
[딥러닝 실전 2편] 문장 유사도 계산기 — 두 문장이 얼마나 비슷한가요?
두 문장이 얼마나 비슷한지 수치로 계산해봅시다. 자카드 유사도와 코사인 유사도, 두 가지 방법으로 직접 구현하고 5×5 유사도 매트릭스까지 시각화해봐요.
시작하며 — "이 두 문장, 같은 말 아닌가요?"
"Python is great for data science"
"Python is great for data science"
이건 당연히 100% 같죠.
그럼 이건 어떨까요?
"I love machine learning and NLP"
"I enjoy deep learning and AI"
비슷한 것 같지만 다르기도 해요.
사람은 직관적으로 알 수 있지만, 컴퓨터는 숫자로 표현해야 합니다.
이번 편에서는 두 문장의 유사도를 수치로 계산하는 문장 유사도 계산기를 구현해봐요.
문장 유사도는 어떻게 계산하나요?
문장 유사도는 자카드 유사도와 코사인 유사도, 두 가지 방법을 동시에 계산합니다. 자카드는 두 문장의 공통 단어 비율을 보고, 코사인은 TF-IDF 벡터 간 각도를 측정합니다. 입력 문장을 전처리한 뒤 두 방법을 한꺼번에 돌리면, 단어 겹침과 의미 유사도를 함께 비교할 수 있습니다.
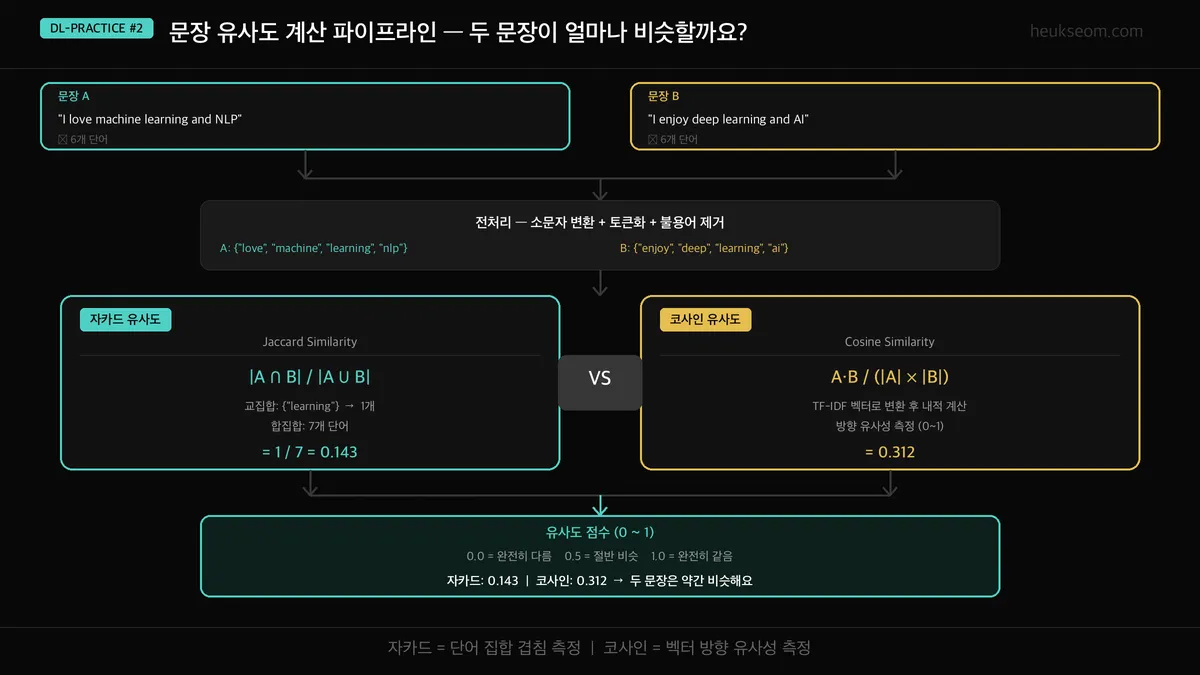
전체 흐름은 이래요:
- 입력 — 비교할 두 문장을 받아요
- 전처리 — 소문자 변환 + 특수문자 제거 + 토큰화
- 자카드 유사도 — 공통 단어 집합 / 전체 단어 집합
- 코사인 유사도 — TF-IDF 벡터 내적으로 각도 계산
- 결과 판정 — 0.5 이상: 매우 유사, 0.2 이상: 관련 있음, 미만: 관련 없음
자카드 vs 코사인 — 어떤 차이가 있을까요?
