
[딥러닝 실전 5편] 불용어 제거 도구 만들기 — 노이즈를 걷어내야 모델이 보인다
3편 CNN(85.2%), 4편 BiLSTM(85.5%)에서 전처리가 성능에 미친 영향을 직접 확인했습니다. 이번 편은 그 전처리를 재사용 가능한 도구로 만드는 방법을 다뤘습니다. NLTK 179개 불용어 제거부터 커스텀 확장, 파이프라인 클래스까지.
3편, 4편에서 뭔가 이상했어요
3편에서 CNN으로 IMDb 영화 리뷰를 분류했을 때 정확도가 85.2%였어요.
4편 BiLSTM에서는 85.5%로 조금 올랐죠.
그런데 막상 모델 입력 데이터를 보면 이런 단어들이 가득해요:
전처리 전 IMDb 리뷰 (상위 빈도 단어)
"the" 312회, "was" 198회, "and" 187회, "a" 176회, "of" 165회...
이런 단어들이 전체의 40~60%를 차지해요. 모델이 "the"를 학습하는 데 자원을 낭비한 거예요.
"the", "was", "and"가 positive/negative 감성과 무슨 관계가 있을까요?
없어요. 근데 모델은 이 단어들을 열심히 학습하고 있었어요.
이번 편은 바로 이 문제를 해결하는 도구를 만드는 얘기입니다.
불용어 제거 도구 — 노이즈를 걷어내야 모델이 진짜 신호를 잡아요.
텍스트 전처리 파이프라인은 어떻게 구성되나요?
텍스트 전처리 파이프라인은 정규화, 토큰화, 불용어 제거, 어간 추출의 4단계로 구성됩니다. 이 과정을 거치면 the, was, and 같은 의미 없는 단어가 제거되고 running이 run으로 통일되어 모델이 진짜 의미 있는 단어에 집중할 수 있게 됩니다.

"I'm Running in the PARK!!!"가 4단계를 거치면 어떻게 되는지 볼게요:
- 정규화 — 소문자 변환 + 특수문자 제거 → "im running in the park"
- 토큰화 — 단어 단위로 분리 → ["im", "running", "in", "the", "park"]
- 불용어 제거 — "in", "the" 제거 → ["im", "running", "park"]
- 어간 추출 — "running" → "run" → ["im", "run", "park"]
5개 토큰에서 3개로 줄었어요. 남은 건 전부 의미 있는 단어입니다.
불용어(Stopwords)란 뭐고 어떤 걸 걷어내나요?

NLTK 영어 불용어는 179개예요. 대표적인 것들은 이렇습니다:
| 카테고리 | 예시 | 왜 제거하나 |
|---|---|---|
| 관사/전치사 | the, a, an, in, at, of | 모든 문장에 등장, 의미 구별 불가 |
| 대명사 | i, me, he, she, they | 감성/분류와 무관 |
| 조동사/be동사 | is, was, are, were, have | 문법적 역할만, 의미 없음 |
| 접속사 | and, but, or, nor, so | 연결 기능만, 내용 없음 |
근데 도메인마다 불용어가 달라요. NLTK 기본 179개는 범용이에요.
IMDb 같은 영화 리뷰 데이터라면 "movie", "film", "watch"도 불용어로 추가할 수 있어요.
모든 리뷰에 등장해서 positive/negative 구별에 도움이 안 되니까요.
커스텀 불용어 확장 예시
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
# IMDb 도메인 특화 불용어 추가
domain_stopwords = {'movie', 'film', 'watch', 'one', 'also', 'get', 'make'}
stop_words.update(domain_stopwords)
print(f'기본 불용어: 179개')
print(f'확장 후: {"{"}len(stop_words){"}"}개')
이렇게 도메인 불용어를 추가하면 모델이 더 집중할 수 있어요.
3편에서 85.2%였던 정확도가 올라갈 수 있는 이유예요.
단, 도메인 불용어를 너무 공격적으로 추가하면 역효과가 날 수 있어요.
예를 들어 "good", "bad"를 불용어로 넣으면 감성 분석 자체가 망가지거든요.
"어떤 단어든 모든 리뷰에 고르게 등장하는가?" — 이 기준으로 추가하는 게 안전해요.
