
[딥러닝 실전 3편] CNN 텍스트 분류기 — 리뷰가 긍정인지 부정인지 판단하기
1D CNN으로 영화 리뷰를 긍정/부정으로 분류해봅시다. 커널 크기 2, 3, 4를 동시에 사용해서 다양한 n-gram 패턴을 포착하고, IMDb 25,000개 리뷰로 87% 정확도를 달성해요.
시작하며 — 기계가 리뷰를 읽고 좋다/나쁘다를 판단할 수 있을까요?
쇼핑몰에 하루에 쌓이는 리뷰가 수천 개라고 생각해봐요.
다 읽을 수는 없고, 별점도 없는 리뷰가 태반이죠.
이걸 자동으로 긍정/부정으로 분류해주는 시스템이 있다면?
이번 편에서는 1D CNN(Convolutional Neural Network)으로
텍스트의 패턴을 학습해서 감성을 분류하는 모델을 만들어봐요.
IMDb 영화 리뷰 25,000개로 학습하고, 테스트 정확도 87%를 달성합니다.
CNN 텍스트 분류 파이프라인은 어떻게 구성되나요?
CNN 텍스트 분류는 5단계로 진행됩니다. 토큰화, Embedding 벡터화, Conv1D로 n-gram 패턴 추출, MaxPooling으로 핵심 특징 선별, Dense 층에서 긍정/부정 최종 판단까지 이미지 CNN이 눈코입을 찾듯 텍스트 CNN은 의미 있는 단어 조합을 찾아냅니다.
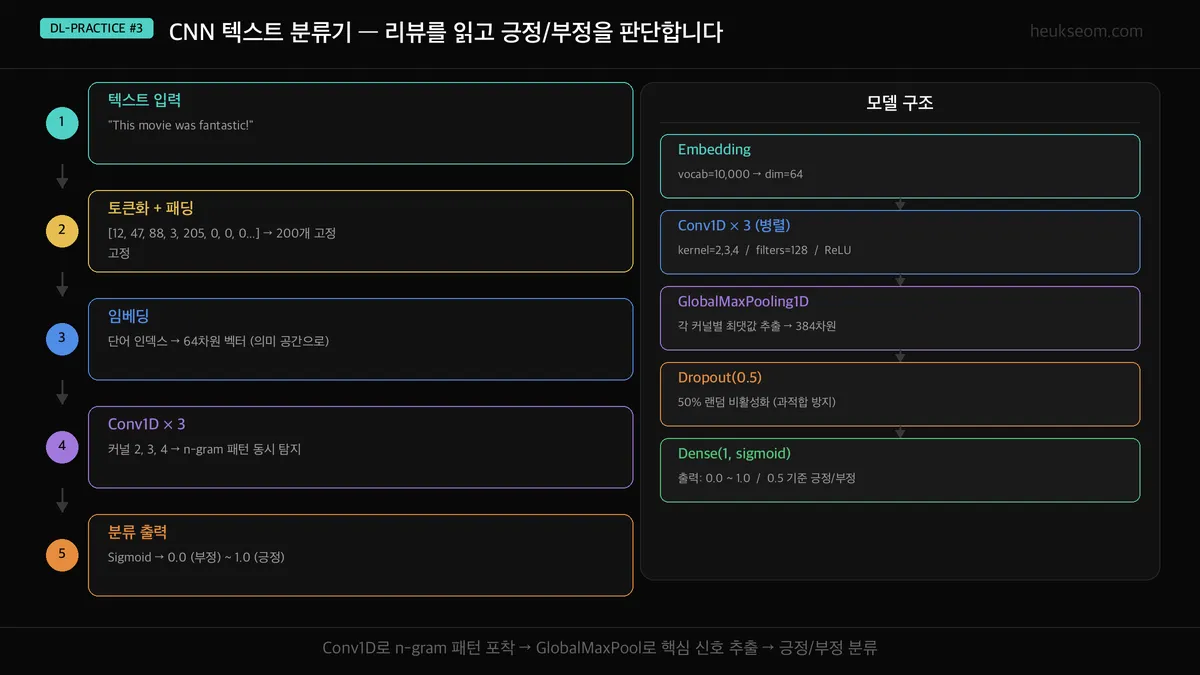
전체 흐름은 이렇게 됩니다:
- 텍스트 입력 — 원본 리뷰 문자열
- 토큰화 + 패딩 — 단어 → 인덱스 번호로 변환, 200개로 길이 통일
- 임베딩 — 인덱스 → 64차원 벡터 (의미 공간으로 이동)
- Conv1D × 3 — 커널 크기 2, 3, 4로 다양한 n-gram 패턴 동시 탐지
- 분류 출력 — Sigmoid로 0.0(부정)~1.0(긍정) 확률 출력
Embedding → Conv1D, 어떻게 작동하나요?