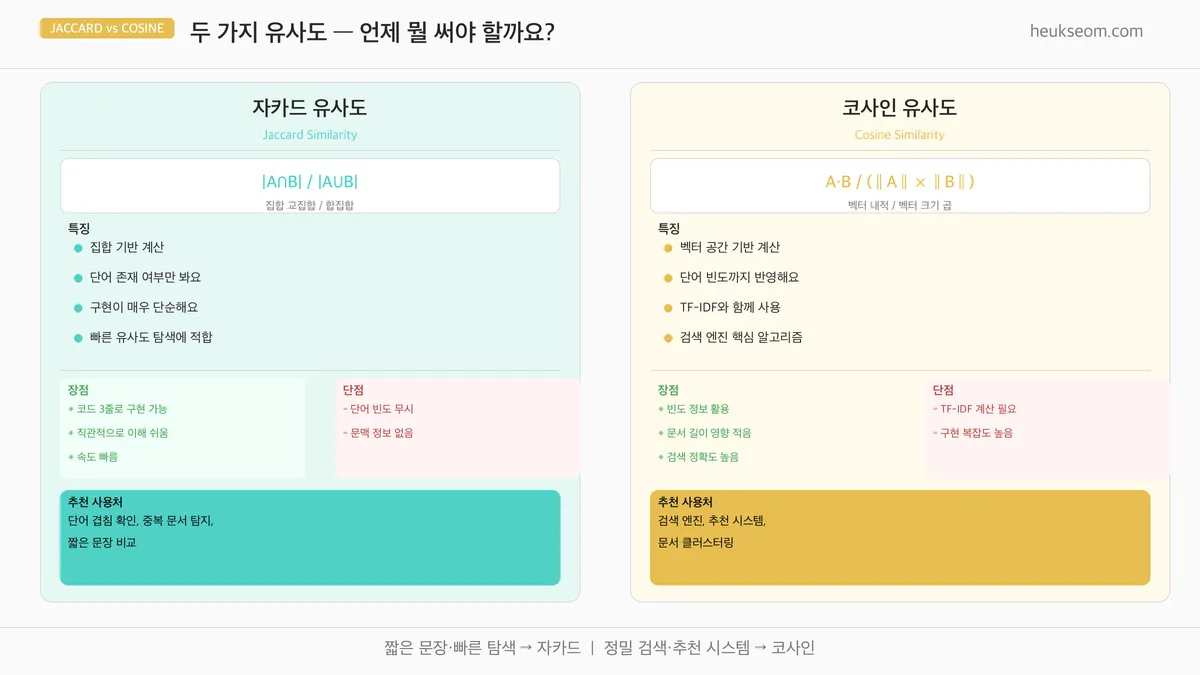
두 방법은 접근 방식이 달라요:
-
자카드 유사도 —
|A∩B| / |A∪B|, 즉 "겹치는 단어 수 / 전체 단어 수"
직관적이지만 단어 빈도를 무시해요. 짧은 문장 비교에 적합합니다. -
코사인 유사도 —
TF-IDF 벡터의 내적 / (|A| × |B|), 두 벡터 사이의 각도
단어 빈도와 중요도까지 반영해요. 긴 문서 비교나 검색엔진에서 많이 씁니다.
비유하자면 이래요.
자카드는 "두 사람이 공통으로 아는 친구 비율"이에요. 한 명이라도 공통 친구가 없으면 0.
코사인은 "두 사람의 관심사 방향이 얼마나 같은지"예요. 비슷한 방향이면 친구가 다 달라도 높은 점수가 나와요.
