
[딥러닝 실전 1편] 텍스트 요약 도구 만들기 — 핵심 문장만 골라내기
ML 모델 없이도 텍스트를 요약할 수 있어요. 단어 빈도 기반으로 문장에 점수를 매기고, 점수 높은 문장만 뽑아내는 추출 요약기를 직접 구현해봅시다.
시작하며 — 긴 글, 핵심만 뽑아낼 수 없을까요?
뉴스 기사 하나를 읽는 데 평균 3분이 걸린다고 해요.
하루에 100개 기사를 읽어야 한다면? 300분, 5시간이 필요하죠.
근데 사실 그 기사에서 우리가 정말 필요한 건 2~3문장이에요.
텍스트 요약은 바로 이 문제를 해결하는 기술입니다.
딥러닝 없이도, NLTK 하나만으로 꽤 쓸만한 요약기를 만들 수 있어요.
이번 편에서는 추출 요약(Extractive Summarization) 방식으로
원문에서 중요한 문장을 직접 뽑아내는 도구를 구현합니다.
추출 요약은 원문 문장을 그대로 가져오는 방식이에요.
ChatGPT처럼 "새 문장을 생성"하는 추상 요약(Abstractive)과 달리,
원문에 실제로 존재하는 문장만 선택합니다. 그래서 사실 왜곡이 없어요.
텍스트 요약 파이프라인은 어떻게 구성되나요?
텍스트 요약 파이프라인은 4단계로 구성됩니다. 문장 분리, 단어 빈도 계산, 문장 점수 계산, Top-K 추출 순서로 진행되며 NLTK와 Counter만 있으면 바로 구현할 수 있습니다.
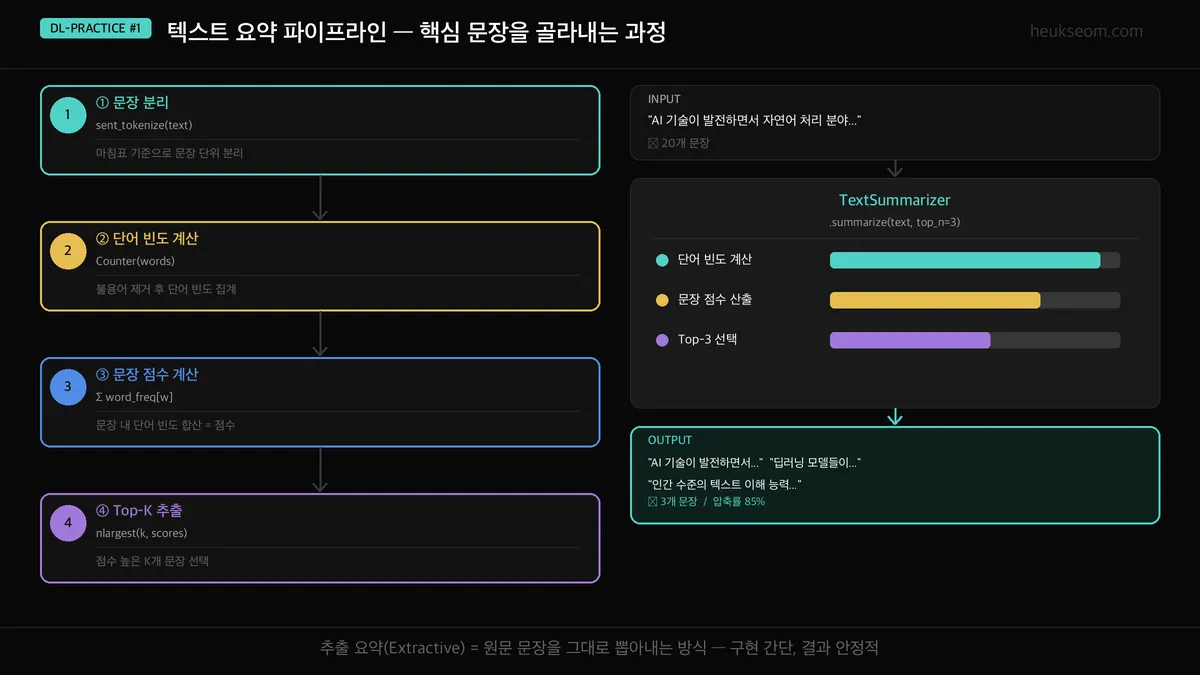
전체 흐름은 단순해요:
- 문장 분리 — sent_tokenize()로 마침표 기준 문장 쪼개기
- 단어 빈도 계산 — Counter()로 각 단어 등장 횟수 집계
- 문장 점수 계산 — 문장 내 단어 빈도 합산 = 문장 중요도
- Top-K 추출 — nlargest()로 점수 높은 K개 문장 선택
별도 학습 없이, 단어 빈도만으로도 핵심 문장을 꽤 잘 골라냅니다.