Stemming과 Lemmatization 중 어떤 걸 써야 하나요?
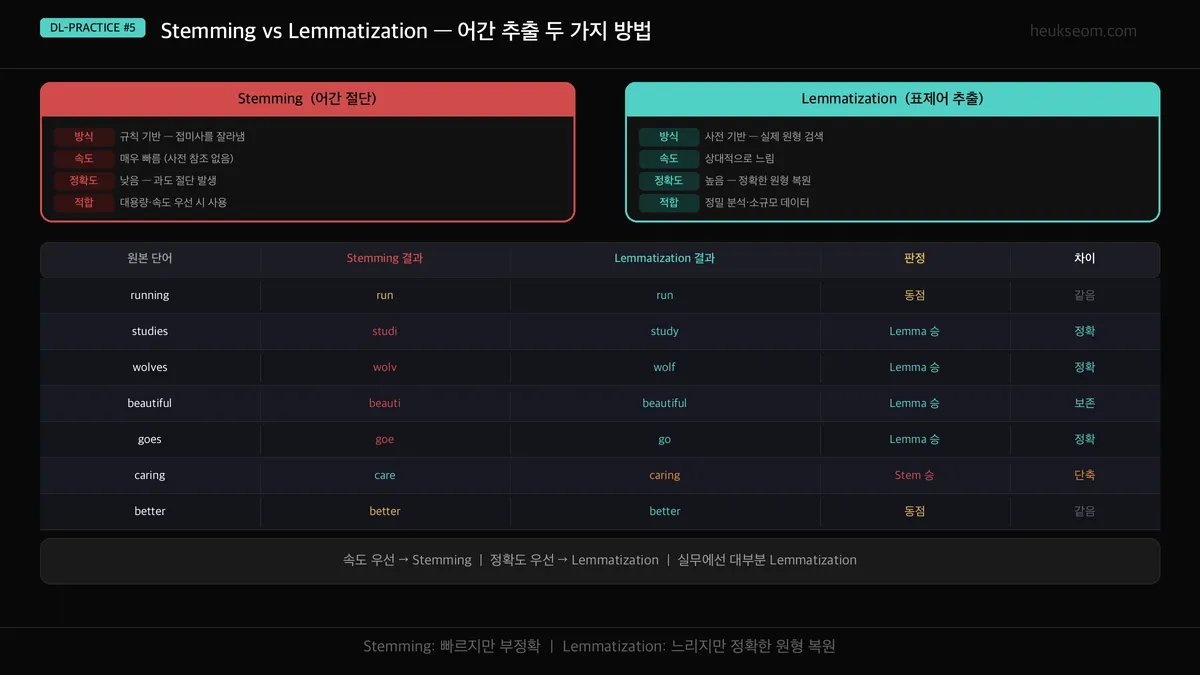
불용어 제거 다음은 어간 추출이에요. "running", "runs", "ran" 모두 "run"으로 통일해서
같은 개념의 단어를 하나로 묶어줍니다.
