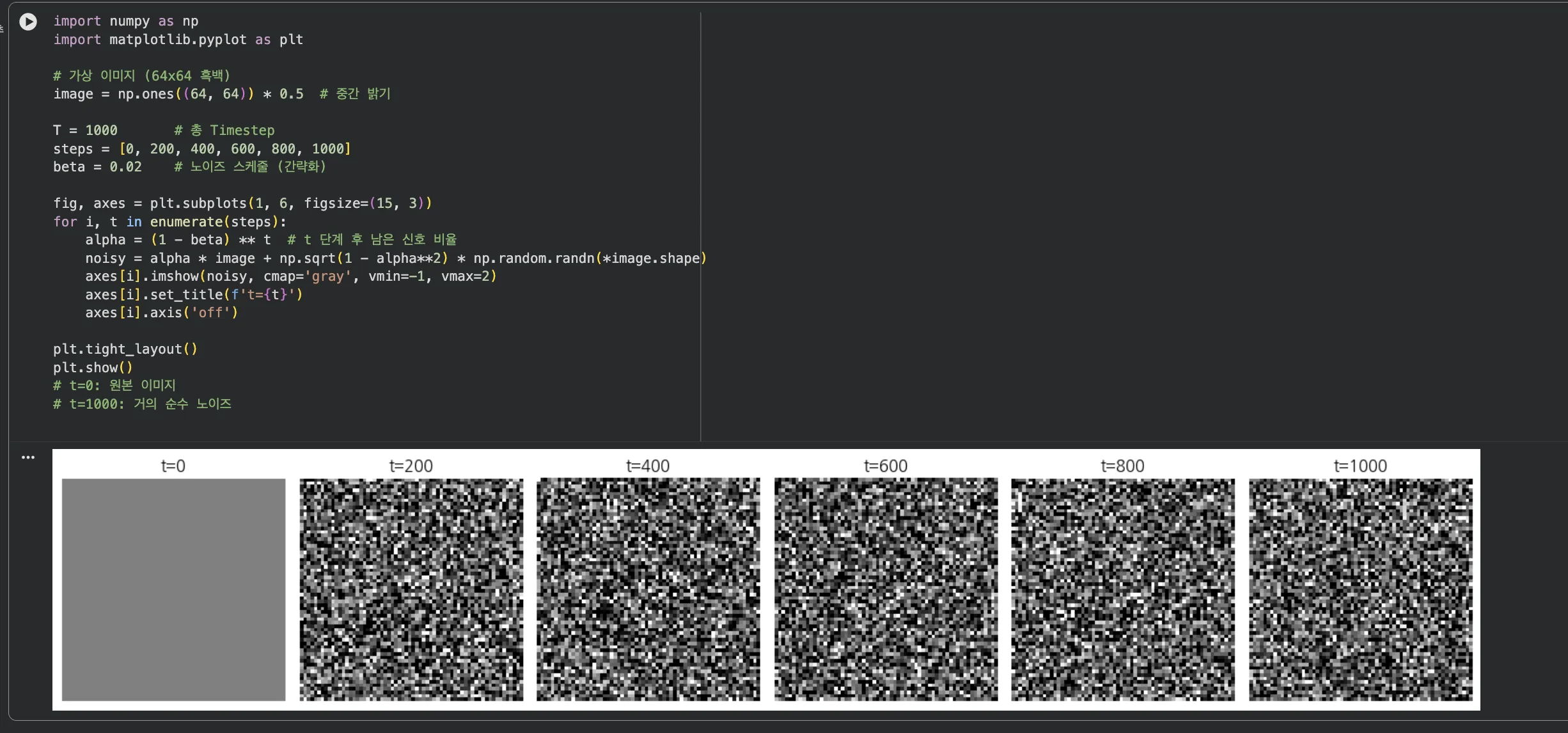
- 실습 1 — Forward Process 노이즈 시뮬레이션: numpy로 이미지 배열에 Gaussian 노이즈를 6단계에 걸쳐 추가하고 matplotlib으로 시각화. "노이즈가 쌓이는 과정"을 직접 확인할 수 있습니다.