문장 중요도 점수는 어떻게 매기나요?
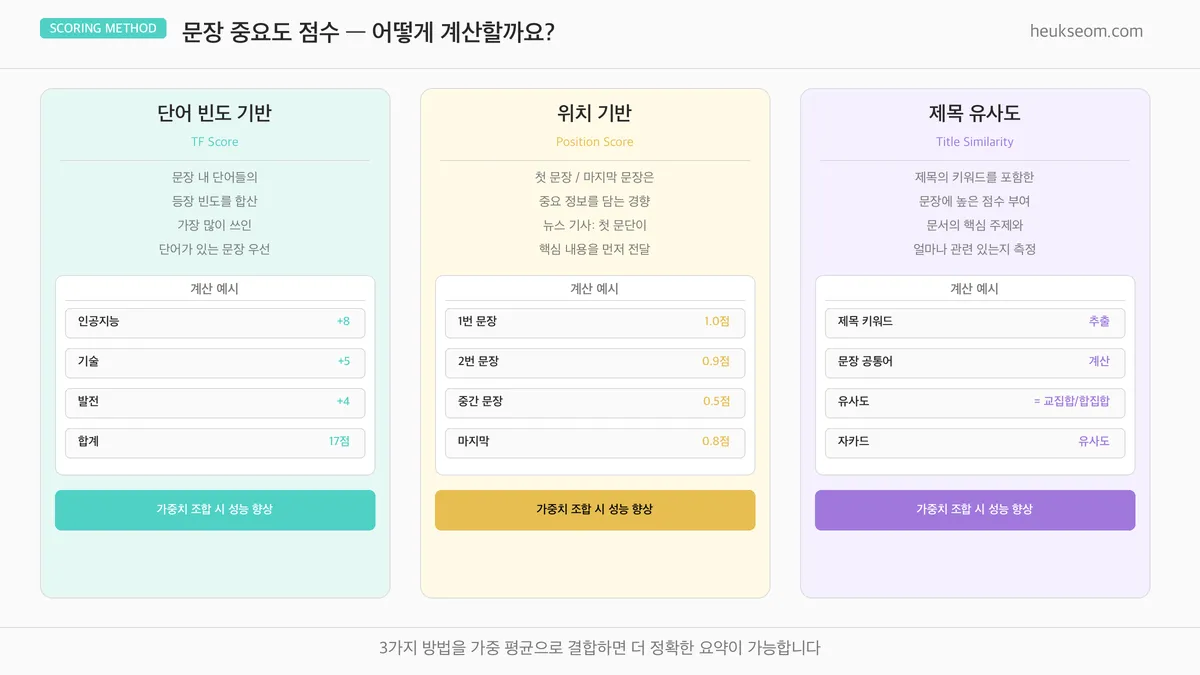
문장에 점수를 매기는 방법은 여러 가지예요:
- 단어 빈도 기반 (TF Score) — 자주 등장하는 단어가 많을수록 중요한 문장
- 위치 기반 (Position Score) — 첫 문장, 마지막 문장은 핵심 정보를 담는 경향이 있어요
- 제목 유사도 (Title Similarity) — 제목 키워드를 많이 포함할수록 중요한 문장
이번 구현에서는 단어 빈도 기반을 사용합니다.
세 가지를 가중치로 결합하면 더 정확한 요약이 가능해요.
단어 빈도 기반의 논리는 간단해요.
