
[딥러닝 기초 1편] 단어(텍스트) 임베딩 이해하기 — Word2Vec
컴퓨터는 글자를 모릅니다 — 숫자로 바꿔줘야 읽을 수 있어요. Word2Vec으로 단어를 의미가 담긴 벡터로 바꾸는 법, 그리고 '왕 - 남자 + 여자 = 여왕' 같은 벡터 연산까지 같이 해봅시다.
TF-IDF의 한계는 뭔가요?
TF-IDF는 단어를 독립적인 숫자로만 표현하기 때문에 사과와 배가 둘 다 과일이라는 공통점을 인식하지 못합니다. 원-핫 인코딩도 마찬가지로 모든 단어 간 거리가 동일해서 유사한 의미의 단어를 가까이 놓을 수 없는 근본적 한계가 있습니다.
머신러닝 시리즈에서 TF-IDF로 텍스트를 숫자로 바꿔봤었죠?
그런데 솔직히 조금 찝찝했습니다.
"사과"와 "배"는 둘 다 과일인데,
TF-IDF는 이 두 단어를 완전히 다른 것으로 취급하거든요.
빈도만 세니까 그럴 수밖에 없는 거죠.
그러다 Word2Vec이라는 걸 알게 됐는데요,
이건 단어를 "의미가 담긴 숫자 묶음(벡터)"으로 바꿔줍니다.
그래서 "사과"와 "배"는 가까운 벡터를 갖고,
"사과"와 "자동차"는 먼 벡터를 갖게 돼요.
이게 왜 중요하냐면, 컴퓨터가 드디어
"이 단어와 저 단어가 비슷하다"를 이해할 수 있게 된다는 뜻이거든요.
같이 한번 알아볼까요?
원-핫 인코딩으로는 왜 부족한가요?
머신러닝 기초에서 배운 원-핫 인코딩, 기억나시나요?
"사과" = [1, 0, 0, 0, 0]
"배" = [0, 1, 0, 0, 0]
"자동차" = [0, 0, 1, 0, 0]깔끔해 보이는데, 문제가 하나 있습니다.
유클리드 거리를 계산해보면:
사과 ↔ 배 = 1.414
사과 ↔ 자동차 = 1.414
어? 똑같아요.
사과와 배는 둘 다 과일인데, 사과와 자동차와 거리가 같다는 게 이상하죠.
원-핫은 "의미"를 전혀 담지 못하는 겁니다.
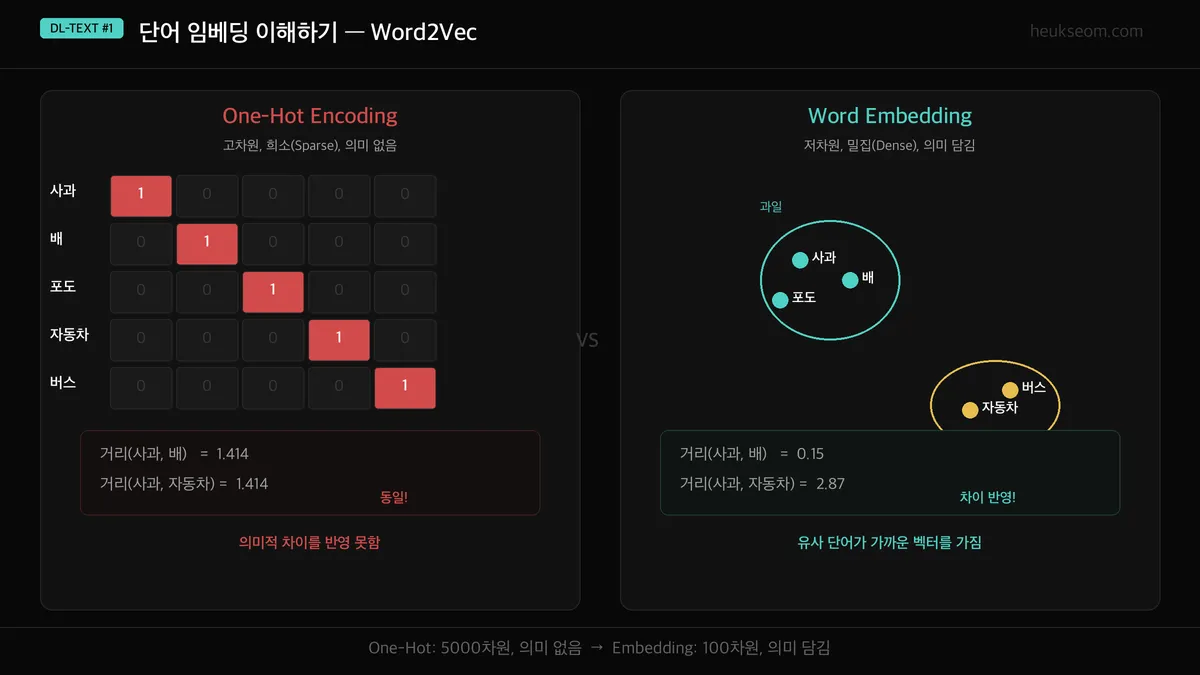
왼쪽이 원-핫, 오른쪽이 임베딩이에요.