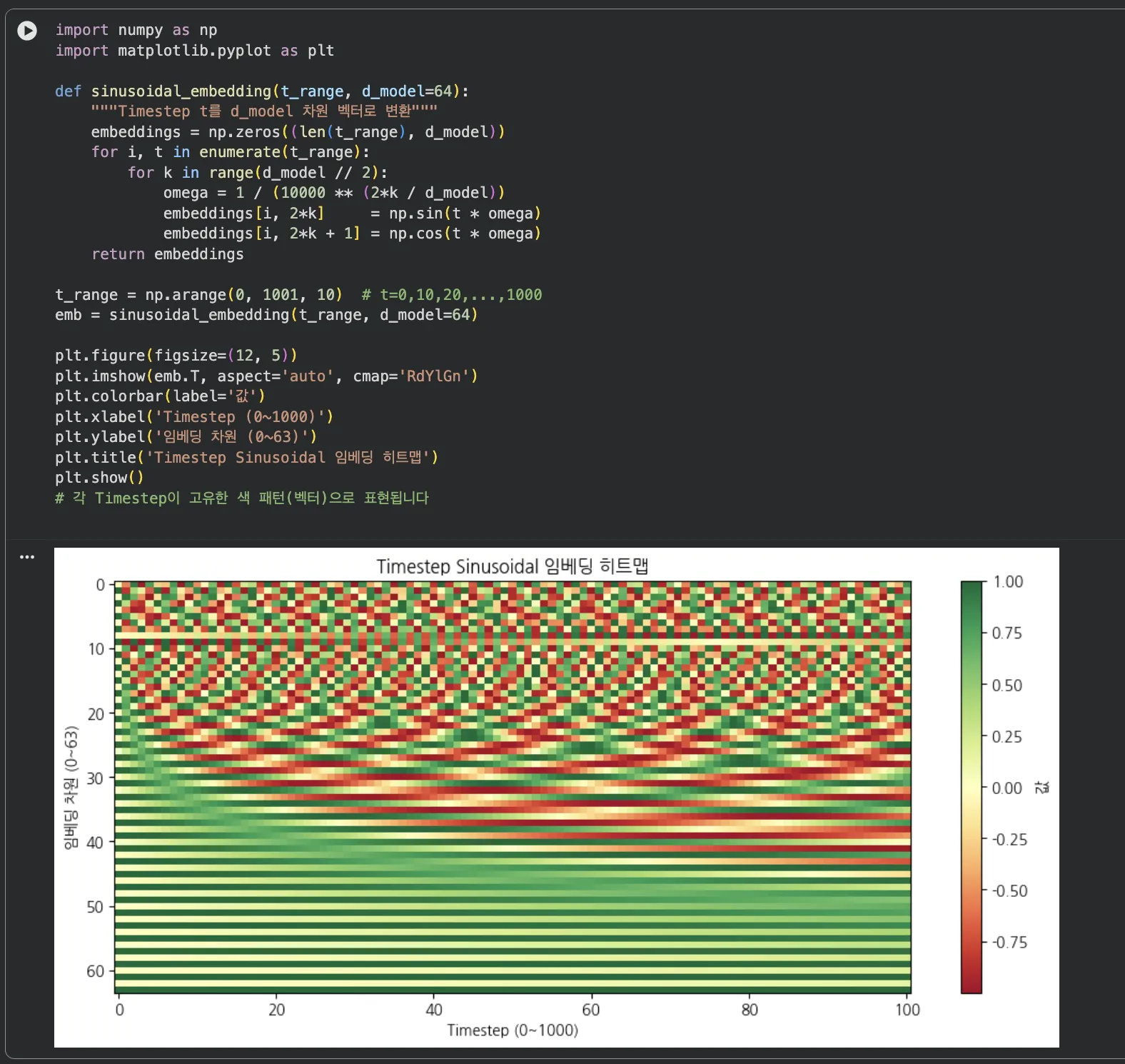
- 실습 2 — Timestep Sinusoidal 임베딩 히트맵: t=0부터 t=1000까지 Sinusoidal Embedding을 계산하고 히트맵으로 시각화. 각 Timestep이 고유한 벡터로 표현되는 구조가 보입니다.
- 실습 3 — DiT 블록 with adaLN PyTorch 구현: adaLN이 포함된 미니 DiT 블록을 구현하고 각 레이어의 shape 변화를 추적. 패치 시퀀스가 어떻게 변환되는지 확인할 수 있습니다.
Jupyter 실행 결과 보기 — 파트 1: Forward Process 노이즈 시뮬레이션
Jupyter 실행 결과 보기 — 파트 2: Timestep Sinusoidal 임베딩 히트맵
Jupyter 실행 결과 보기 — 파트 3: DiT 블록 with adaLN PyTorch 구현
정리
- Diffusion 원리: Forward Process로 이미지에 노이즈를 추가하고, Reverse Process로 노이즈를 제거해서 이미지를 생성합니다. 모델은 각 단계에서 제거할 노이즈를 예측합니다.
- VAE 잠재 공간: 픽셀(786,432개) 대신 압축된 잠재 벡터(16,384개)에서 노이즈를 처리합니다. 약 48배 계산량 감소로 고해상도 생성이 현실적으로 가능해집니다.
- DiT = Transformer 백본: U-Net 대신 Transformer를 사용합니다. 크기를 키울수록 성능이 일관되게 향상되는 스케일링 법칙이 적용됩니다.
