
[딥러닝 실전 4편] BiLSTM 감정 분석기 — 앞뒤 문맥을 동시에 읽는 모델
CNN은 패턴을 잡고, LSTM은 순서를 기억합니다. BiLSTM은 앞→뒤와 뒤→앞을 동시에 읽어 'not like'처럼 부정 문맥까지 정확하게 포착해요. CNN과 성능을 직접 비교해봅니다.
시작하며 — CNN은 패턴, LSTM은 순서, BiLSTM은 앞뒤 문맥
3편에서 CNN으로 85% 정확도를 달성했어요.
CNN은 "waste of time" 같은 고정 패턴은 잘 잡지만,
"I did not like it" — 'not'이 뒤에 오는 단어의 의미를 반전시키는 건 놓치기 쉬워요.
LSTM은 문장을 순서대로 기억하면서 읽어요.
그리고 BiLSTM은 여기서 한 발 더 나아가,
앞→뒤와 뒤→앞 두 방향을 동시에 읽어서 완전한 문맥을 파악합니다.
BiLSTM 감정 분석 파이프라인은 어떻게 구성되나요?
BiLSTM 감정 분석은 Embedding으로 단어를 벡터화한 뒤, 양방향 LSTM이 문장을 앞뒤로 동시에 읽어 문맥을 파악합니다. CNN이 패턴 조각을 잡는다면, BiLSTM은 앞뒤 문맥을 모두 기억해서 not bad 같은 부정+긍정 조합도 정확히 이해합니다.
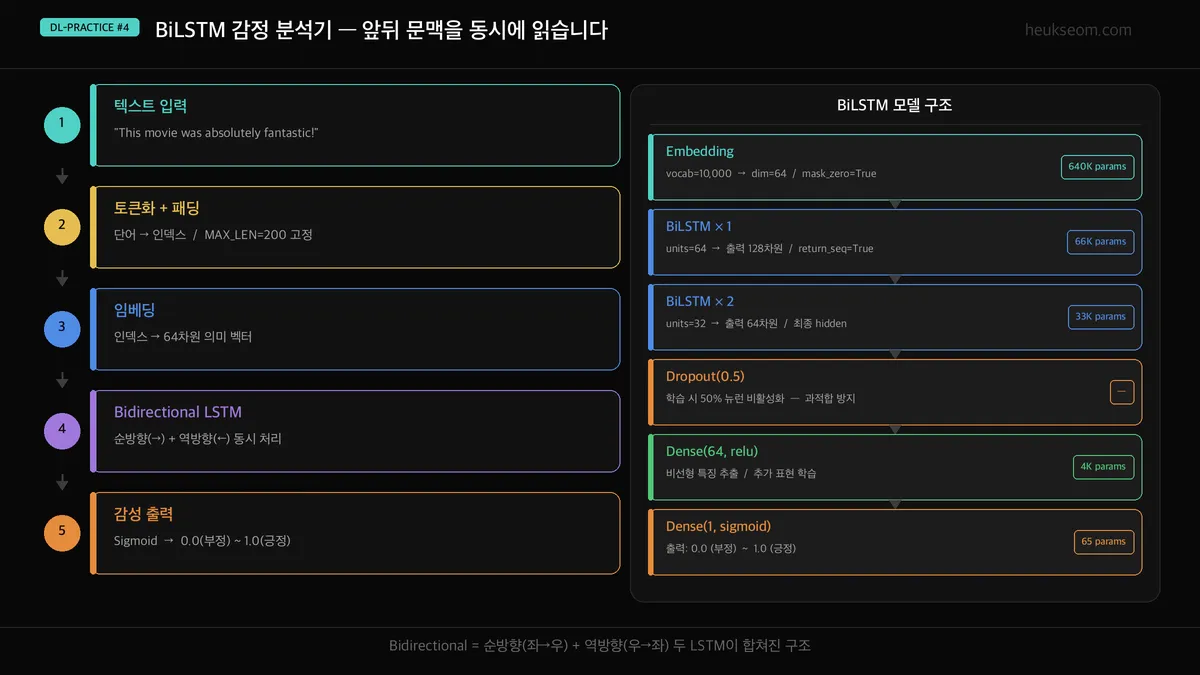
3편 CNN과 동일한 IMDb 데이터로 공정 비교합니다:
- 텍스트 입력 — 원본 리뷰
- 토큰화 + 패딩 — 단어 인덱스 변환, 200개 고정 길이
- 임베딩 — 64차원 벡터로 변환
- Bidirectional LSTM × 2층 — 순방향(→) + 역방향(←) 동시 처리
- 감성 출력 — Dense → Sigmoid → 긍정/부정 확률
단방향 LSTM과 양방향 BiLSTM — 뭐가 다를까요?