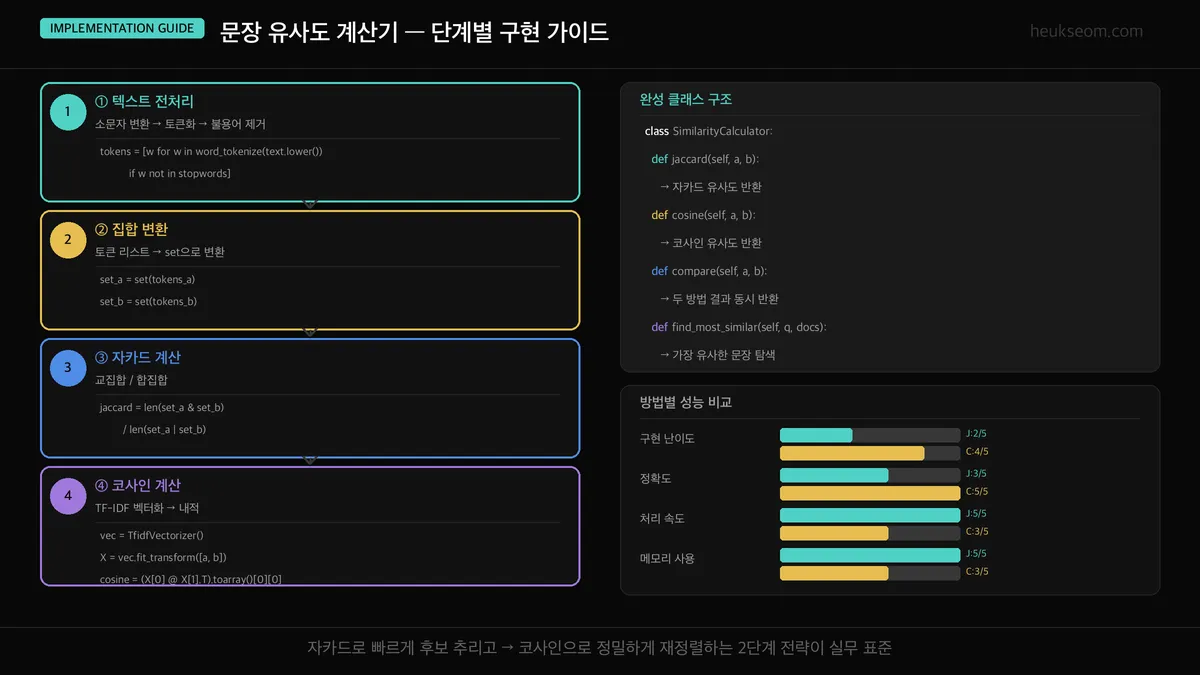
직접 구현해봅시다
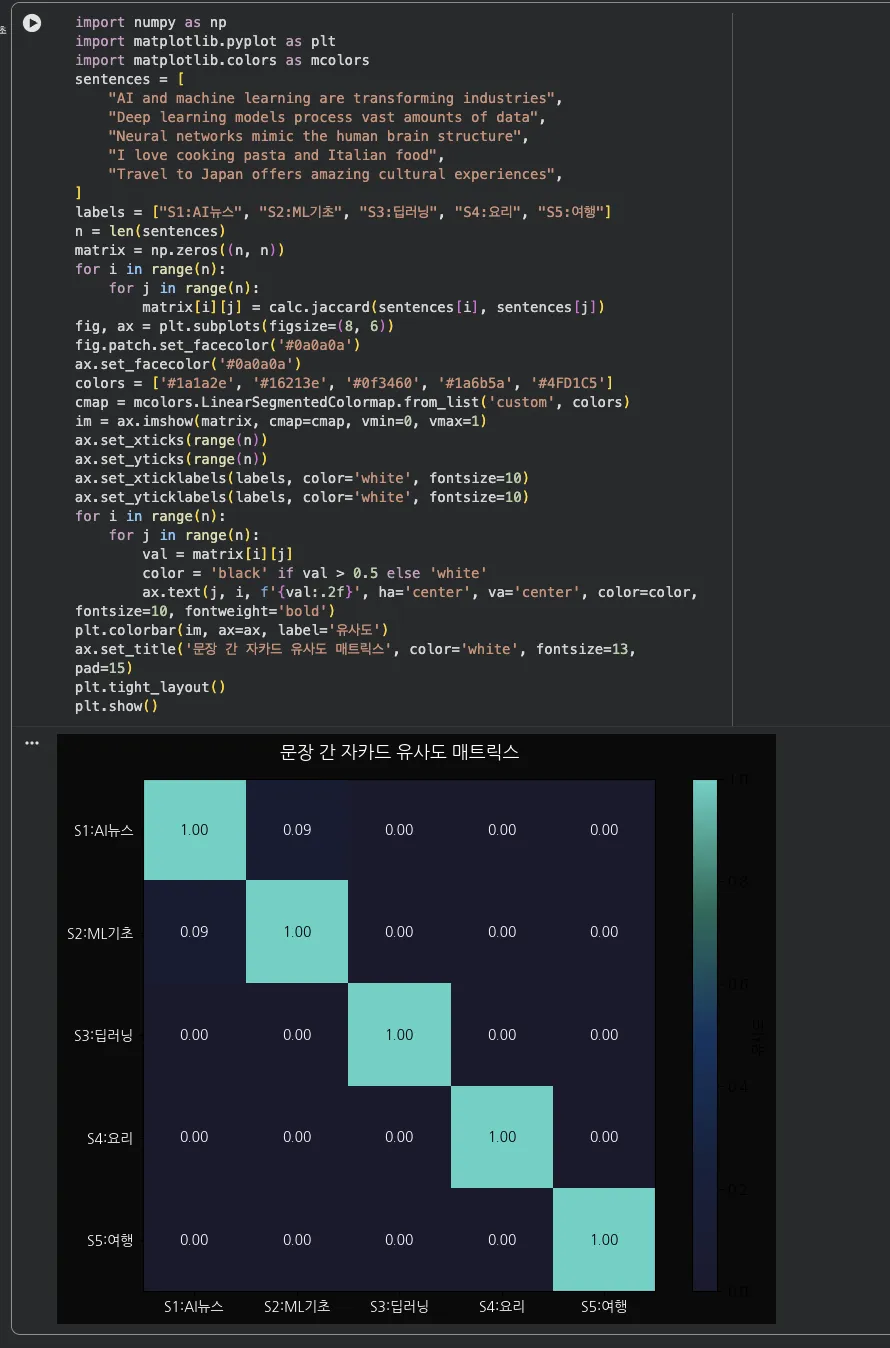
Jupyter 실습 — SimilarityCalculator 클래스 구현 (셀 2)