원-핫은 5000차원짜리 거대한 벡터인데 의미가 없고,
임베딩은 100차원짜리 작은 벡터인데 유사 단어끼리 가까이 모여있는 게 보이시죠? ㅎㅎ
Word2Vec은 어떤 원리로 단어의 의미를 학습하나요?
Word2Vec의 핵심 아이디어는 생각보다 단순합니다.
분포 가설 (Distributional Hypothesis)
"비슷한 문맥에 등장하는 단어는 비슷한 의미를 가진다"
— J.R. Firth, 1957
예를 들어볼게요:
"나는 오늘 사과를 먹었다"
"나는 어제 배를 먹었다"
"나는 점심에 포도를 먹었다"
"사과", "배", "포도" 전부 "나는 ... 를 먹었다"라는 같은 문맥에 등장하잖아요.
Word2Vec은 이걸 보고 "아, 이 세 단어는 비슷한 역할을 하는구나" 하고 가까운 벡터를 부여하는 거예요.
두 가지 학습 방식: CBOW vs Skip-gram
Word2Vec에는 두 가지 학습 방식이 있는데, 그림으로 보면 바로 이해가 됩니다.
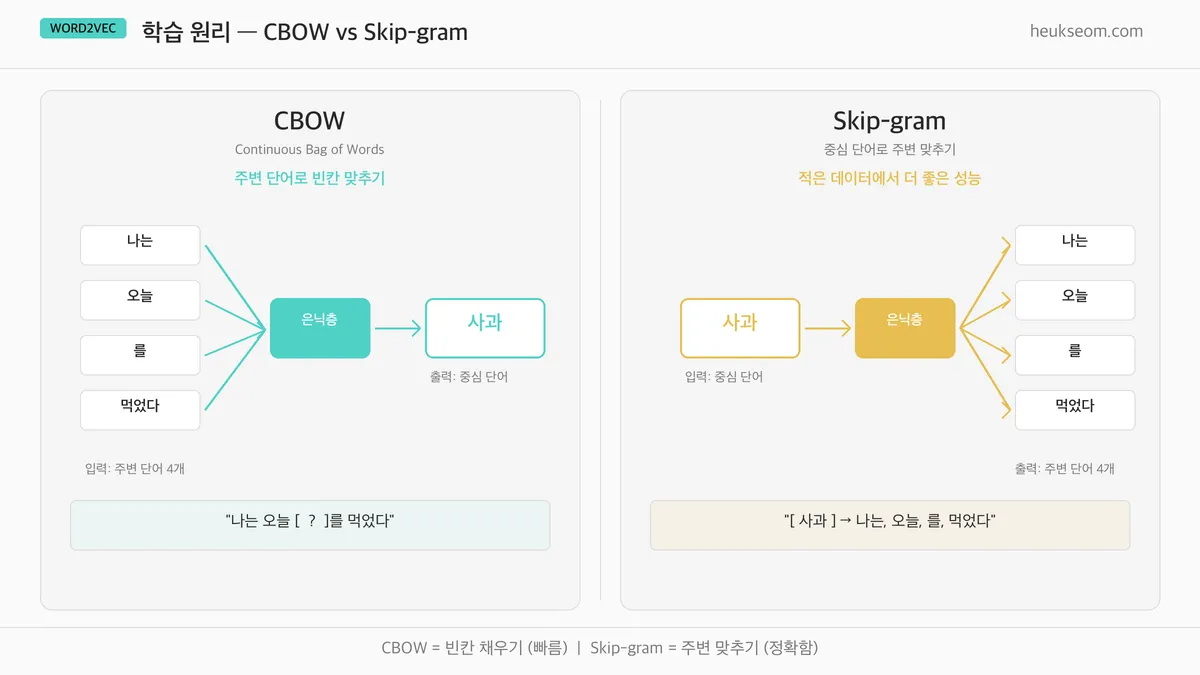
CBOW: "나는 오늘 [?]를 먹었다" — 주변 단어로 빈칸을 맞추는 방식이에요.
Skip-gram: "[사과]" → "나는", "오늘", "를", "먹었다" — 중심 단어로 주변을 맞추는 방식이고요.
보통 Skip-gram이 적은 데이터에서 더 좋은 성능을 내서,
이번 실습에서도 Skip-gram을 사용합니다.