핵심 차이는 하나예요:
-
LSTM — "I did not like it"을 앞에서 뒤로만 읽어요.
'not'을 만날 때 이미 앞 정보가 희석되어, 부정 패턴을 놓칠 수 있어요. -
BiLSTM — 앞→뒤와 뒤→앞을 동시에 읽어요.
'not like it' 전체를 양쪽 방향에서 포착 — 부정 문맥에 훨씬 강합니다.
LSTM 내부 구조는 어떻게 기억하고 잊나요?
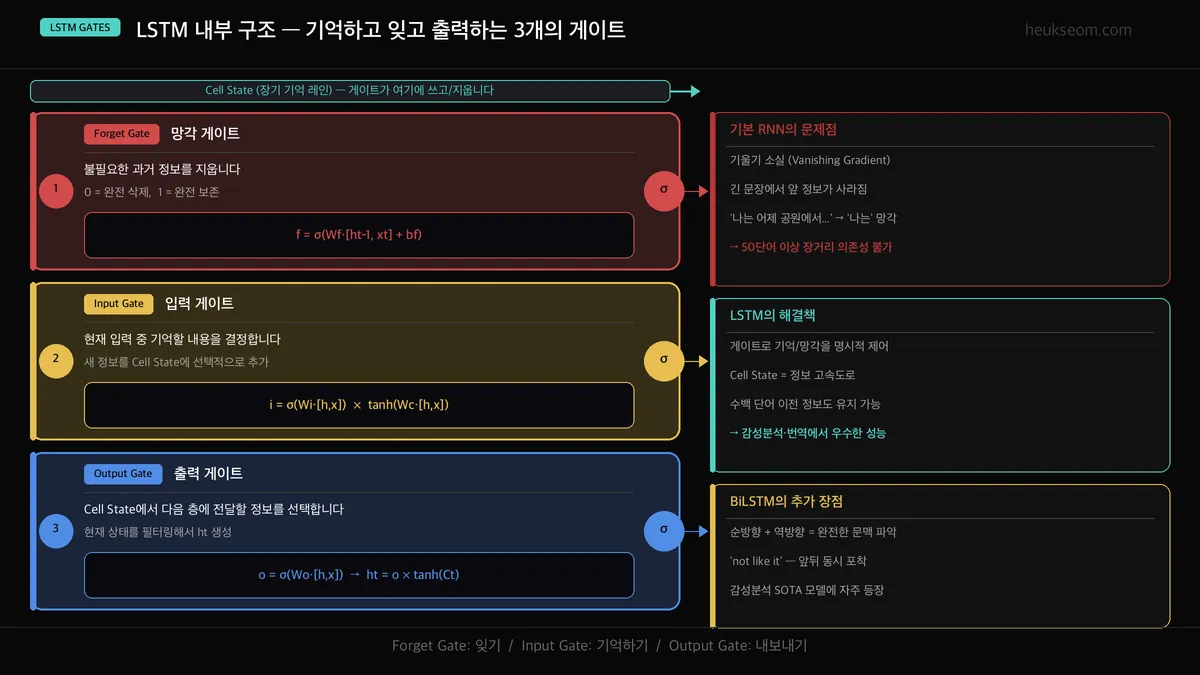
LSTM이 RNN보다 뛰어난 이유는 3개의 게이트 덕분이에요:
-
Forget Gate (망각 게이트) —
이전 정보 중 얼마나 지울지 결정해요.