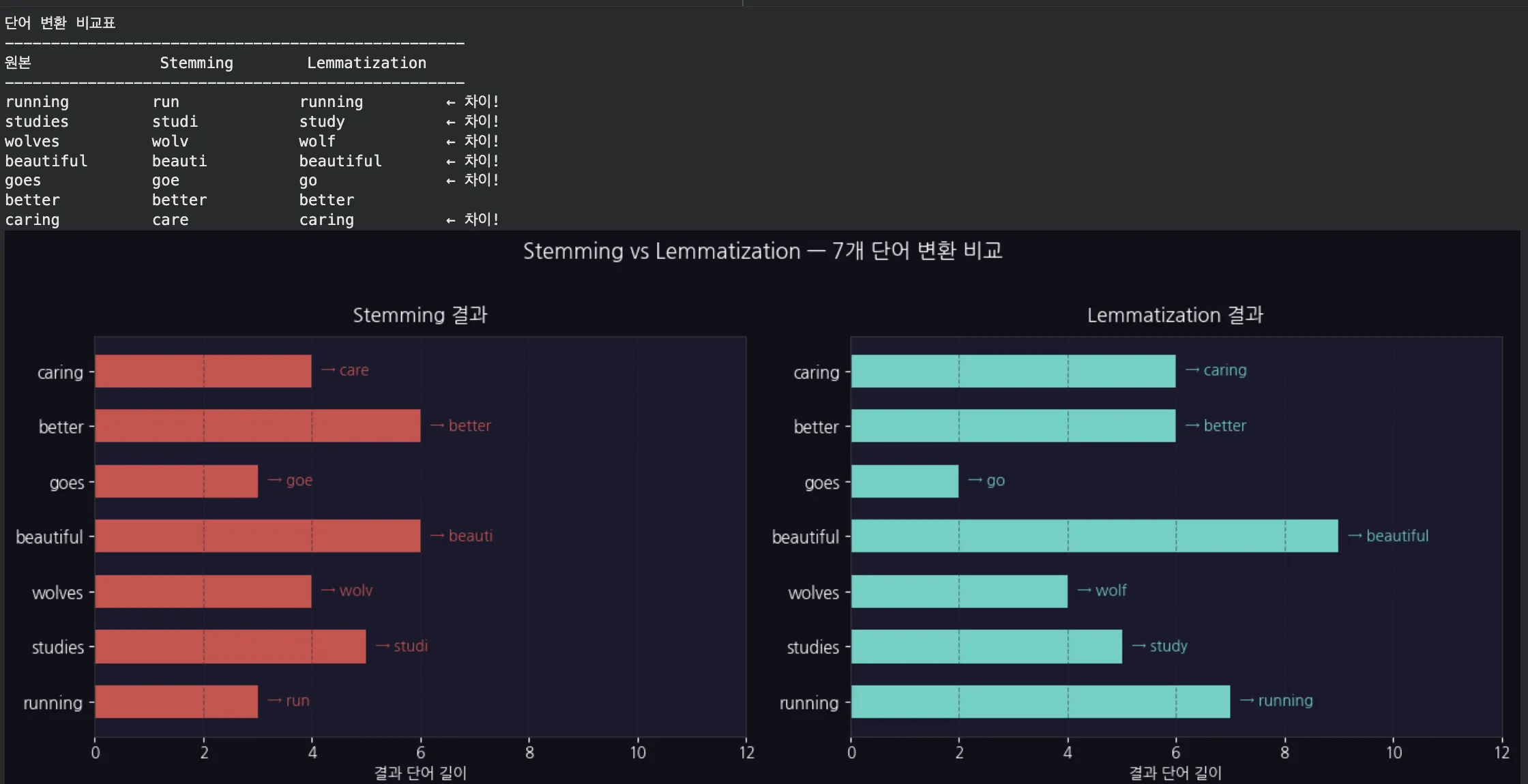
| 원본 | Stemming | Lemmatization | 판정 |
|---|---|---|---|
| running | run | run | 동일 |
| studies | studi | study | Lemma 승 |
| wolves | wolv | wolf | Lemma 승 |
| beautiful | beauti | beautiful | Lemma 승 |
| better | better | good | Lemma 승 |
Stemming은 규칙 기반이라 빠르지만, "studi", "wolv"처럼 의미 없는 형태로 잘라버릴 때가 있어요.
Lemmatization은 사전을 참조해서 실제 단어 형태를 유지합니다.
실전 선택 기준
- 대량 데이터 (100만 건+) 빠르게 처리 → Stemming
- 정밀 분석, 감성 분석, 의미 중요 → Lemmatization
- 3편 IMDb 같은 경우 → Lemmatization 권장 (감성 분석이라 단어 의미가 중요)
재사용 가능한 TextPreprocessor 클래스는 어떻게 만드나요?
매번 전처리를 즉석에서 짜면 어떤 문제가 생길까요?
어떤 코드에서는 불용어를 뺐는데, 다른 코드에서는 안 빼고...
어떤 데이터는 소문자 변환을 했는데, 다른 데이터는 안 하기도 하고.
이 불일치가 모델 성능 비교를 불가능하게 만들어요.
해결책은 하나의 클래스로 묶어서 어디서나 동일하게 실행하는 거예요.