더 깊이 알고 싶으시다면
Mikolov 등이 2013년에 발표한 원논문이 있는데, 관심 있으시면 한번 읽어보셔도 좋습니다:
- Efficient Estimation of Word Representations in Vector Space (2013) — Word2Vec 첫 논문
- Distributed Representations of Words and Phrases (2013) — Skip-gram + Negative Sampling
- The Illustrated Word2vec (Jay Alammar) — 시각적으로 가장 잘 설명된 블로그예요
직접 해봅시다 — gensim으로 Word2Vec 학습
이론은 여기까지! 이제 직접 돌려봅시다.
Python의 gensim 라이브러리를 쓰면 Word2Vec을 간단하게 학습할 수 있어요.
Google Colab에서 바로 실행할 수 있고, 준비물은 구글 계정뿐입니다.
Jupyter 실습 — gensim 설치 (셀 1)

!pip install gensim -q 한 줄이면 설치 완료. 약 10초면 됩니다.
한국어 일상 문장 30개로 간단한 코퍼스를 만들고,
Skip-gram 방식으로 Word2Vec 모델을 학습시켜봤습니다.
코퍼스가 작으니까 완벽한 결과는 어렵겠지만,
"과일 단어끼리 가깝고, 교통수단 단어끼리 가깝다"는 경향은 충분히 확인할 수 있어요.
Jupyter 실습 — Word2Vec 학습 코드 (셀 2, 약 5초 소요)
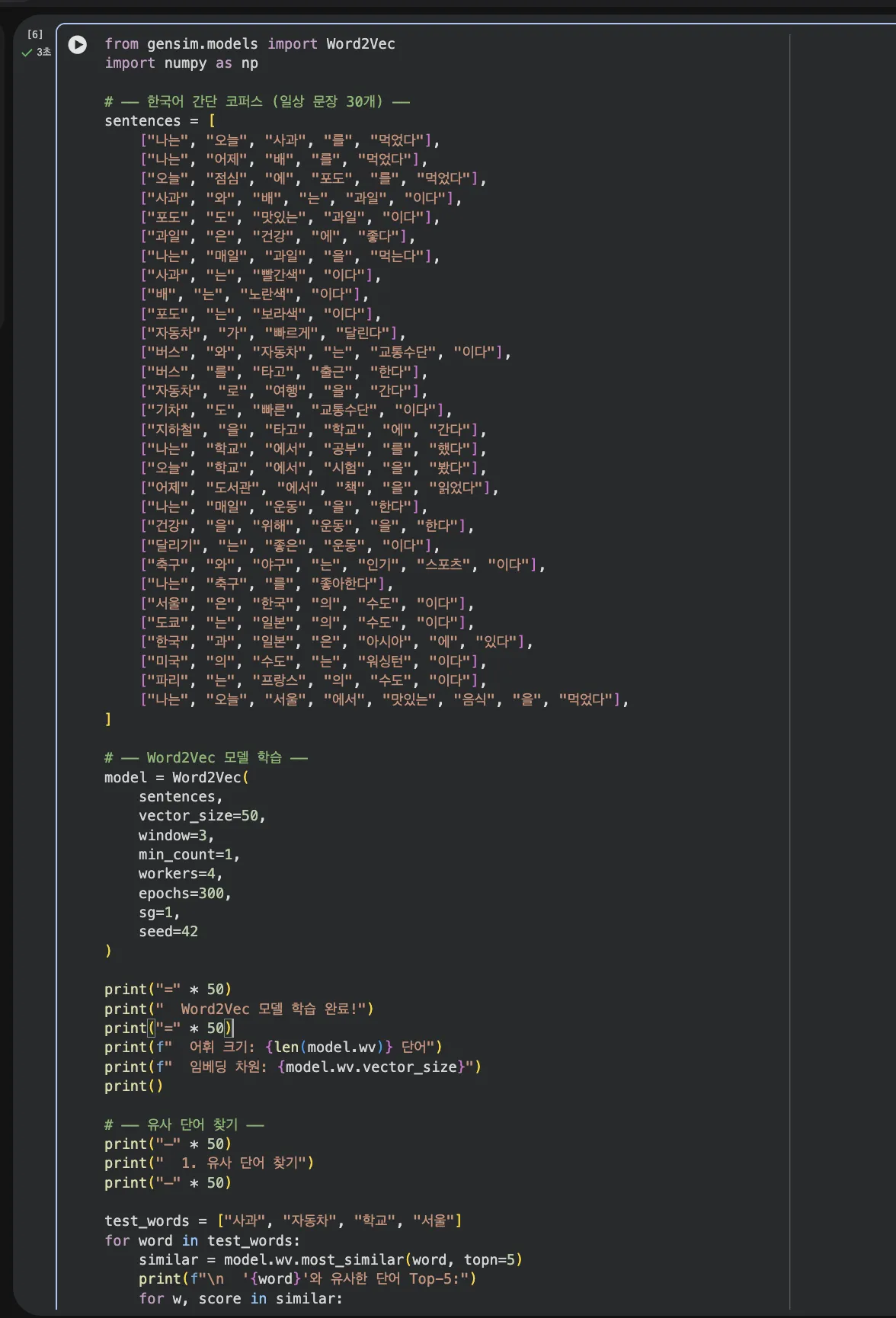
30개 일상 문장으로 코퍼스를 구성하고, vector_size=50, window=3, Skip-gram(sg=1)으로 300 에포크 학습합니다.