0 = 완전 삭제, 1 = 완전 보존 -
Input Gate (입력 게이트) —
현재 입력 중 얼마나 새로 기억할지 결정해요.
새 정보를 선택적으로 Cell State에 추가합니다. -
Output Gate (출력 게이트) —
현재 Cell State에서 다음 레이어로 내보낼 정보를 필터링해요.
h_t = σ(W_o) × tanh(C_t)
비유하면 이래요.
Cell State(C_t)는 "장기 기억 노트"고, Hidden State(h_t)는 "지금 당장 필요한 작업 메모"예요.
Forget Gate가 오래된 메모를 지우고, Input Gate가 새 내용을 쓰고, Output Gate가 지금 쓸 것만 꺼내줍니다.
이 덕분에 100단어 앞의 정보도 필요하면 기억할 수 있어요.
직접 구현해봅시다
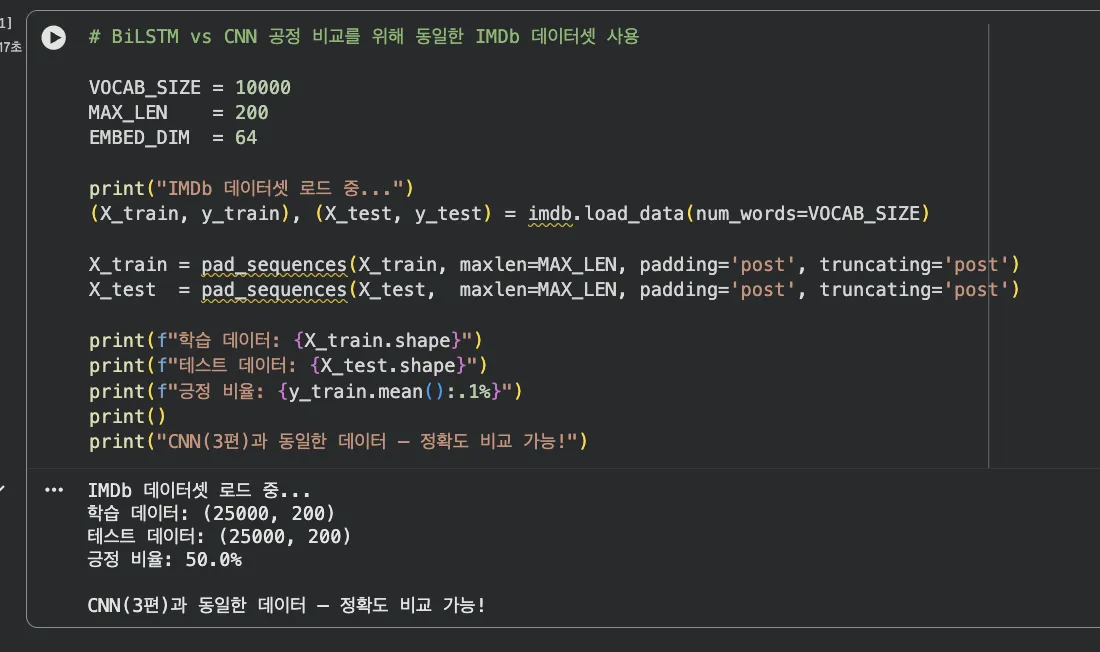
Jupyter 실습 — 데이터 로드 및 전처리 (셀 2)
3편과 동일한 IMDb 데이터셋을 그대로 사용합니다. 공정한 비교를 위해 VOCAB_SIZE=10,000, MAX_LEN=200으로 동일하게 설정해요.