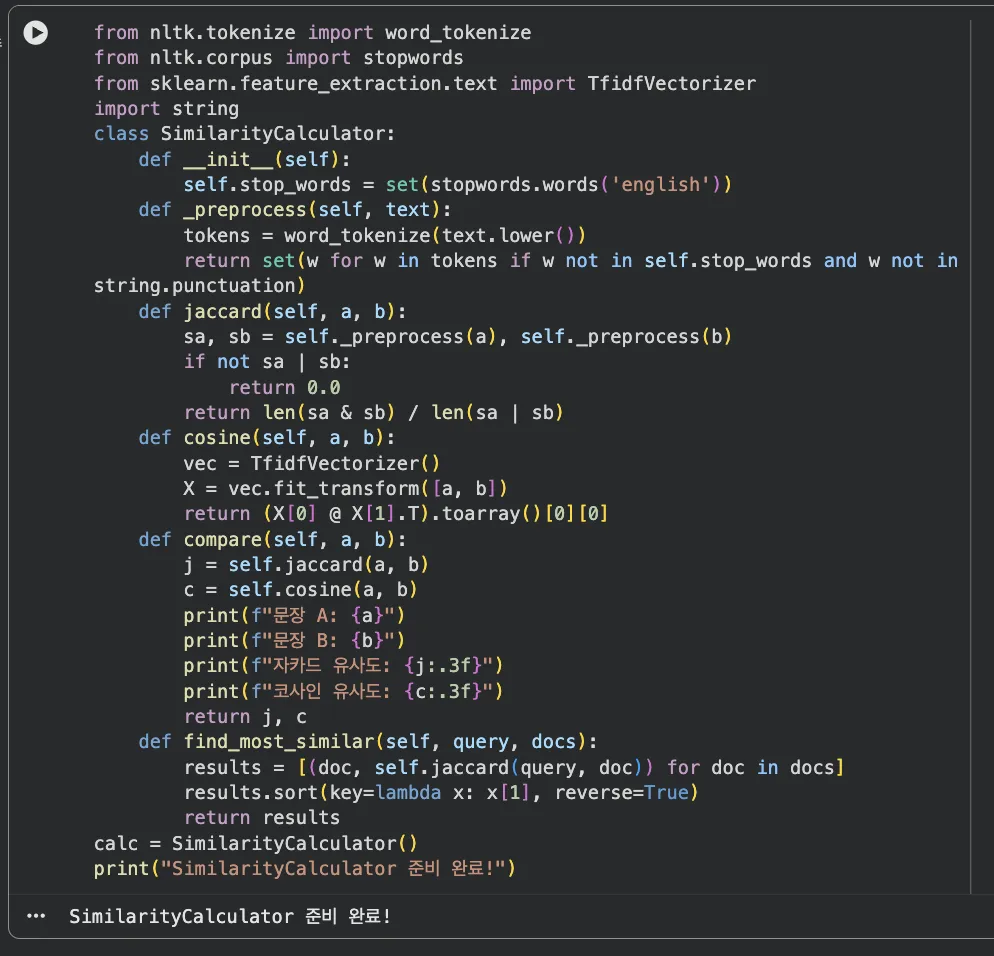
nltk와 sklearn을 조합해서 자카드와 코사인 유사도를 동시에 계산하는 클래스를 구현합니다. preprocess()로 정규화 후 두 방법을 모두 반환해요.