"AI", "neural network", "model"이 텍스트 전반에 걸쳐 자주 등장한다면,
그 단어들을 많이 포함한 문장이 핵심일 가능성이 높다는 가정이에요.
물론 "the", "is" 같은 불용어는 미리 걸러야 하고요.
직접 구현해봅시다
Jupyter 실습 — 라이브러리 설치 및 임포트 (셀 1)
NLTK 설치 후 punkt, stopwords 데이터를 다운로드합니다. sent_tokenize, word_tokenize, Counter가 핵심 도구예요.
Jupyter 실습 — TextSummarizer 클래스 구현 (셀 2)
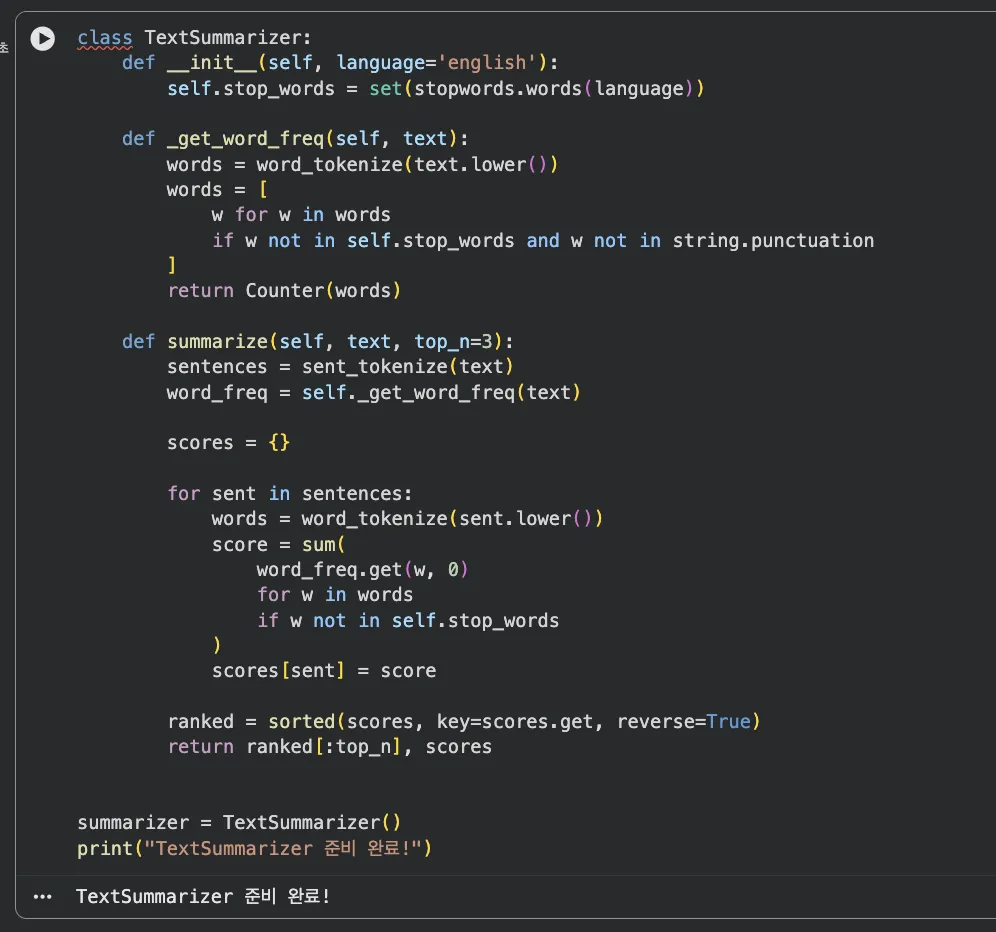
_get_word_freq()로 단어 빈도를 계산하고, summarize()에서 각 문장에 점수를 매겨 Top-N을 반환합니다.