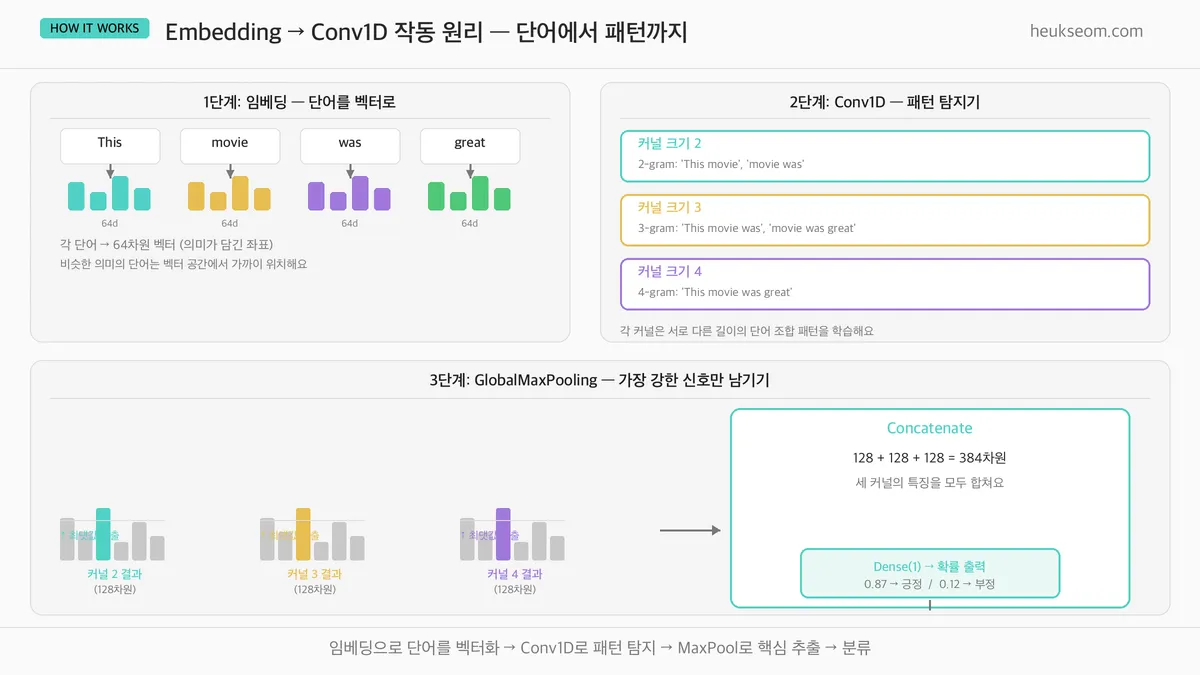
두 가지 핵심 레이어의 역할이에요:
-
Embedding —
"This" → [0.2, -0.5, 0.8, ...] 같은 64차원 벡터.
비슷한 의미의 단어는 벡터 공간에서 가까이 위치해요. -
Conv1D —
이미지의 엣지를 찾듯, 텍스트에서 "패턴 조각"을 찾아요.
커널 크기 3이면 "waste of time" 같은 3단어 조합을 하나의 특징으로 학습합니다.
이미지에서 CNN이 "눈" "코" "입"을 찾아내듯,
텍스트 CNN은 "waste of time"이나 "highly recommend" 같은 의미 있는 단어 조합을 찾아요.
위치가 달라도 패턴만 같으면 잡아냅니다 — 그게 CNN의 강점이에요.