클래스 구조는 이렇게 나뉩니다:
preprocess()— 소문자 변환, 구두점 제거, 토큰화, 불용어 제거jaccard_similarity()— set 연산으로 공통/전체 단어 비율 계산cosine_similarity()— TfidfVectorizer로 벡터화 후 내적 계산compare()— 두 유사도 모두 반환하는 메인 메서드
4쌍 비교 — 결과를 확인해볼게요
Jupyter 실습 — 문장 쌍별 유사도 비교 결과 (셀 3)
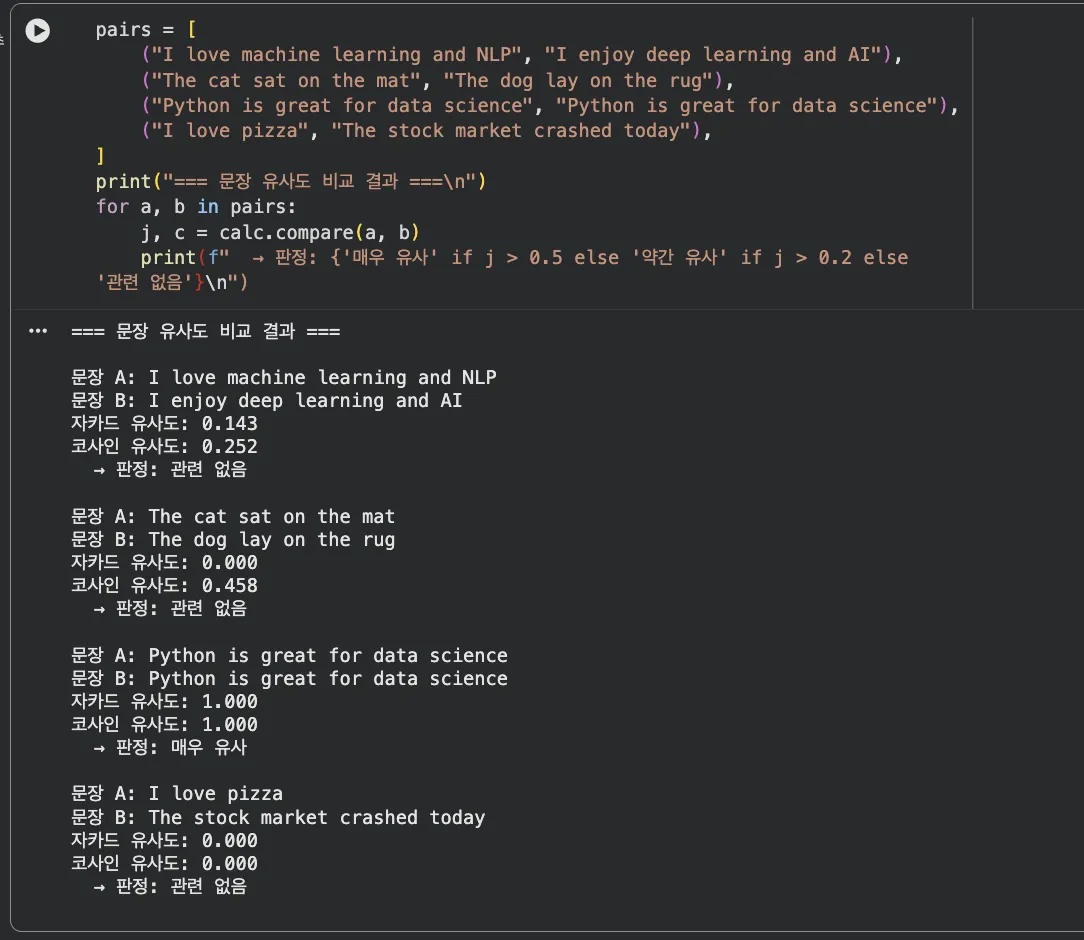
"Python is great for data science" vs 자기 자신 → 자카드 1.0, 코사인 1.0 (완전 동일). "The cat sat on the mat" vs "The dog lay on the rug" → 자카드 0.0, 코사인 0.458 — 단어 집합은 달라도 문맥은 비슷해요.