- adaLN Timestep 주입: 현재 노이즈 단계(Timestep t)에서 gamma와 beta를 동적으로 생성해서 Layer Normalization에 적용합니다. 단계마다 다른 처리 방식을 적용할 수 있습니다.
- 텍스트 조건 Cross-Attention: 텍스트 임베딩이 Key/Value, 이미지 패치가 Query 역할을 합니다. 각 이미지 영역이 텍스트 설명의 어느 부분을 참조할지 학습합니다. FLUX.1은 Double Stream으로 더 강한 양방향 참조를 구현했습니다.
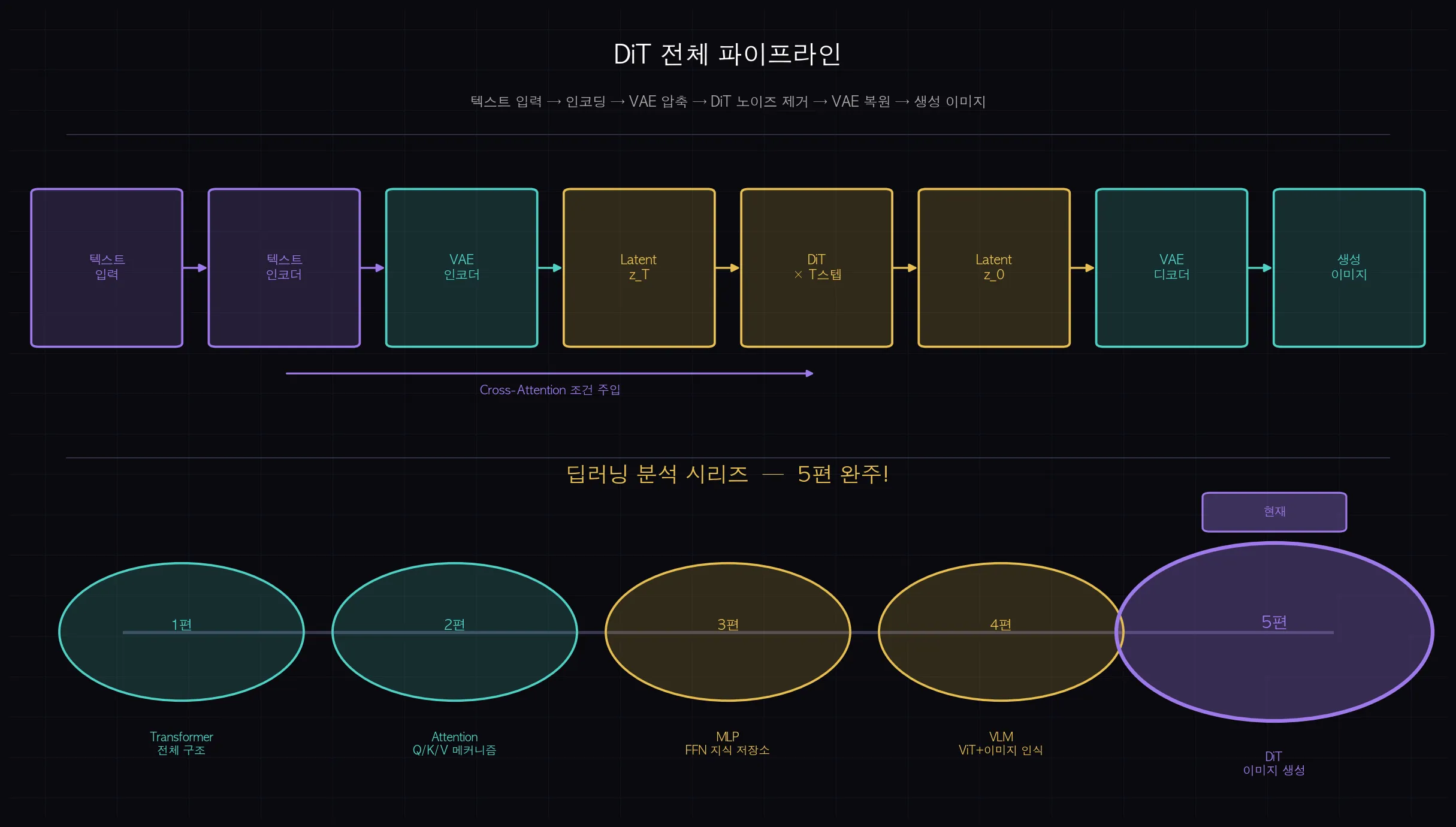
1편 Transformer 구조, 2편 Attention, 3편 MLP, 4편 VLM 이미지 인식, 그리고 5편 DiT 이미지 생성까지 왔습니다.
텍스트를 처리하던 Transformer가 이미지를 읽고, 나아가 이미지를 만들어내는 데까지 확장됐습니다.
이 구조들이 결합되면 텍스트, 이미지, 비디오를 통합 처리하는 멀티모달 모델이 됩니다.