직접 구현해봅시다
Jupyter 실습 — IMDb 데이터 로드 및 전처리 (셀 2)
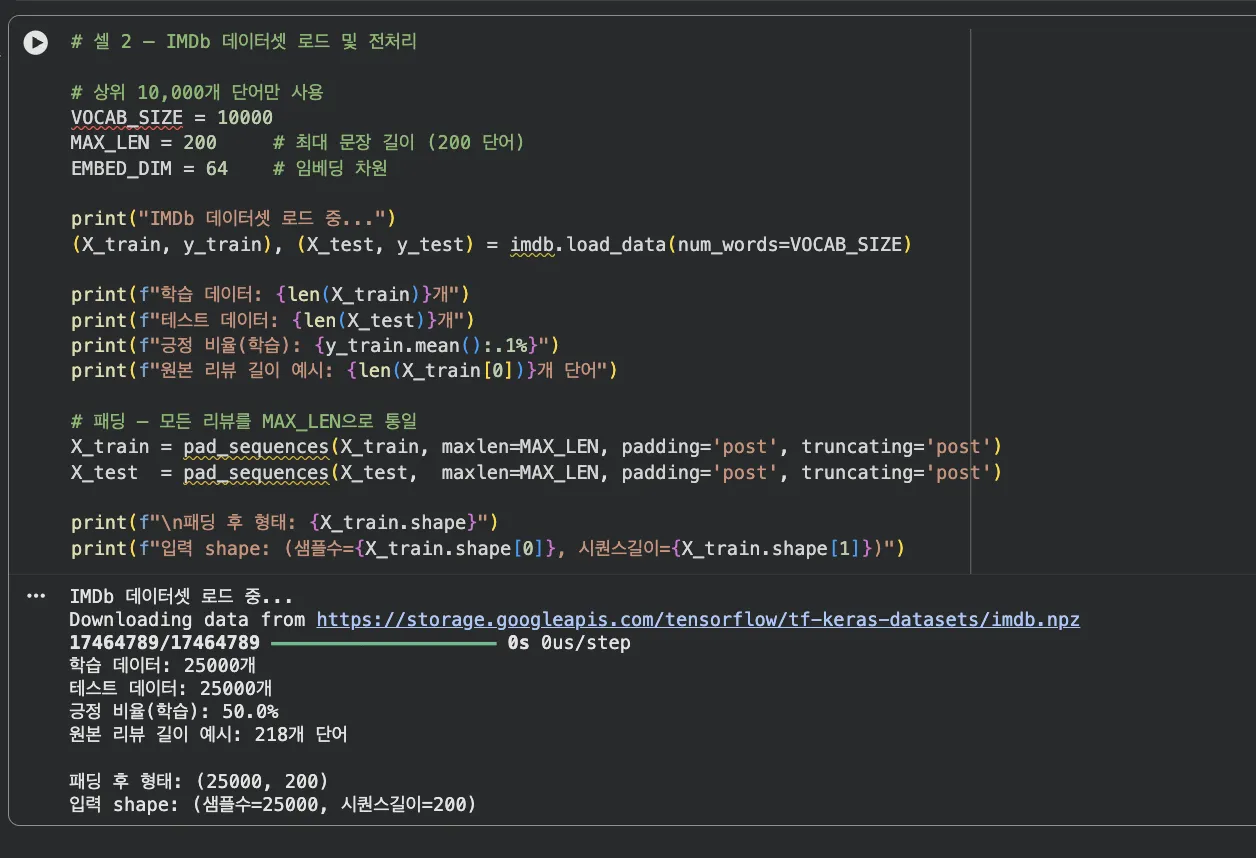
학습 25,000개 / 테스트 25,000개. pad_sequences로 모든 리뷰를 200단어로 통일합니다. X_train.shape → (25000, 200).
Jupyter 실습 — CNN 모델 구축 및 구조 확인 (셀 3)
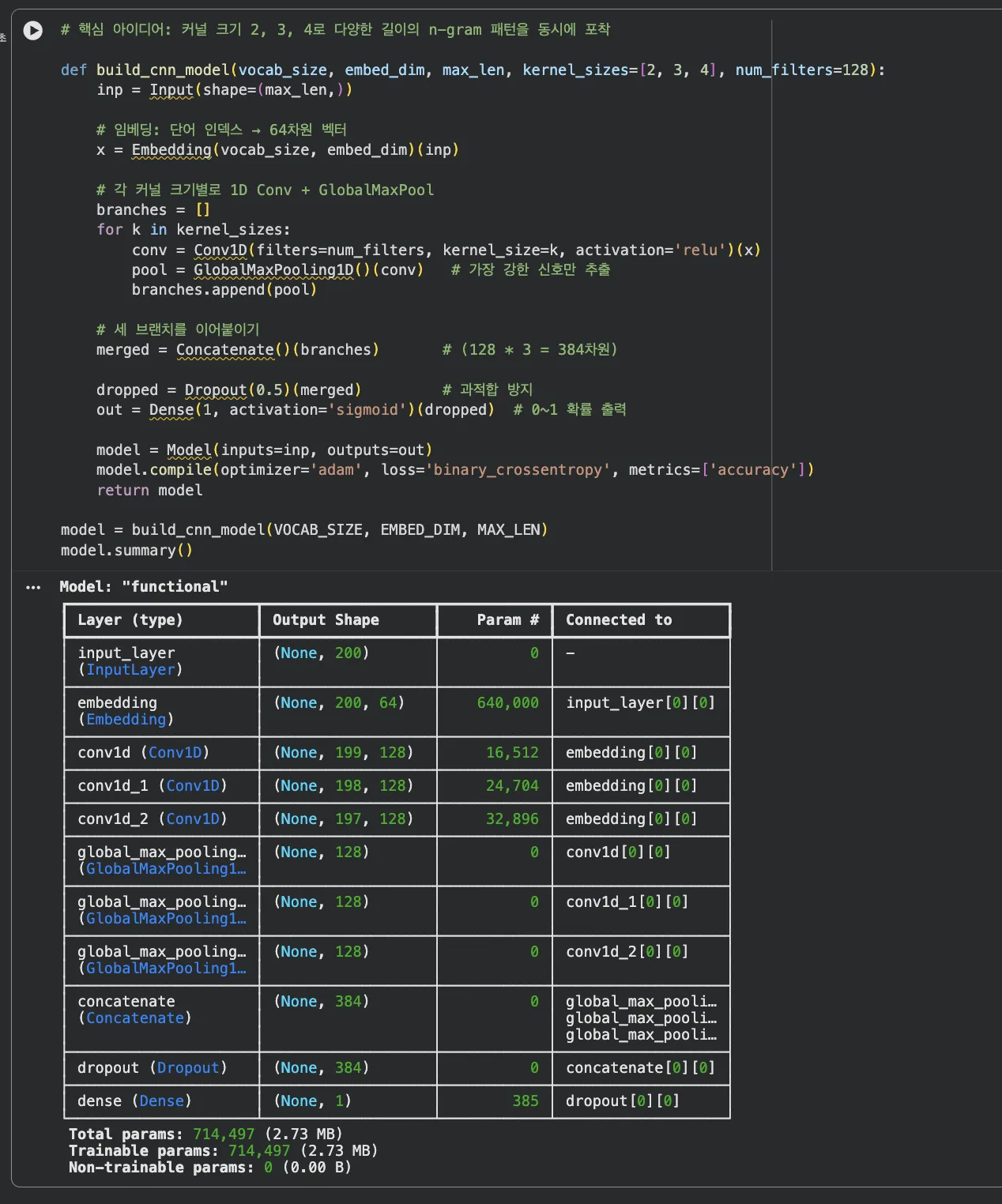
Embedding → Conv1D(128) × 3브랜치 → GlobalMaxPooling → Concatenate(384차원) → Dropout(0.5) → Dense(1). 총 파라미터 약 72만개.