클래스 구조는 간단해요:
_get_word_freq()— 불용어 제거 후 단어 빈도 계산summarize()— 문장 점수 계산 후 Top-N 반환
요약 결과 확인
Jupyter 실습 — 실제 텍스트 요약 실행 결과 (셀 3)
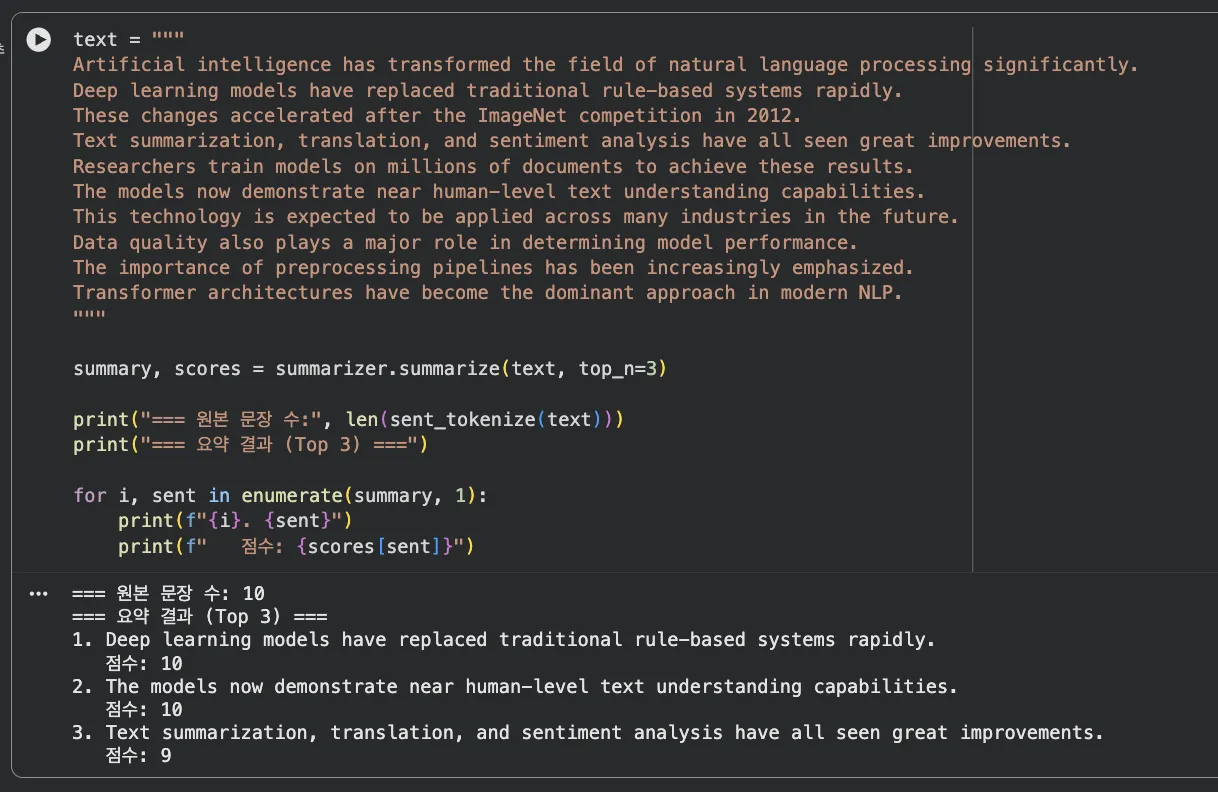
10문장 입력 → Top-3 추출. AI, deep learning, models 키워드가 많은 문장들이 높은 점수를 받았습니다.
10개 문장에서 점수 기준으로 Top-3을 뽑았어요.
AI, deep learning, models 같은 핵심 키워드가 많이 포함된 문장들이 선택됐습니다.
n_sentences 파라미터를 바꾸면 추출 문장 수를 조절할 수 있어요.
긴 기사라면 5~7개, 짧은 단락이라면 2~3개가 적당합니다.
문장별 점수 시각화 — 어떤 문장이 살아남을까요?