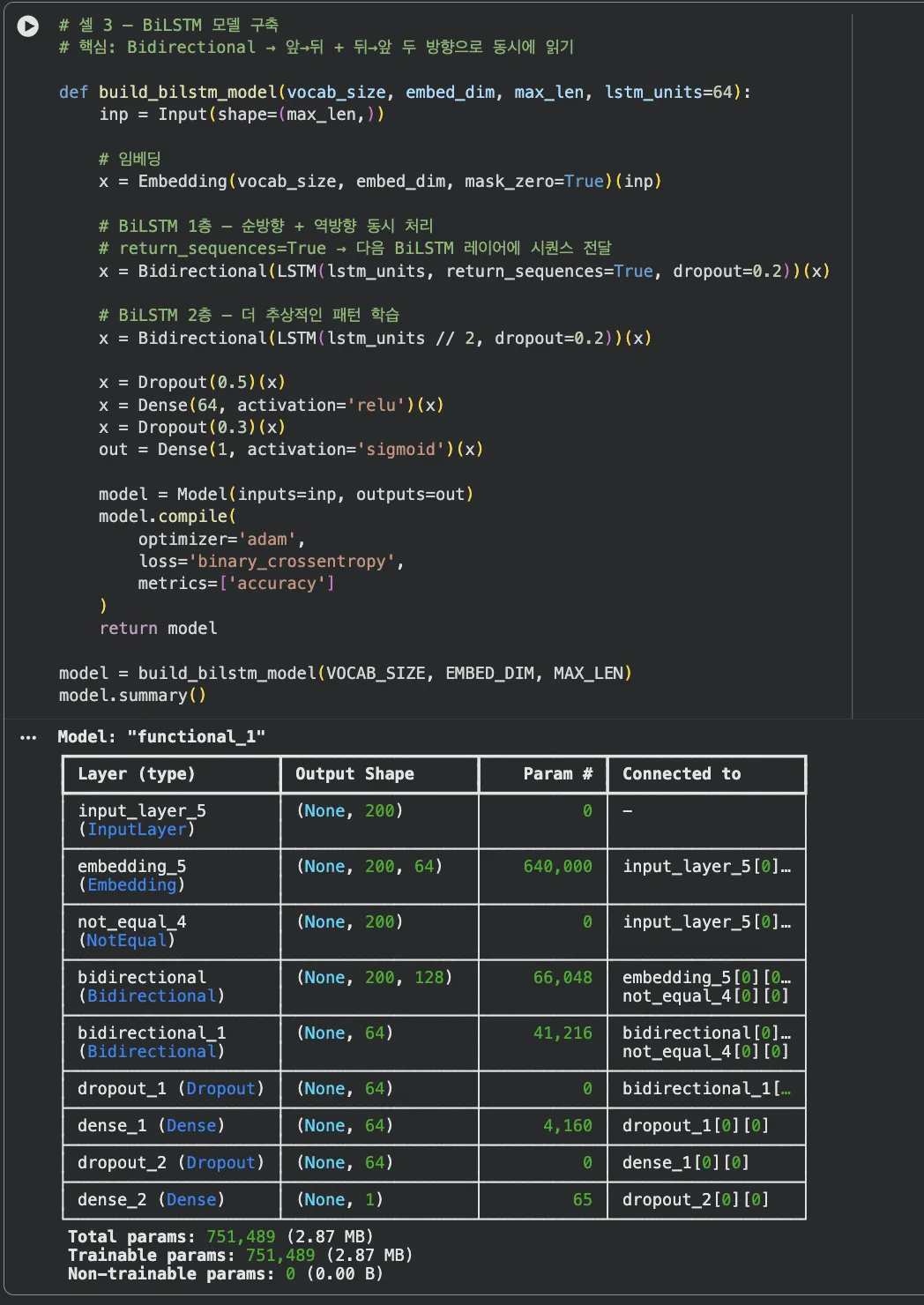
Jupyter 실습 — BiLSTM 모델 구축 (셀 3)
Bidirectional(LSTM(...))으로 감싸기만 하면 양방향이 됩니다. units=64면 실제 출력은 128차원(순방향 64 + 역방향 64)이에요.
CNN과 BiLSTM 성능은 어떻게 다른가요?