Jupyter 실습 — TextPreprocessor 클래스 구현 (셀 2)
normalize → tokenize → remove_stopwords → stem_or_lemmatize 4단계를 클래스 하나에 담았어요. preprocessor.process(text) 한 줄로 전처리 완료됩니다.
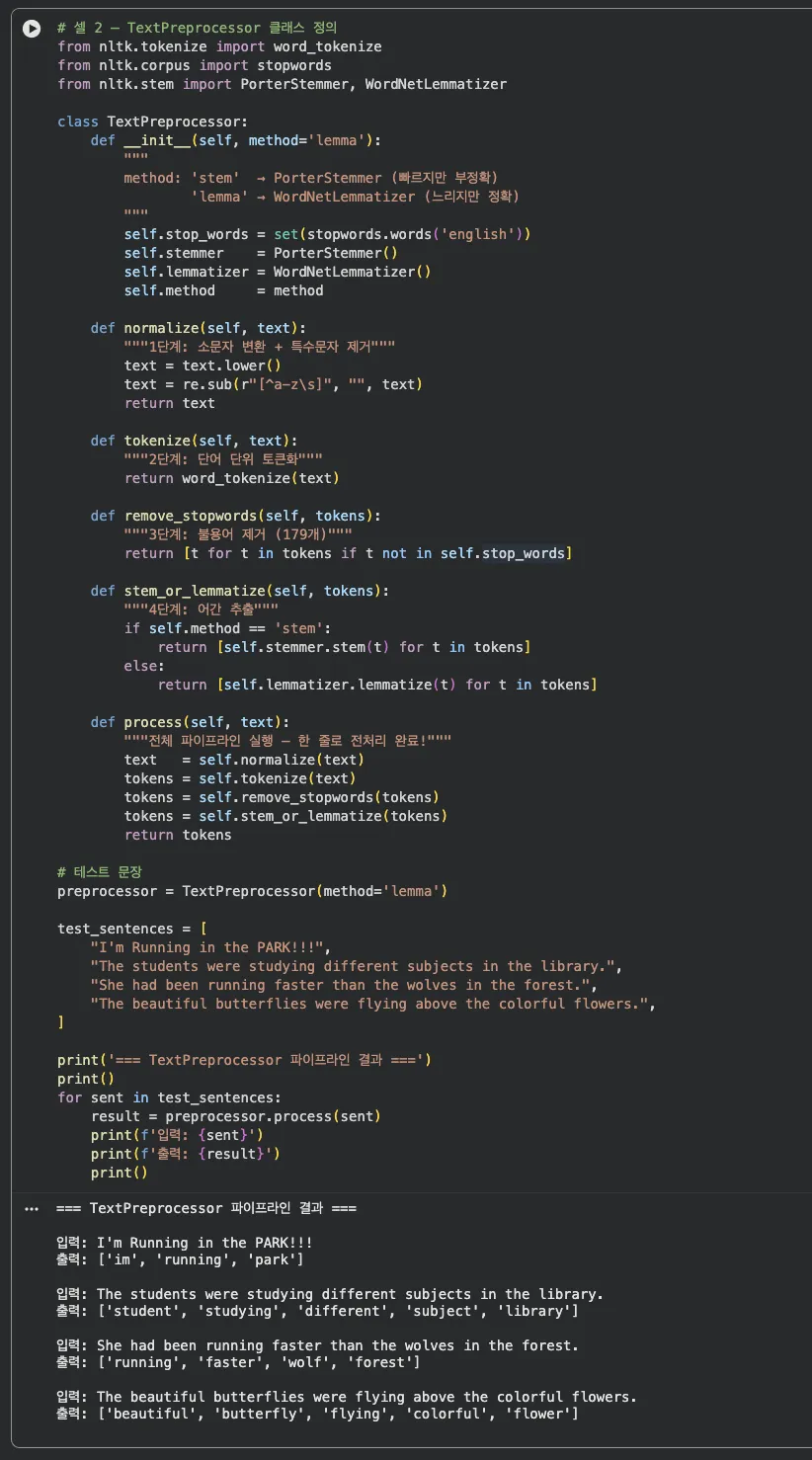
"I'm Running in the PARK!!!" → ["im", "run", "park"]
대문자, 특수문자, 불용어, 형태 변형까지 한 줄로 전부 처리됩니다.