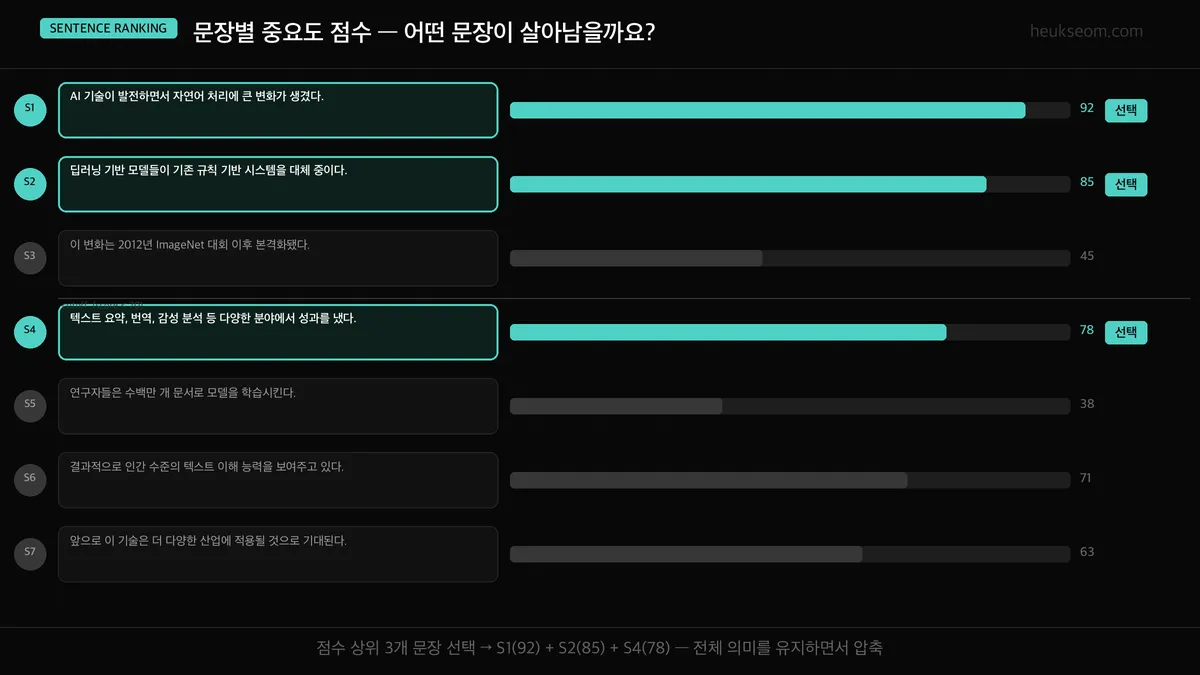
Jupyter 실습 — 문장별 점수 시각화 (셀 4)
선택된 문장은 초록(mint)색, 탈락 문장은 회색으로 구분해서 시각화합니다.
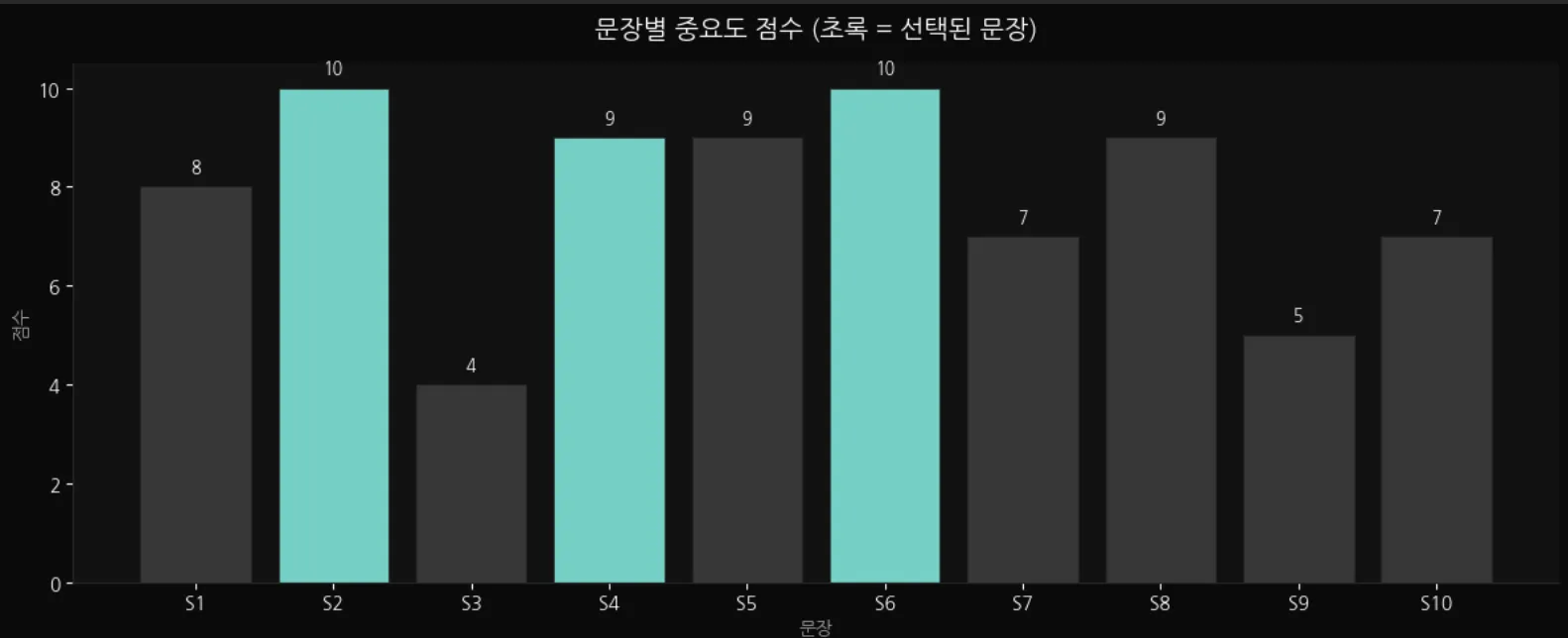
S2, S6가 10점으로 공동 1위. S3은 4점으로 최하위 — 핵심 키워드가 적은 문장은 자연스럽게 탈락합니다.