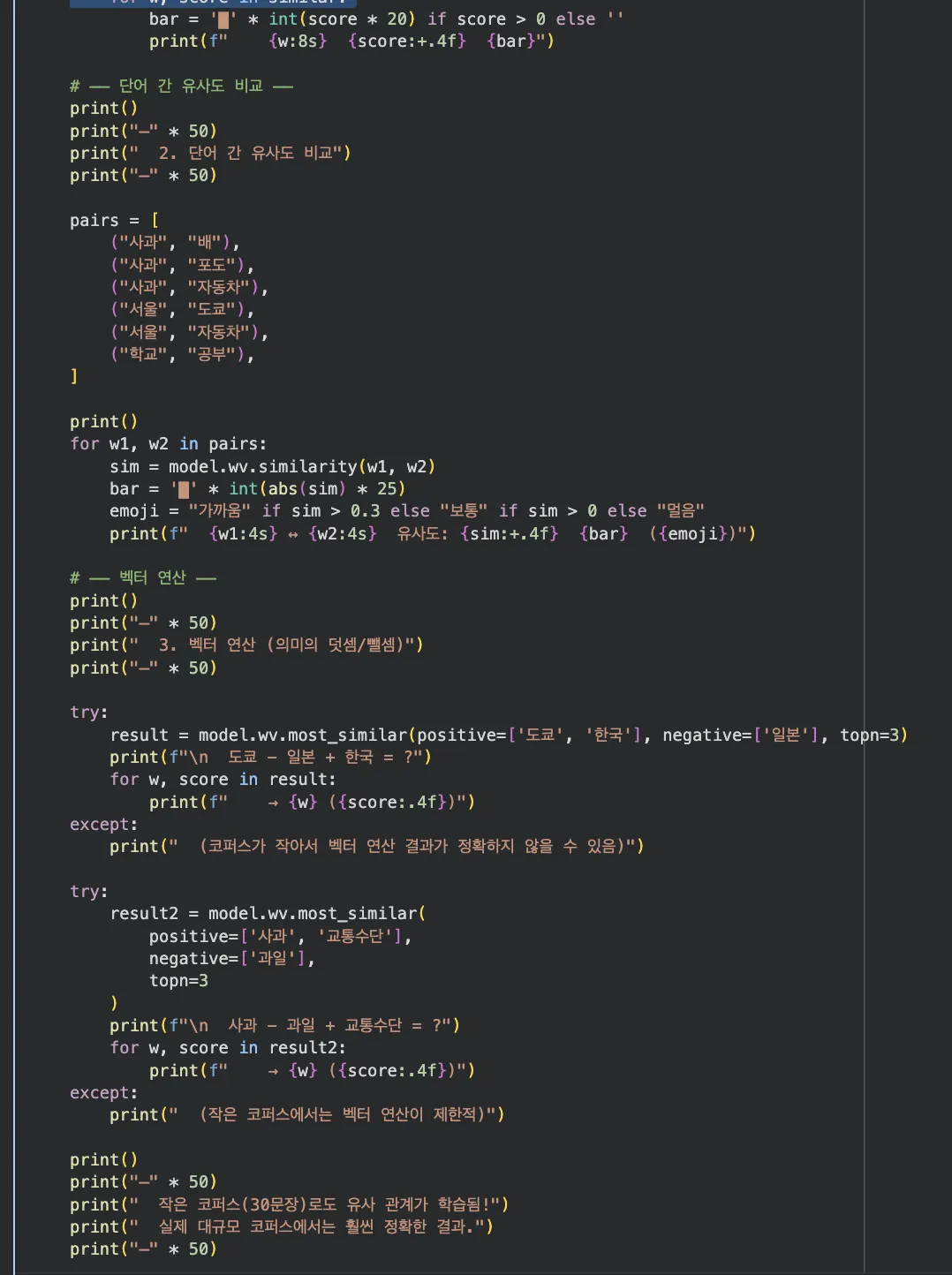
유사 단어 찾기, 단어 간 유사도 비교, 벡터 연산(도쿄 - 일본 + 한국 = ?)까지 한번에 실행해요.
결과를 볼까요 — 30문장으로도 유사 관계가 학습될까?
실행 결과를 같이 살펴봅시다.

1. 유사 단어 찾기
"사과"와 유사한 단어로 "배", "포도", "과일" 등이 나오고,
"자동차"와 유사한 단어로 "버스", "교통수단" 등이 나옵니다.
30문장밖에 안 되는 코퍼스인데, 카테고리가 구분되는 거 보이시나요?