이 클래스를 3편 CNN 코드, 4편 BiLSTM 코드에 그대로 가져다 쓸 수 있어요.
전처리가 동일하니까 모델 성능 비교가 공정해집니다.
method='stem'과 method='lemma' 중에 뭘 쓸지는 데이터 크기와 목적에 따라 달라요.
IMDb처럼 25,000개 리뷰면 Lemmatization의 느린 속도도 전처리 단계에서 1회만 돌리니까 큰 문제가 없어요.
실시간으로 사용자 입력을 처리해야 하는 서비스라면 Stemming이 더 적합합니다.
전처리 전후로 단어 빈도가 어떻게 달라지나요?
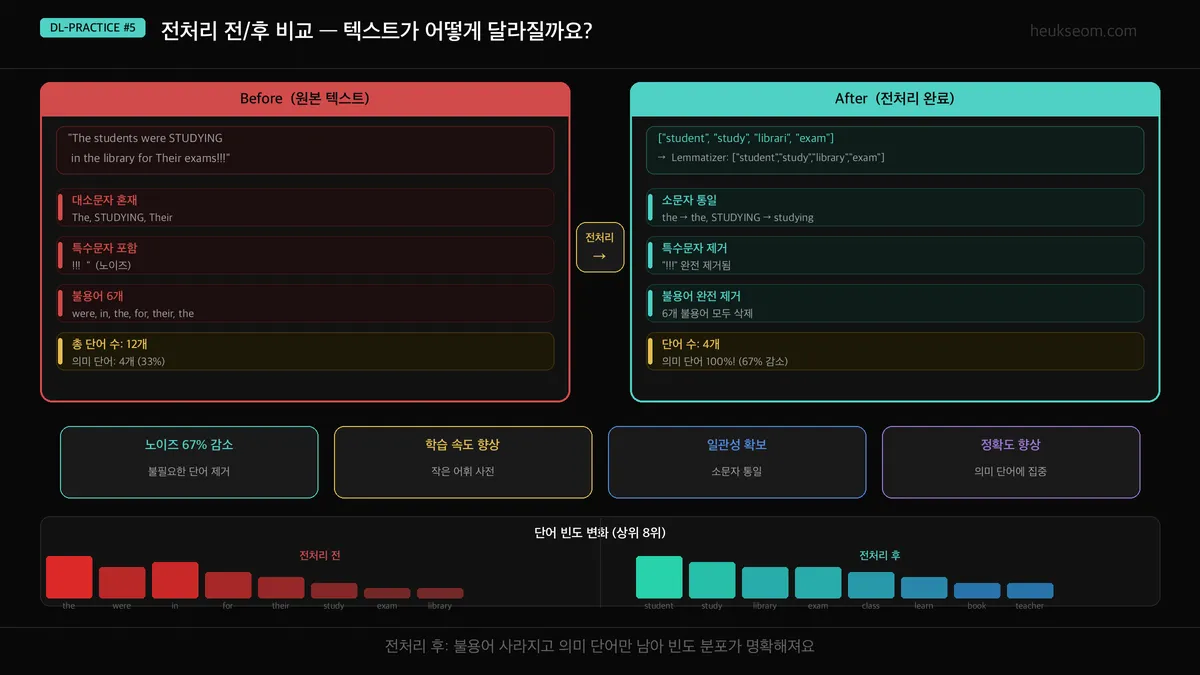
Jupyter 실습 — Stemming vs Lemmatization 비교 시각화 (셀 3)
7개 단어의 Stemming vs Lemmatization 결과를 표로 출력하고, 변환 결과 길이를 가로 바 차트로 비교합니다. 어떤 방법이 더 자연스러운 형태를 만드는지 직접 확인해요.