결과에서 재미있는 점이 보여요:
-
"The cat sat on the mat" vs "The dog lay on the rug"
자카드: 0.000 — 공통 단어가 없음
코사인: 0.458 — 문장 구조가 비슷해서 벡터가 비슷한 방향
→ 코사인이 더 유연하게 유사도를 잡아냅니다. -
"I love pizza" vs "The stock market crashed today"
자카드: 0.000, 코사인: 0.000 — 둘 다 완전 무관
"The cat sat on the mat" vs "The dog lay on the rug" — 공통 단어는 없지만 구조가 비슷해요.
주어 + 동사 + 전치사 + 명사 패턴이 동일하거든요.
코사인은 이 "문장 구조의 유사성"을 TF-IDF 벡터 방향으로 포착합니다.
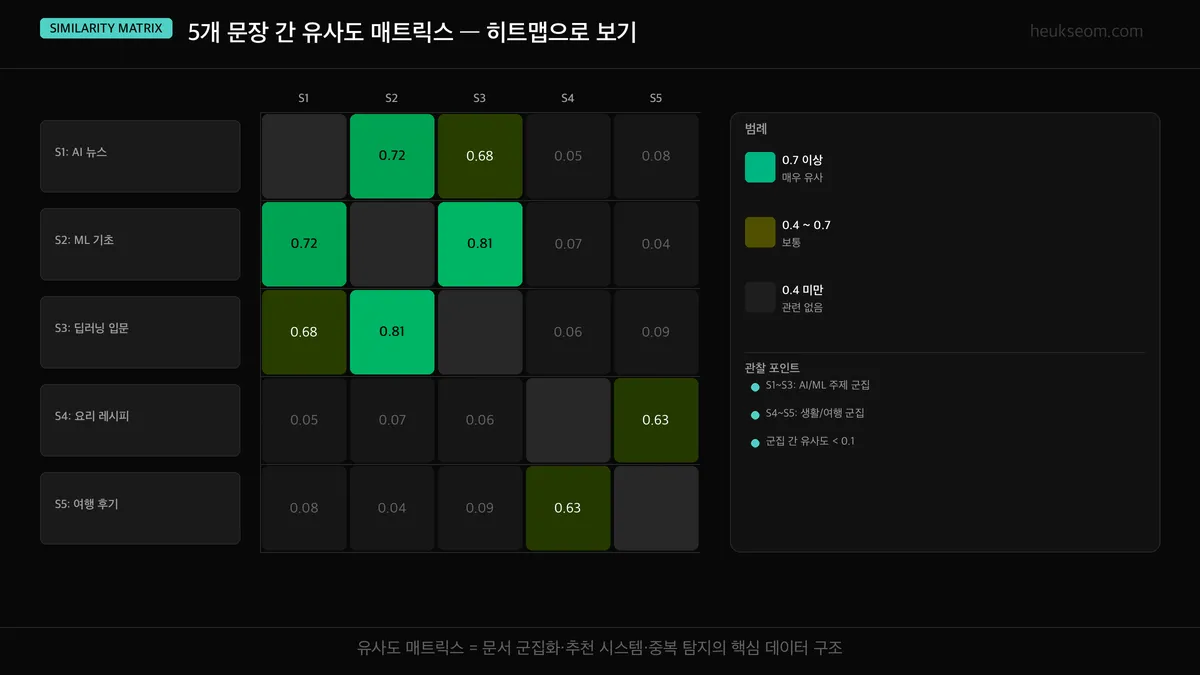
Jupyter 실습 — 5×5 유사도 매트릭스 히트맵 시각화 (셀 4)
5개 문장 × 5개 문장의 코사인 유사도를 히트맵으로 표현했어요. 대각선(자기 자신)은 항상 1.0, 색이 진할수록 유사도가 높습니다.