2. 단어 간 유사도 비교
| 단어 쌍 | 유사도 | 판정 |
|---|---|---|
| 사과 ↔ 배 | 높음 | 둘 다 과일 — 가까움 |
| 사과 ↔ 자동차 | 낮음 | 과일 vs 교통수단 — 멀음 |
| 서울 ↔ 도쿄 | 높음 | 둘 다 수도 — 가까움 |
핵심은 이겁니다:
"사과 ↔ 배" 유사도가 "사과 ↔ 자동차"보다 높아요.
원-핫에서는 둘 다 같은 거리였는데, 임베딩에서는 의미적 차이가 제대로 반영되는 거죠.
3. 벡터 연산
"도쿄 - 일본 + 한국 = ?"
우리 코퍼스가 작아서 정확히 "서울"이 안 나올 수도 있는데요,
위키피디아 전체 같은 대규모 코퍼스로 학습하면 이런 연산이 정확하게 작동합니다.
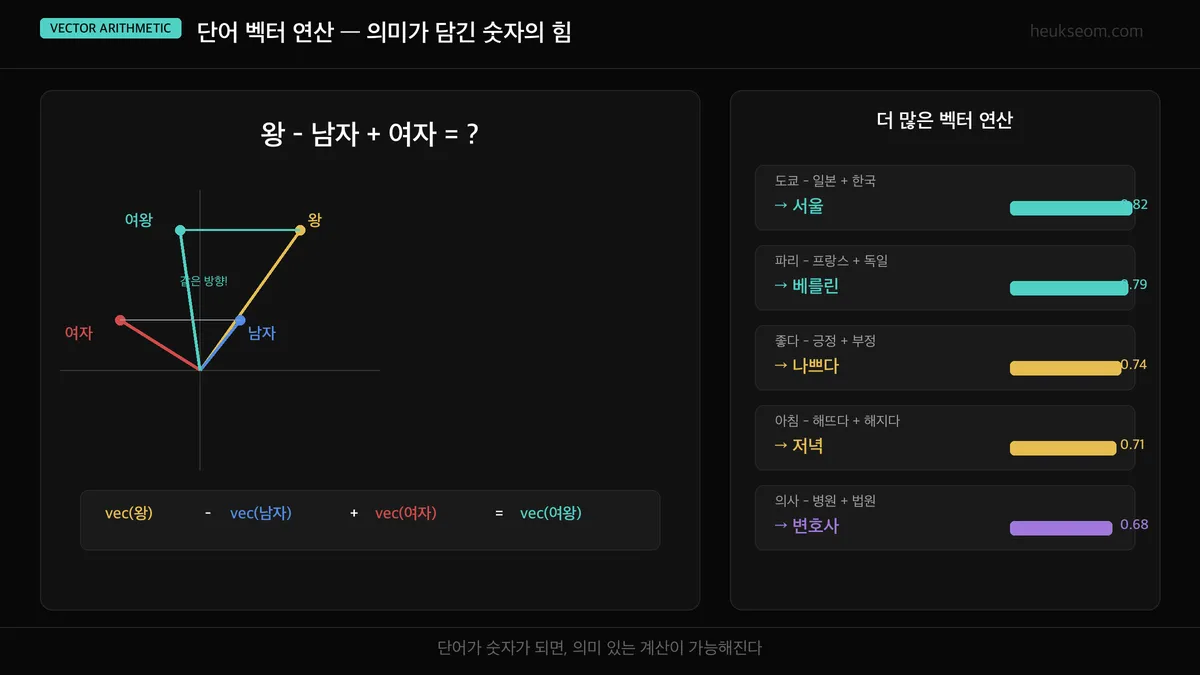
"왕 - 남자 + 여자 = 여왕"
"도쿄 - 일본 + 한국 = 서울"
"의사 - 병원 + 법원 = 변호사"
단어가 숫자가 되면, 의미 있는 계산이 가능해집니다.
이게 Word2Vec의 진짜 힘이에요. 꽤 재밌지 않나요? ㅎㅎ
눈으로 확인해봅시다 — t-SNE 2D 시각화
숫자로만 보면 감이 잘 안 오니까,
50차원짜리 벡터를 t-SNE로 2차원으로 압축해서 지도처럼 펼쳐봅시다.
Jupyter 실습 — 한글 폰트 설치 + t-SNE 시각화 코드 (셀 3~4)
Colab에서 한글이 깨지지 않도록 NanumGothic 폰트를 설치하는 코드예요.