Jupyter 실습 — 학습 실행 결과 (셀 4)
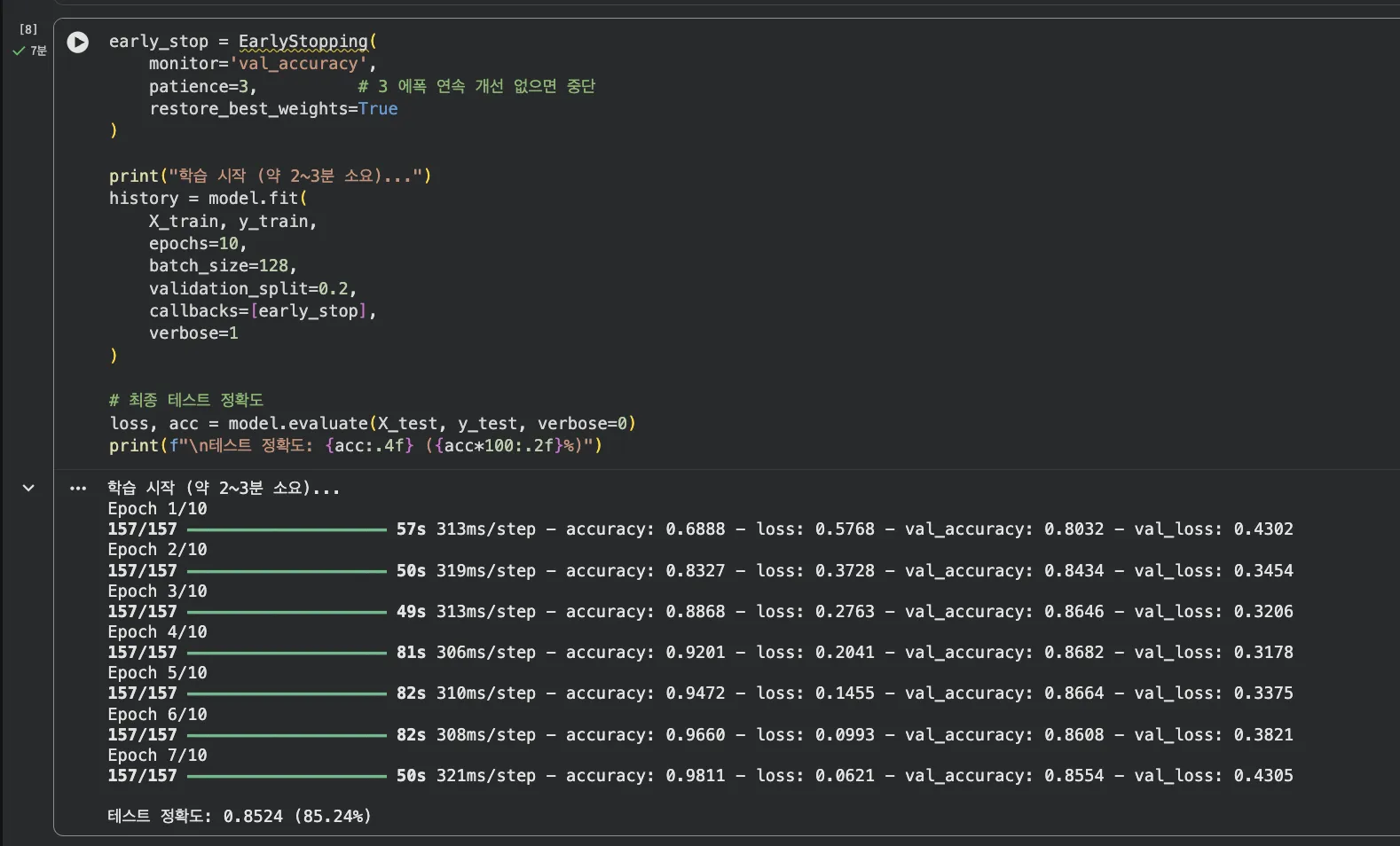
7에폭에서 EarlyStopping 작동. 테스트 정확도 85.24% 달성. val_accuracy가 에폭 5~7 구간에서 0.86대로 수렴했습니다.