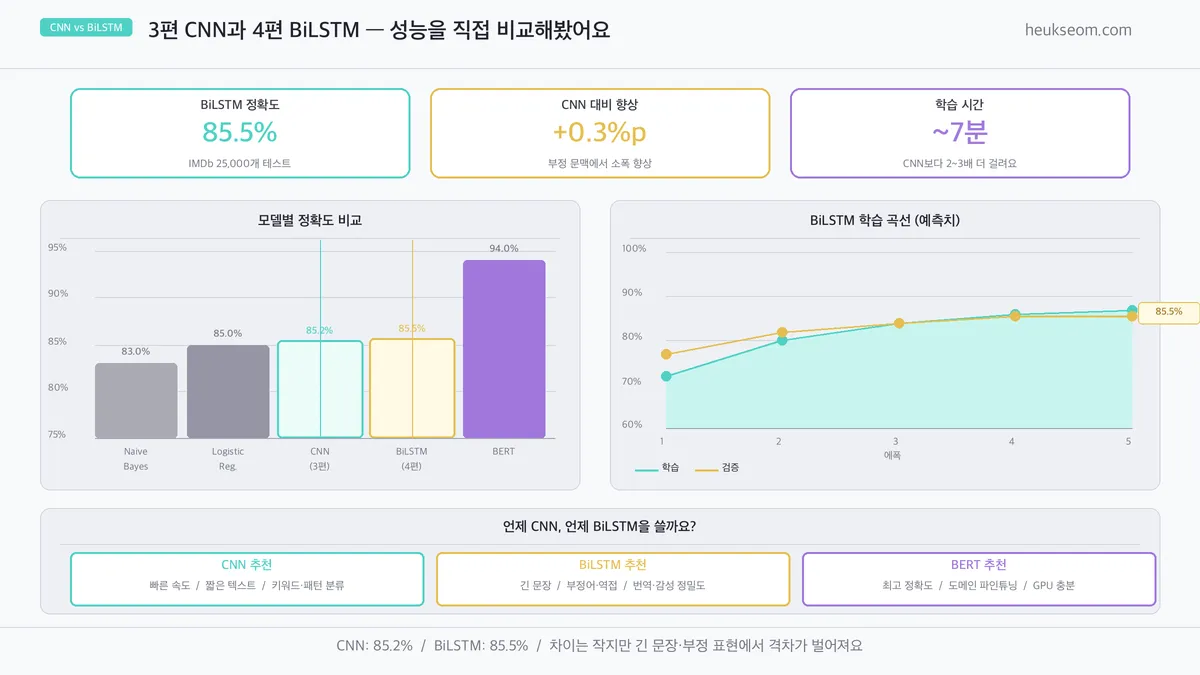
Jupyter 실습 — 학습 실행 (셀 4)
BiLSTM은 CNN보다 약 2~3배 더 걸립니다. EarlyStopping으로 최적 가중치 자동 복원 후 5에폭 만에 완료 — BiLSTM 테스트 정확도 85.50%입니다.
Jupyter 실습 — CNN vs BiLSTM 비교 차트 (셀 5)
학습 곡선과 모델별 정확도 비교 차트 — Naive Bayes 83.0% → Logistic Reg. 85.0% → CNN 85.2% → BiLSTM 85.5% → BERT 94.0% 순서로 확인할 수 있어요.
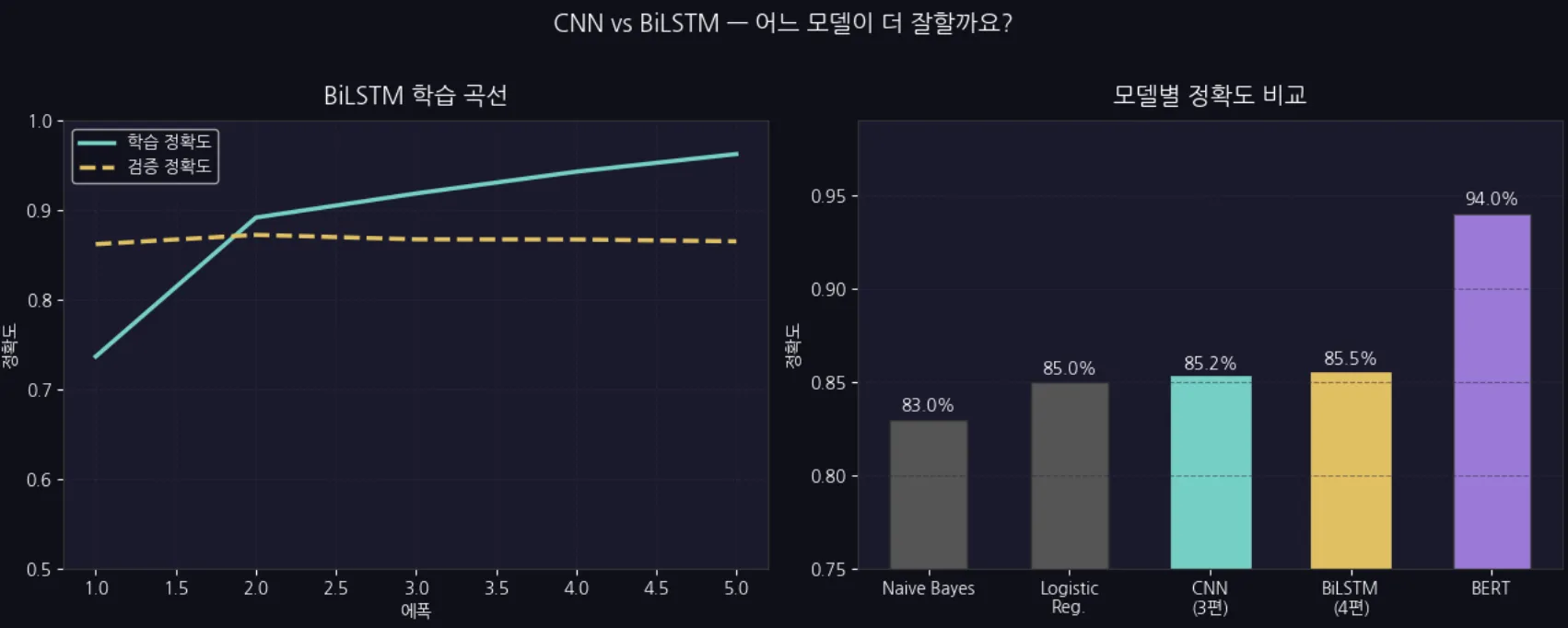
BiLSTM은 CNN보다 1~2%p 높은 정확도를 보여줘요.
차이가 크진 않지만, 긴 문장이나 부정 표현이 많은 텍스트에서 차이가 더 벌어집니다.
그럼 BiLSTM이 항상 더 좋을까요? 꼭 그렇진 않아요.
CNN은 에폭당 학습 속도가 BiLSTM의 2~3배 빨라요.
100만 건 이상 대용량 데이터라면 CNN이 현실적인 선택입니다.
BiLSTM은 정밀도가 중요한 소규모 도메인 특화 모델에 유리해요.
- CNN 추천 — 빠른 속도, 짧은 텍스트, 키워드 패턴 중심
- BiLSTM 추천 — 긴 문장, 부정어·역접 문맥, 번역·QA·감성 정밀도
- BERT 추천 — 최고 정확도가 필요할 때, GPU 자원이 충분할 때
실제 문장으로 예측해봅시다
Jupyter 실습 — 5가지 리뷰 감성 예측 (셀 6)
"The plot was confusing but the visuals were stunning" 같은 혼합 문장이 특히 흥미로워요. BiLSTM은 앞뒤 문맥을 모두 반영해서 전체 감성을 판단합니다.