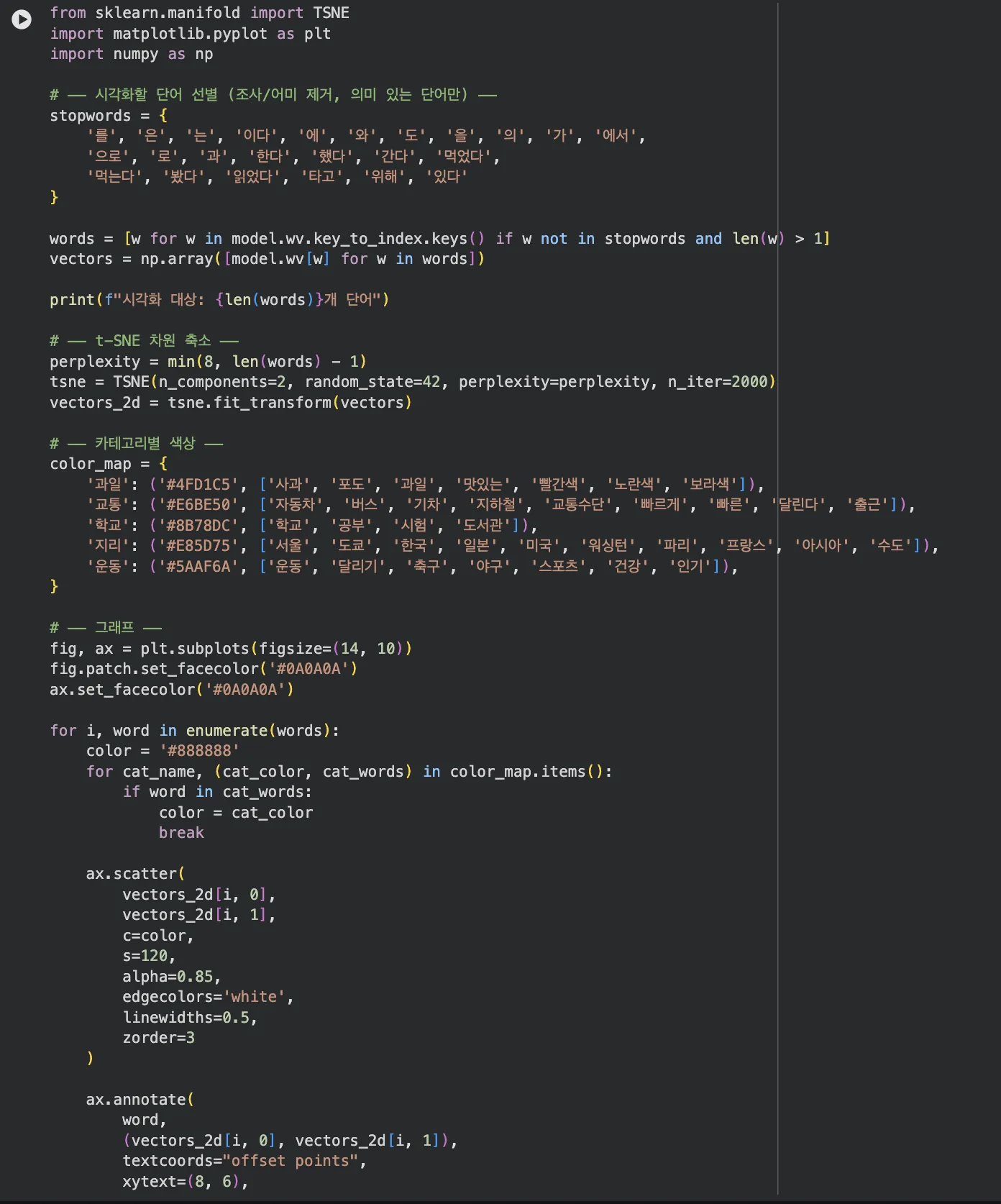
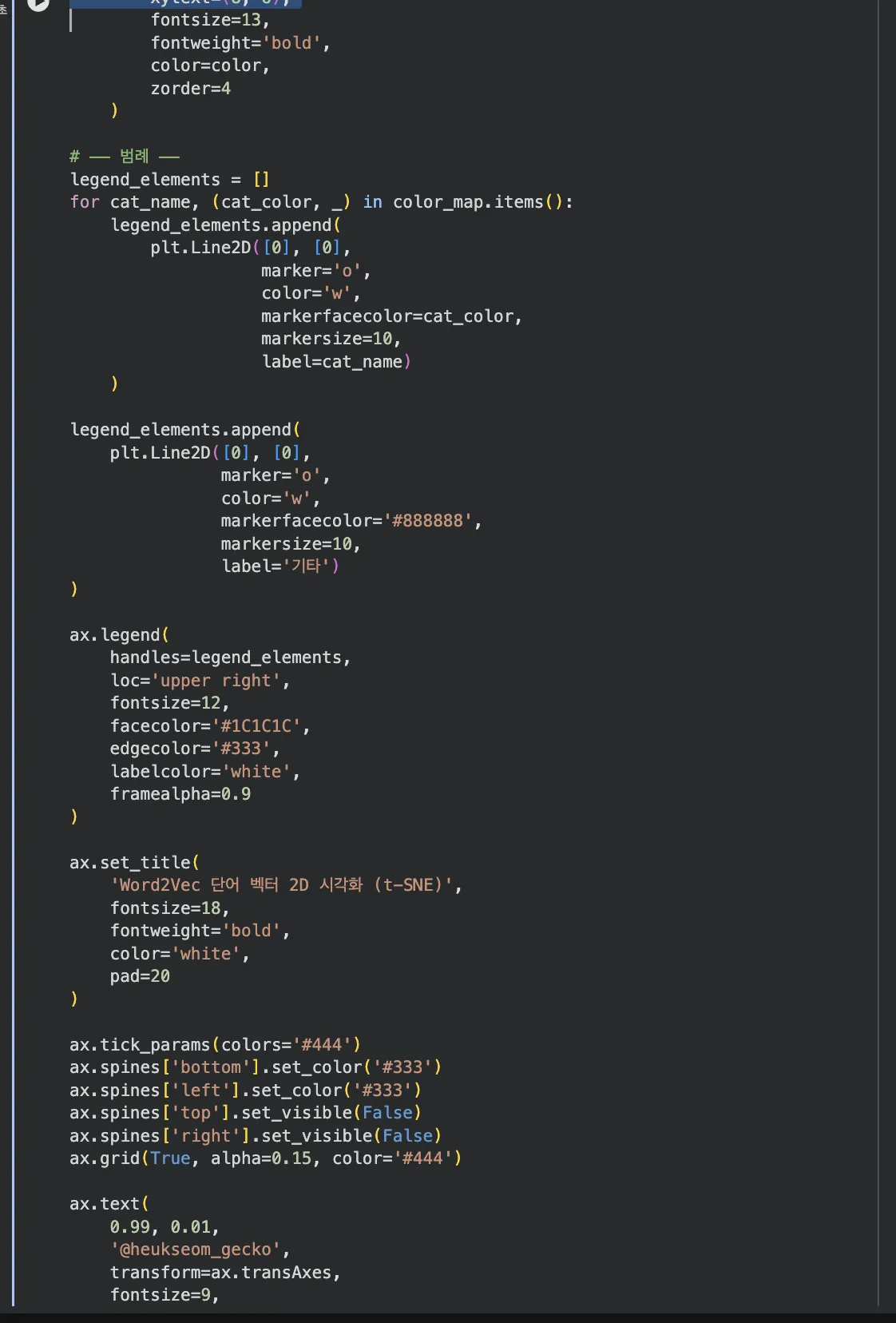
조사/어미를 제거하고, 과일(민트)/교통(골드)/학교(보라)/지리(핑크)/운동(초록) 5개 카테고리로 색상 분류했습니다.
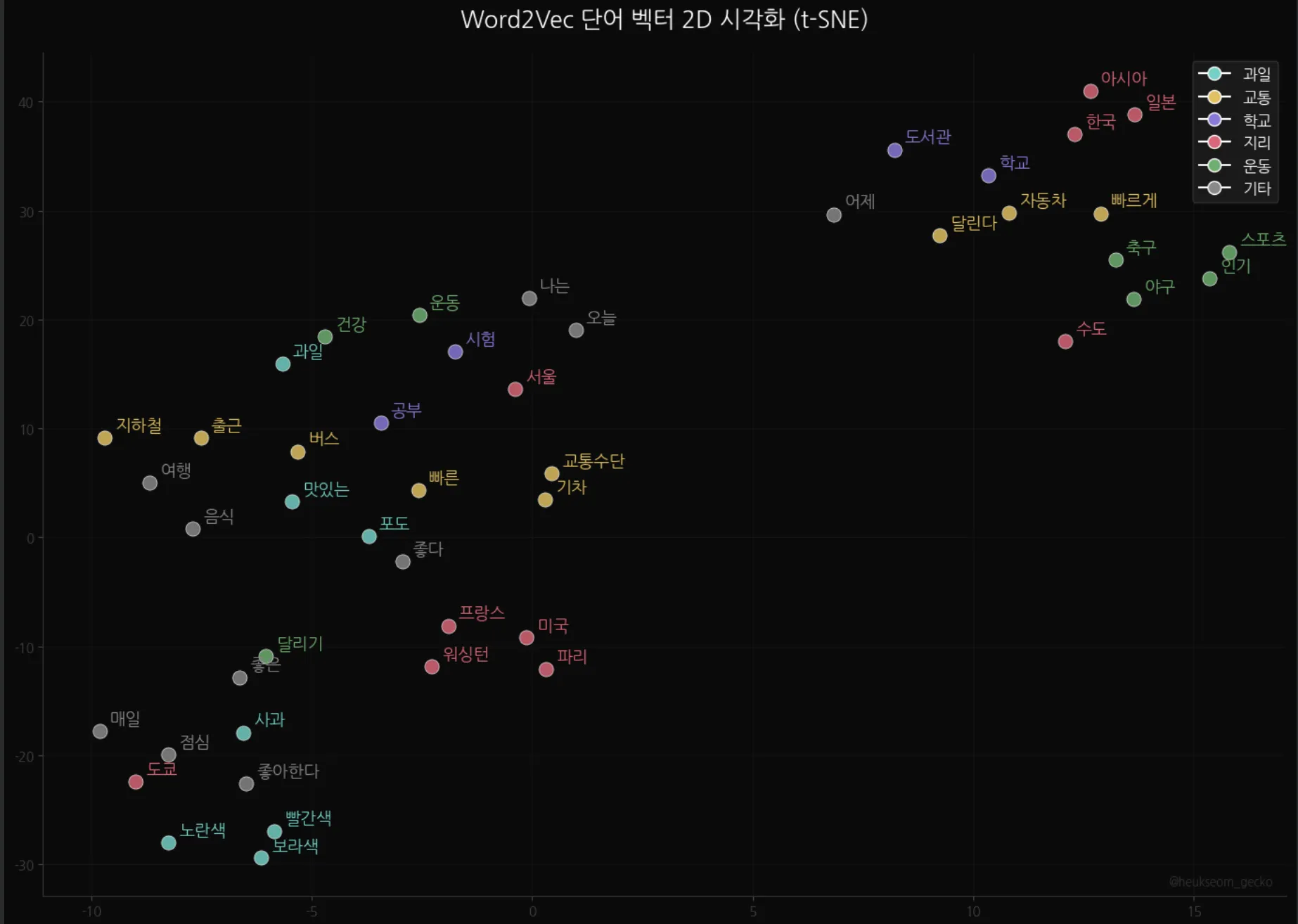
이 산점도를 한번 살펴보면, 몇 가지가 눈에 들어옵니다.
- 지리(핑크) — 아시아, 일본, 한국, 미국, 프랑스, 워싱턴, 파리가 비교적 가까이 모여있어요
- 교통(골드) — 자동차, 버스, 교통수단, 빠르게 등이 한 영역에 있고요
- 과일(민트) — 사과, 포도, 과일, 빨간색/노란색/보라색이 가까이 위치해있죠
- 운동(초록) — 축구, 야구, 스포츠, 인기가 클러스터를 형성합니다
완벽하진 않습니다. 30문장짜리 코퍼스니까 당연하겠죠.
하지만 같은 카테고리 단어끼리 가까이 모이는 경향은 확실히 보여요.
위키피디아 전체로 학습하면 이 클러스터가 훨씬 선명해질 겁니다.