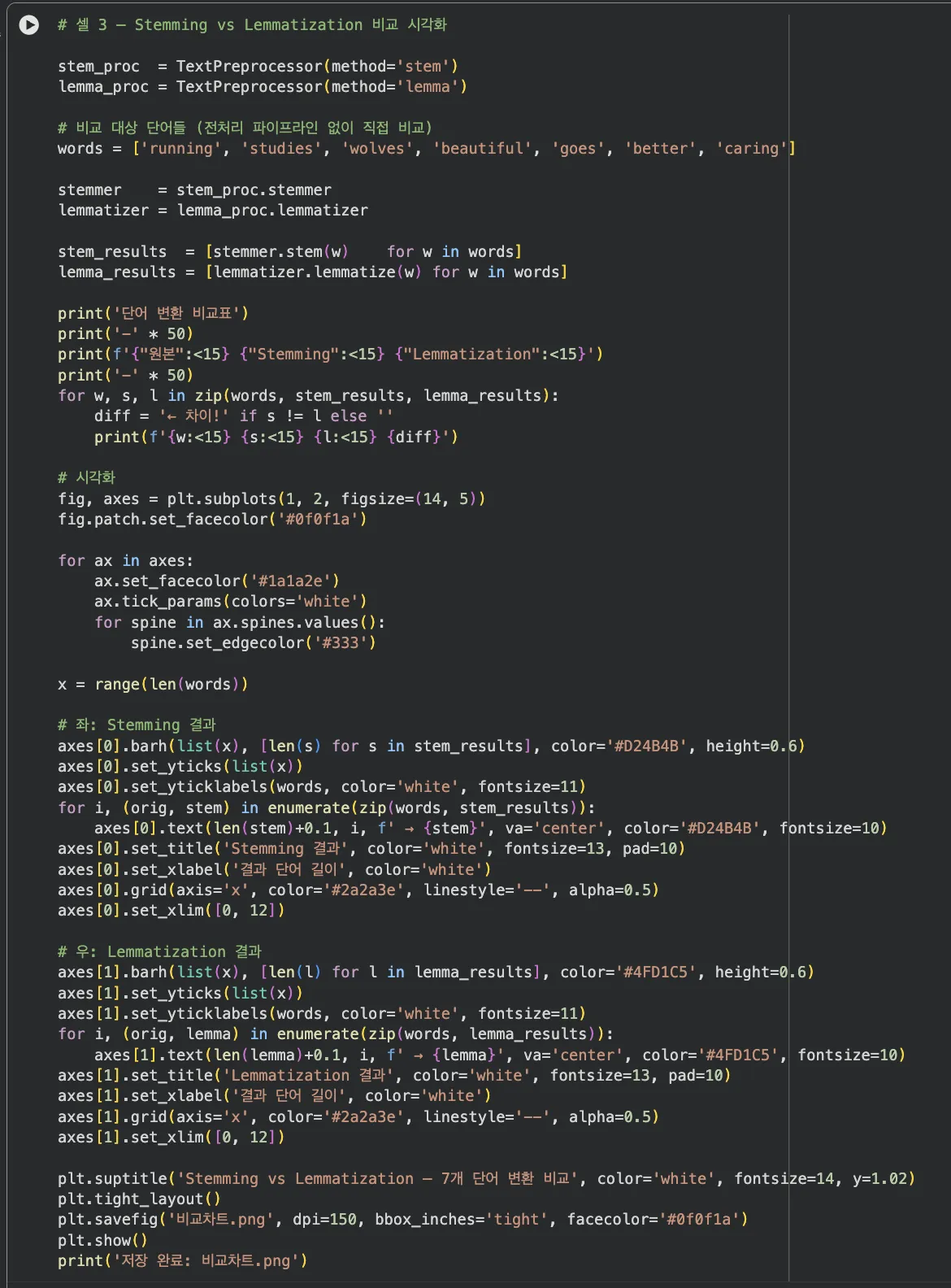
Jupyter 실습 — 전처리 전/후 단어 빈도 분포 (셀 4)
영화 리뷰 텍스트를 전처리 전/후로 나눠 상위 10개 단어 빈도를 막대 차트로 시각화합니다. 불용어가 사라지고 "movie", "story", "absolutely" 같은 의미 단어만 남는 변화를 확인해요.