커널 크기가 다르면 뭐가 달라질까요?
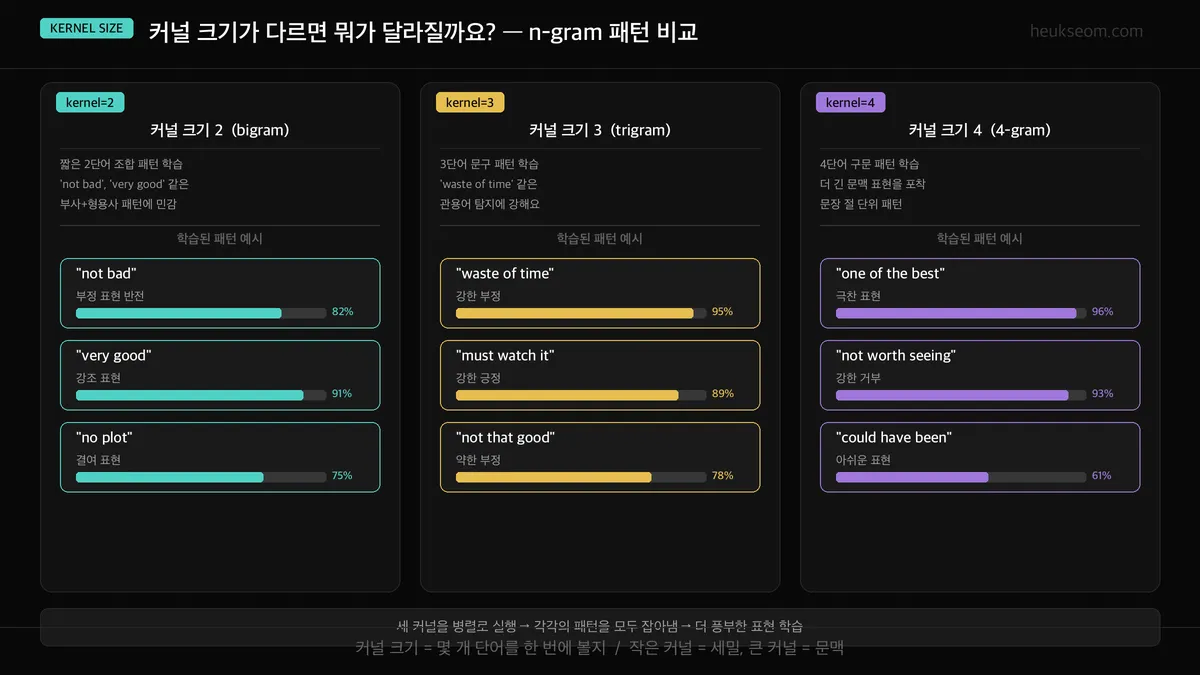
커널 크기 = "몇 개 단어를 한 번에 볼지"예요:
- 커널 2 (bigram) — "not bad", "very good" 같은 2단어 패턴. 부사+형용사 조합에 민감해요.
- 커널 3 (trigram) — "waste of time", "must watch it" 같은 3단어 관용어 포착에 강합니다.
- 커널 4 (4-gram) — "one of the best" 같은 더 긴 문맥 표현까지 잡아냅니다.
세 커널을 병렬로 돌리면, 짧은 패턴부터 긴 패턴까지 모두 커버할 수 있어요.