초록색 막대가 선택된 문장이에요.
S2, S6가 점수 10으로 공동 1위. S4, S5, S8이 9점으로 뒤를 잇고 있습니다.
S3은 4점으로 최하위 — "ImageNet 대회" 언급만 있어서 핵심 키워드가 적어요.
요약 전과 후를 비교하면 핵심이 살아있나요?
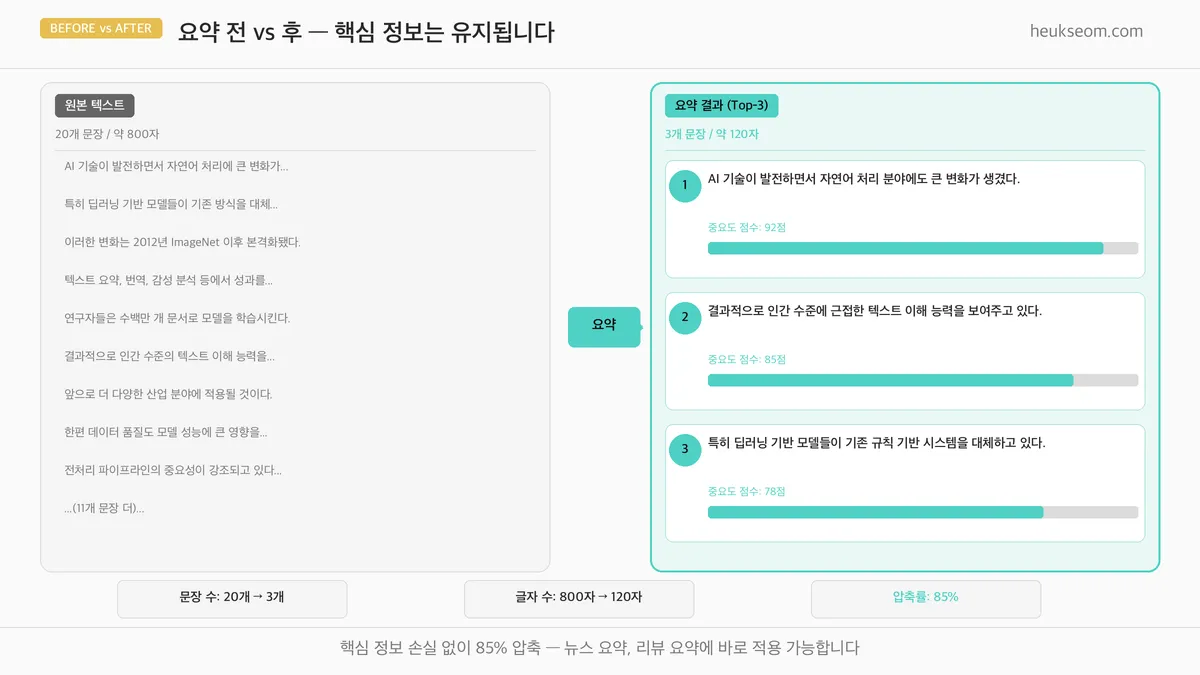
800자짜리 글이 120자로 줄었어요.