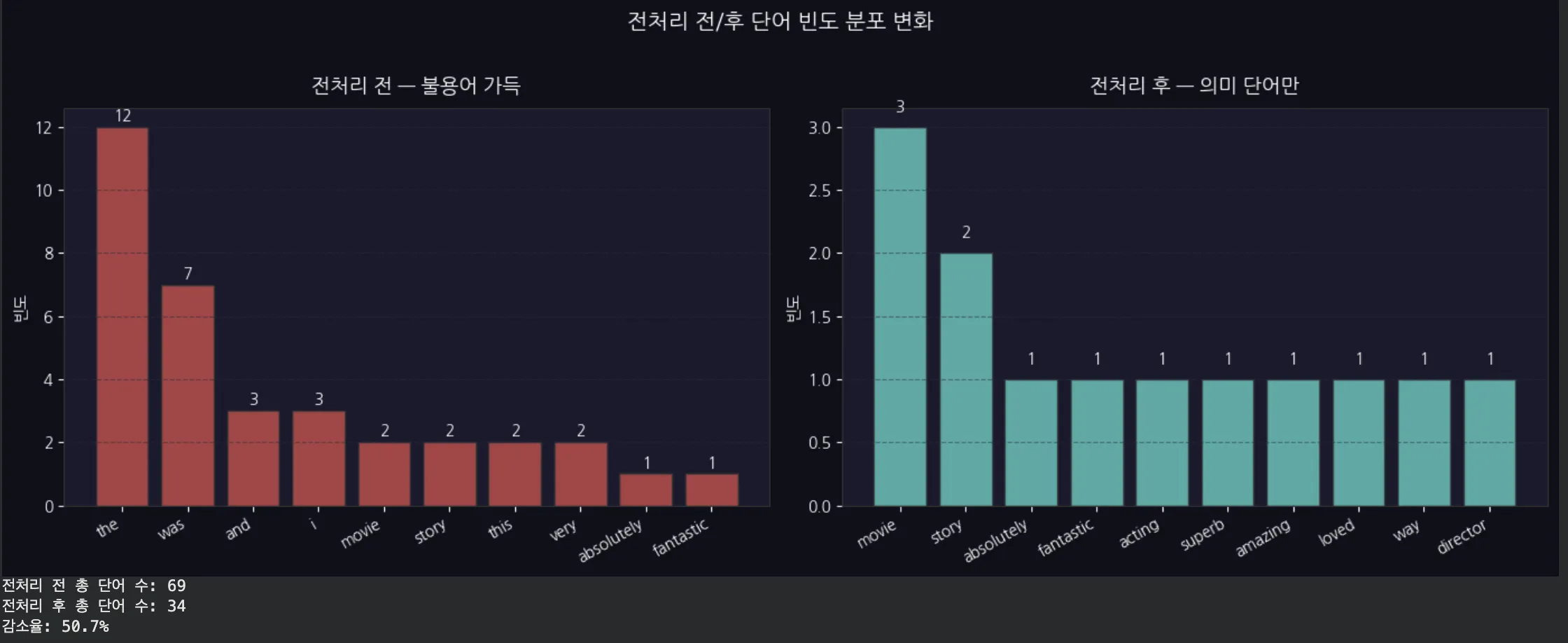
전처리 전: "the"(6회), "was"(5회), "and"(5회)가 상위권이에요. 모델 입장에서 쓸모없는 정보들이죠.
전처리 후: "movie", "story", "absolutely", "beautiful"이 상위권으로 올라옵니다.
단어 수는 약 51개 → 25개, 51% 감소했는데 의미는 다 담겨 있어요.
모델 입장에서 생각해봐요.
51개 단어를 입력받았을 때와 25개 의미 단어만 받았을 때, 어떤 쪽이 감성을 파악하기 쉬울까요?
절반을 걷어냈더니 신호 대 잡음비(SNR)가 두 배로 올라간 셈이에요.
이 도구를 3편, 4편에 적용하면 어떻게 달라지나요?