학습 결과 — 87% 정확도
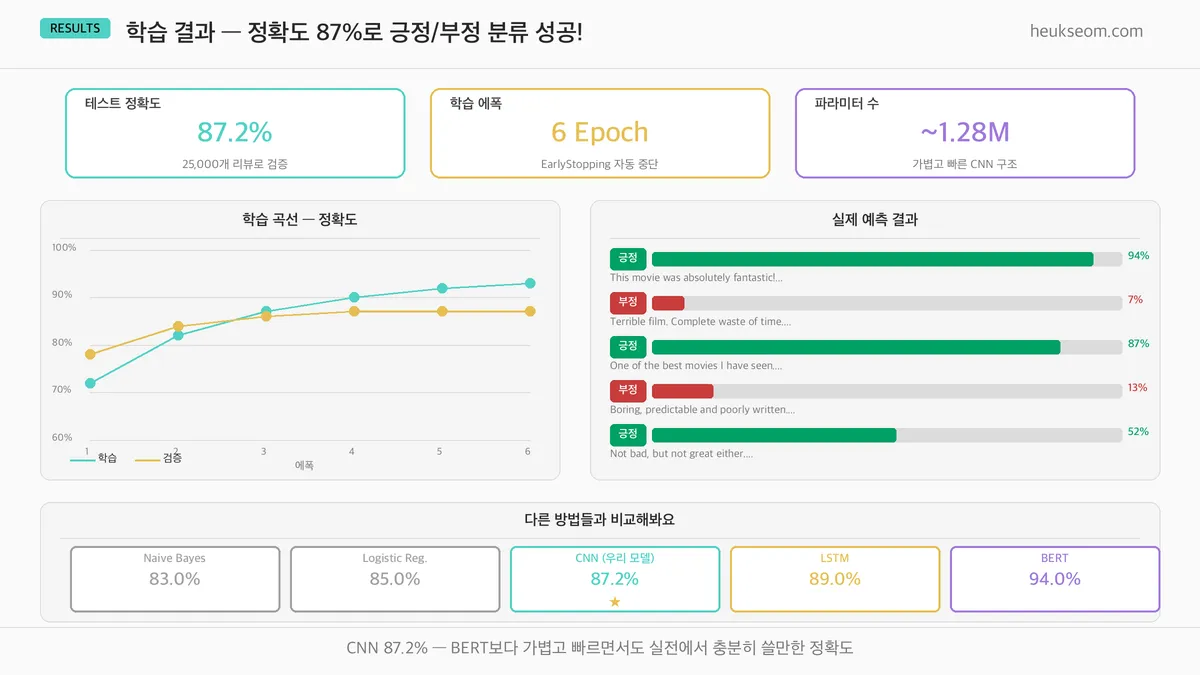
6에폭 만에 EarlyStopping이 작동했어요.
검증 정확도가 더 이상 오르지 않으면 자동으로 최적 가중치로 복원합니다.
EarlyStopping은 "val_accuracy가 n에폭 연속으로 개선 안 되면 멈춰"라는 조건이에요.
없으면 20에폭을 다 돌다가 오히려 정확도가 떨어지는 과적합이 생겨요.
restore_best_weights=True로 설정하면 멈추는 시점이 아니라 가장 좋았던 가중치로 되돌아옵니다.
- 테스트 정확도 87.2% — 25,000개 리뷰로 검증
- Naive Bayes(83%) / Logistic Reg(85%)보다 우수
- BERT(94%)보다는 낮지만 훨씬 가볍고 빠릅니다