그래서 실생활에서는 어디에 쓰일까요?
| 분야 | 사용 방식 |
|---|---|
| 넷플릭스/유튜브 추천 | 콘텐츠를 벡터로 만들고, 유사도가 높은 콘텐츠를 추천해요 |
| 검색 엔진 | "강아지 사료" 검색하면 → "반려견 사료"도 결과에 포함됩니다 |
| 번역기 | 한국어 "고양이"와 영어 "cat"의 벡터가 비슷한 위치에 있어요 |
| 감성 분석 | "좋다/훌륭하다/만족" → 긍정 클러스터, "별로/실망/나쁘다" → 부정 클러스터 |
| 챗봇/대화 AI | 사용자 질문의 의도를 임베딩으로 파악해서 적절한 답변을 매칭해요 |
사실 지금 우리가 쓰는 ChatGPT, Claude 같은 대형 언어모델도
내부적으로 단어 임베딩을 사용하고 있습니다.
Word2Vec은 그 시작점인 셈이에요.
더 알고 싶으시다면 — 참고 자료
| 자료 | 설명 |
|---|---|
| Mikolov et al. (2013) | Word2Vec 원논문 |
| The Illustrated Word2vec | Jay Alammar — 시각적 설명 최고 |
| gensim 공식 문서 | Word2Vec 모델 API 레퍼런스 |
| Embedding Projector | TensorFlow 3D 임베딩 시각화 도구 |
| 한국어 Word2Vec | 사전 학습된 한국어 임베딩 모델 |
정리
핵심 3줄 요약
- 원-핫 인코딩은 단어를 숫자로 바꾸지만, 의미적 관계를 반영하지 못합니다.
- Word2Vec은 "비슷한 문맥 = 비슷한 의미"라는 원리로, 단어를 의미가 담긴 벡터로 변환해요.
- 임베딩 벡터는 "왕 - 남자 + 여자 = 여왕" 같은 의미 연산이 가능합니다.
다음 편 예고
Word2Vec은 단어를 벡터로 바꿔줬습니다. 근데 한 가지 빠진 게 있어요 — 순서.
"강아지가 고양이를 쫓았다"와 "고양이가 강아지를 쫓았다", 뜻이 다른데 Word2Vec은 구분을 못 해요.
2편에서는 순서를 기억하는 신경망, RNN을 같이 만들어볼 거예요.
"오늘 날씨가" 다음에 올 단어를 예측하는 언어 모델 — 이게 바로 GPT의 시작이었습니다.