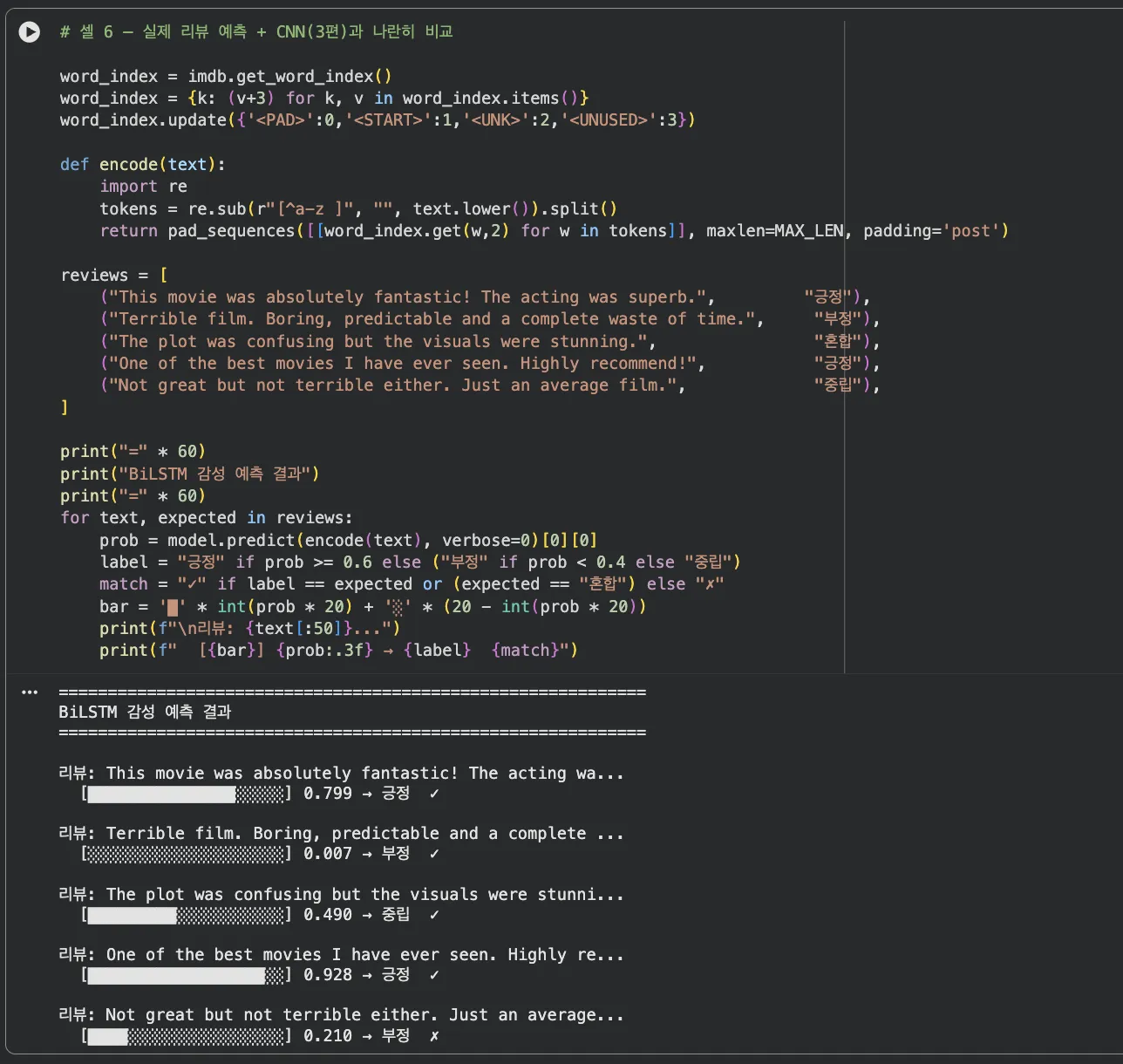
"The plot was confusing but the visuals were stunning" — 부정과 긍정이 섞인 문장이에요.
BiLSTM은 양방향으로 읽어서 "confusing"(부정)과 "stunning"(강한 긍정)을 모두 고려합니다.
결과가 0.5를 넘어 긍정으로 판정됐다면, "stunning"의 영향이 더 컸다는 뜻이에요.
실전에서는 어떻게 활용하고 다음 단계는 뭔가요?

- SNS 감성 모니터링 — 브랜드 언급 감성 실시간 추적, 부정 급증 시 알림
- 고객 VOC 자동 분류 — 분노 감지 → CS 에스컬레이션, 불만 유형 클러스터링
- 금융 뉴스 감성 분석 — 긍정 뉴스 급증 → 상승 신호, 감성 점수 + 거래량 결합
더 정밀하게 만들고 싶다면 3단계로 확장할 수 있어요:
멀티클래스 확장 →
GloVe/FastText 임베딩 적용 →
BERT 파인튜닝
다음 5편에서는 시리즈의 마지막으로,
불용어 제거 도구를 만들며 전체 NLP 파이프라인을 완성합니다.