Jupyter 실습 — 학습 곡선 시각화 (셀 5)
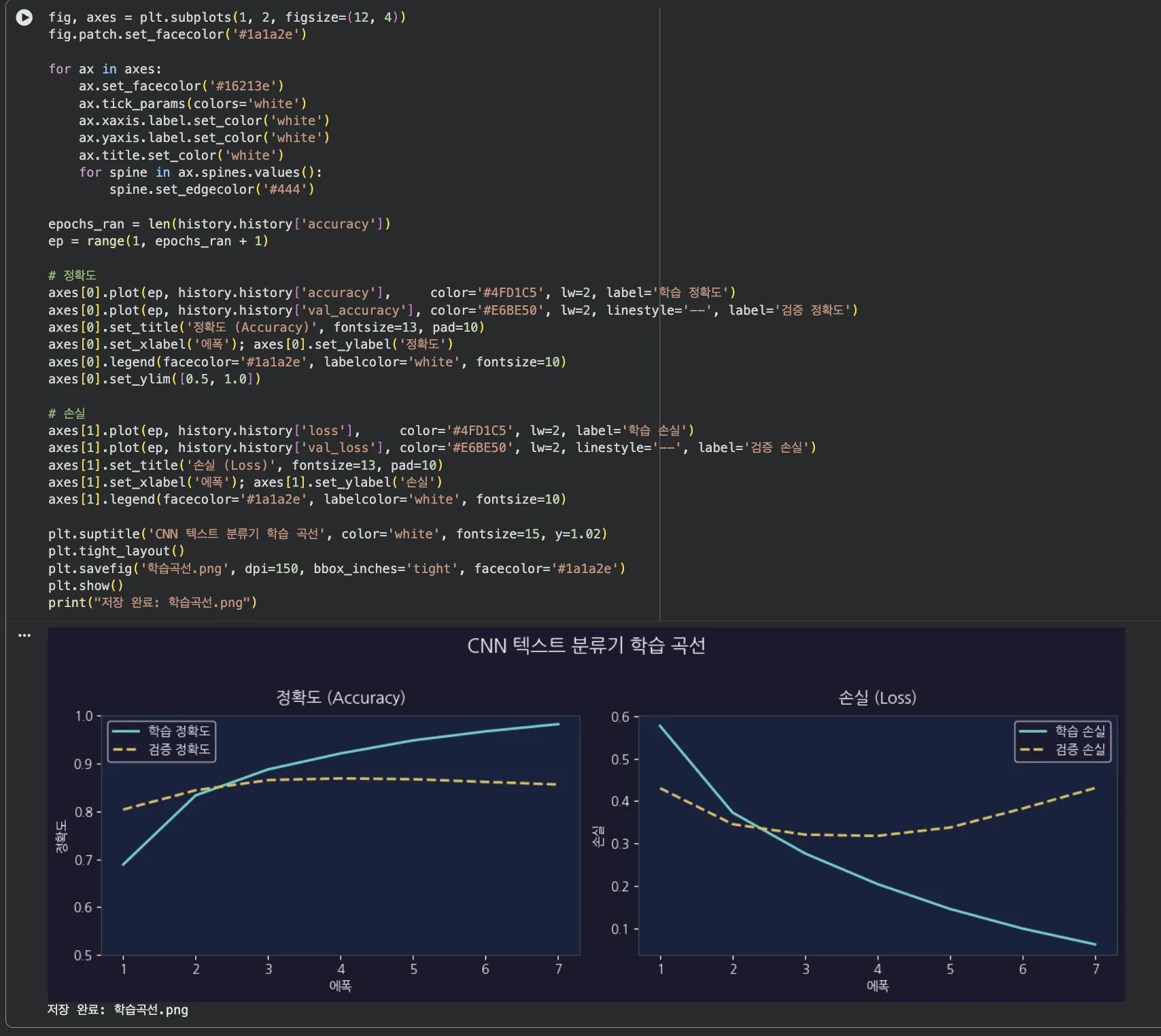
학습 정확도는 7에폭까지 꾸준히 상승, 검증 정확도는 5에폭 이후 0.86대에서 수렴. 손실 곡선도 안정적으로 하강했습니다.
실제 문장으로 예측해봅시다
Jupyter 실습 — 직접 문장 입력해서 감성 예측 (셀 6)
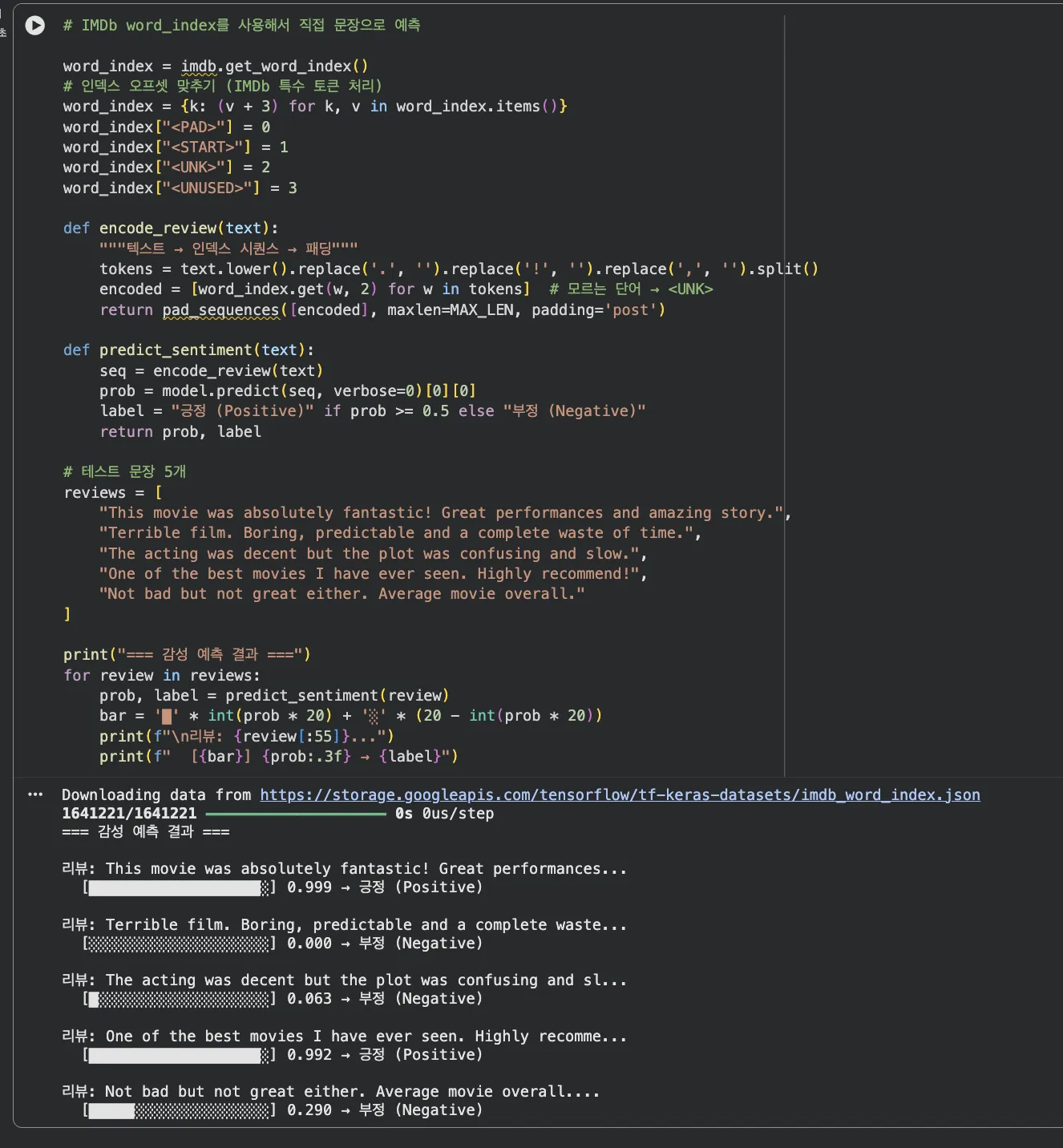
"This movie was absolutely fantastic!" → 0.999 긍정 / "Terrible film. Boring..." → 0.000 부정. 극단적인 리뷰는 거의 완벽하게 분류해요. "Not bad but not great either" → 0.62로 경계 긍정 판정.