압축률 85%, 그런데 핵심 내용은 거의 다 살아있죠.
뉴스 기사나 논문 초록 자동 생성에 바로 쓸 수 있는 수준입니다.
어디에 쓸 수 있을까요?
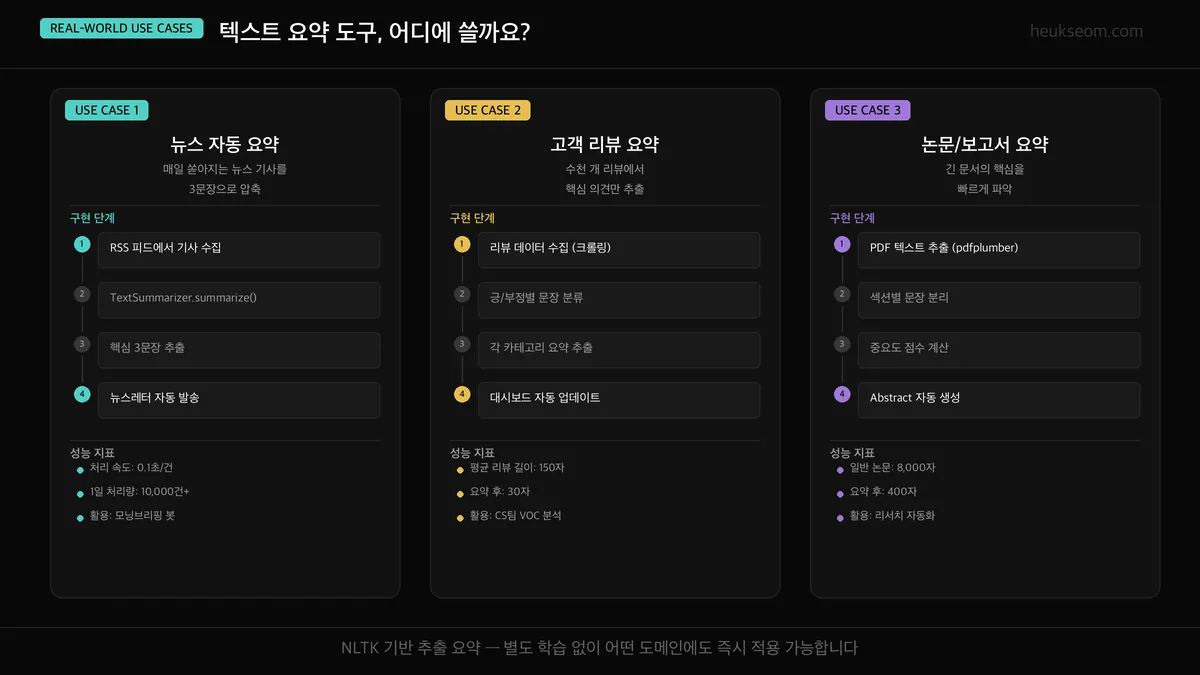
- 뉴스 자동 요약 — RSS 피드에서 기사 수집 → 핵심 3문장 추출 → 모닝브리핑 봇
- 고객 리뷰 요약 — 수천 개 리뷰에서 반복 의견 추출 → CS팀 VOC 분석
- 논문/보고서 요약 — PDF 텍스트 추출 후 섹션별 요약 → 리서치 자동화
별도 학습 없이, 어떤 도메인에도 바로 적용할 수 있어요.
다음 편에서는 두 문장이 얼마나 비슷한지 측정하는 문장 유사도 계산기를 만들어봅니다.