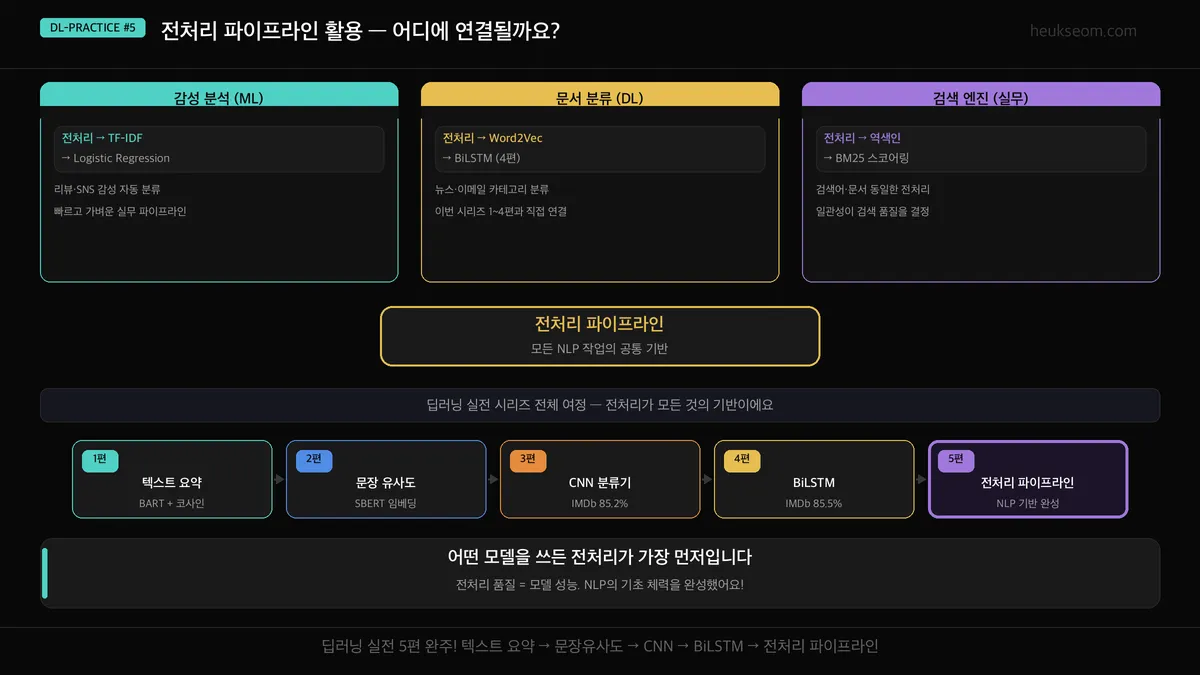
| 편 | 모델 | 전처리 파이프라인 연결 방식 |
|---|---|---|
| 3편 | CNN 텍스트 분류 | TextPreprocessor → 토큰 → Embedding → Conv1D |
| 4편 | BiLSTM 감성 분석 | TextPreprocessor → 토큰 → Embedding → BiLSTM |
| 실무 | 검색 엔진 | TextPreprocessor → 역색인 → BM25 스코어링 |
어떤 모델을 붙이든 입력 형태가 동일해야 해요.
TextPreprocessor는 그 "표준 입력"을 만들어주는 도구예요.
3편, 4편에서 각자 다르게 전처리했던 부분을 이 클래스 하나로 통일할 수 있어요.
실전 5편을 돌아보며
이번 편 핵심 3줄
- 불용어 제거는 단어 수를 50% 이상 줄이면서 의미 단어 집중도를 높여요. 3편/4편 성능의 숨겨진 열쇠입니다.
- 커스텀 불용어 추가로 도메인 특화 노이즈를 걷어낼 수 있어요. IMDb라면 "movie", "film"이 대상.
- TextPreprocessor 클래스로 전처리를 표준화하면 모델 간 공정 비교가 가능해집니다.
딥러닝 실전 시리즈 전체 여정
| 1편 | 텍스트 요약 — BART로 긴 문장에서 핵심만 추출 |
| 2편 | 문장 유사도 — Sentence-BERT로 의미 거리 측정 |
| 3편 | CNN 텍스트 분류기 — IMDb 영화 리뷰 85.2% 정확도 |
| 4편 | BiLSTM 감정 분석기 — 앞뒤 문맥 동시 학습 85.5% |
| 5편 | 불용어 제거 도구 — 노이즈를 걷어내야 모델이 보인다 (이번 편!) |
다음 시리즈 예고
딥러닝 실전 시리즈 5편을 다뤄봤습니다.
다음 시리즈에서는 이미지 처리 딥러닝을 다룰 예정이에요.
CNN(합성곱 신경망), 이미지 분류, 전이 학습까지 — 기대해주세요!