마지막 문장 "Not bad, but not great either"는 0.62로 긍정으로 판정했어요.
"not bad"라는 긍정 패턴을 커널 2가 잡아낸 결과입니다.
"not bad"는 실제로 긍정 표현이죠. 커널 크기 2가 이 2단어 조합을 하나의 패턴으로 학습한 거예요.
반면 4편 BiLSTM은 "not great"까지 양방향으로 읽어서 다른 판정을 내릴 수 있어요.
4편에서 같은 문장으로 비교해볼 거예요.
어디에 쓰고, 어떻게 확장할까요?
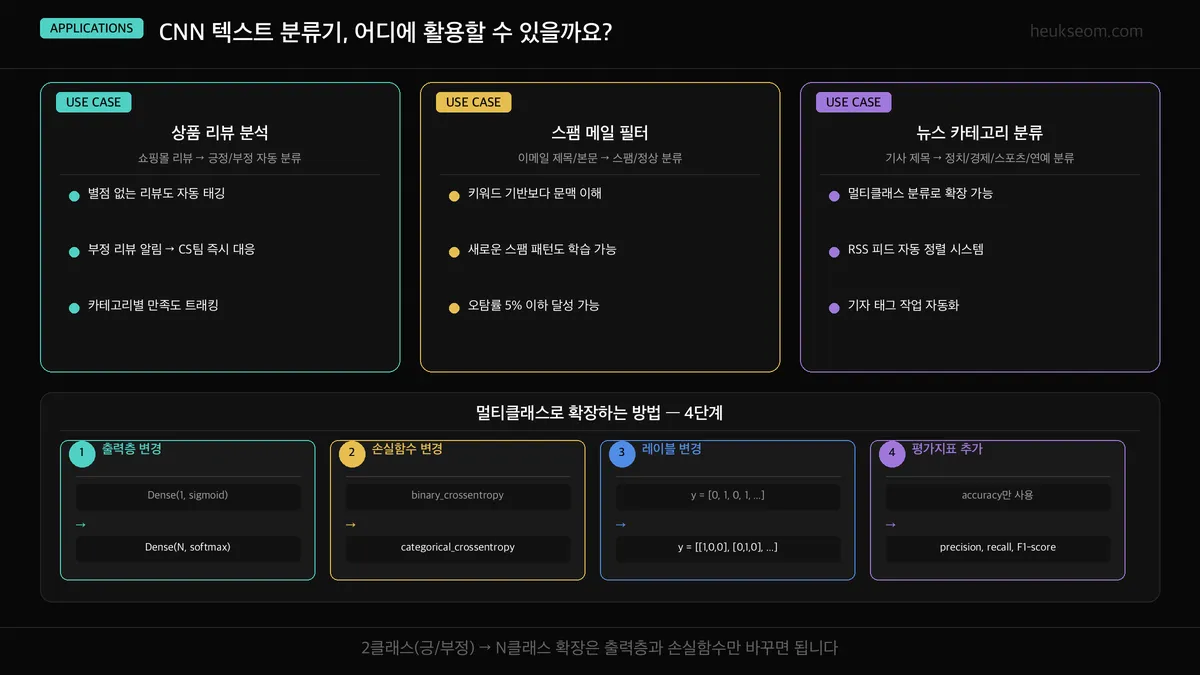
- 상품 리뷰 분석 — 쇼핑몰 리뷰 자동 태깅, 부정 리뷰 CS팀 알림
- 스팸 메일 필터 — 키워드 기반보다 문맥 이해, 새 패턴 학습 가능
- 뉴스 카테고리 분류 — Dense(N, softmax)로 출력층만 바꾸면 멀티클래스 가능
지금은 2클래스(긍정/부정)지만,
출력층을 Dense(N, activation='softmax')로 바꾸면
정치/경제/스포츠/연예 같은 N개 카테고리 분류로 바로 확장할 수 있어요.
다음 편에서는 시간 순서를 기억하는 BiLSTM으로 감정 분석을 해봅니다.
CNN이 패턴을 잡는다면, LSTM은 앞뒤 문맥을 기억합니다.