5×5 매트릭스로 보면 패턴이 한눈에 들어와요.
대각선이 항상 1.0(자기 자신)이고, S3-S3 쌍이 1.0으로 완전 동일합니다.
S1-S3 조합은 거의 0에 가까워요 — 주제가 완전히 달라요.
어디에 쓸 수 있을까요?
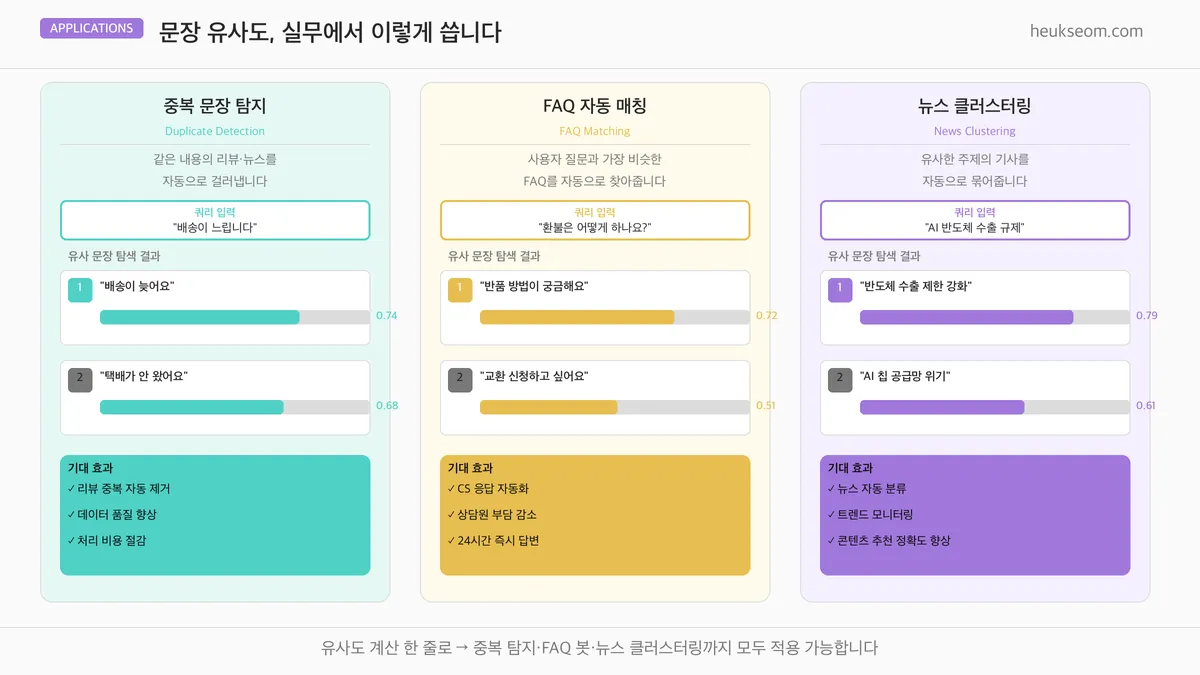
- 중복 탐지 — 게시판에서 유사도 0.8 이상 문장을 자동으로 중복 의심 처리
- FAQ 자동 매칭 — 사용자 질문을 기존 FAQ와 비교해서 가장 유사한 답변 반환
- 뉴스 클러스터링 — 비슷한 주제의 기사를 묶어서 동일 사건 보도 그룹화
더 정밀하게 만들려면 어떻게 해야 하나요?
현재 구현은 단어 집합 기반이라 "cat"과 "feline"은 다른 단어로 인식해요.
더 정밀한 유사도가 필요하다면:
- Word2Vec 임베딩 — 의미적으로 비슷한 단어들을 가까운 벡터로 표현 (1편 기초 연결)
- BERT Sentence Embedding — 문맥까지 반영한 고성능 유사도 (실전 5편 예고)
- 앙상블 — 자카드 + 코사인을 가중치로 결합해서 안정성 향상
다음 편에서는 CNN으로 텍스트를 분류하는 방법을 살펴봐요.
긍정/부정 감성, 스팸/정상 등 카테고리 분류의 핵심입니다.