
[딥러닝 기초 2편] RNN 언어 모델 — 다음 단어 예측하기
Word2Vec은 단어를 벡터로 바꿨지만 순서를 무시합니다. RNN은 단어를 순서대로 읽으면서 '기억'을 쌓고, 다음에 올 단어를 예측해요. 이게 바로 GPT의 시작이었습니다.
시작하며 — Word2Vec에 빠진 한 가지
1편에서 Word2Vec으로 단어를 벡터로 바꿔봤죠?
"사과"와 "배"가 가까운 벡터를 갖는다는 걸 확인했고, 꽤 신기했습니다 ㅎㅎ
근데 한 가지 빠진 게 있어요 — 순서입니다.
"강아지가 고양이를 쫓았다"
"고양이가 강아지를 쫓았다"
이 두 문장은 같은 단어를 쓰지만 뜻이 완전히 다르잖아요.
그런데 Word2Vec은 이걸 구분하지 못합니다. 순서를 무시하니까요.
그래서 등장한 게 RNN (Recurrent Neural Network, 순환 신경망)이에요.
단어를 하나씩 "순서대로" 읽으면서, 이전까지 읽은 내용을 "기억"합니다.
이 기억을 바탕으로 다음에 올 단어를 예측하죠.
ChatGPT, Claude — 우리가 매일 쓰는 AI 대화 모델의 핵심 원리가
바로 이 "다음 단어 예측"이에요. 이번 편에서 그 시작점을 직접 만들어봅시다.
RNN 구조는 어떻게 기억을 가지나요?
RNN은 이전 단계의 출력을 다음 단계의 입력으로 다시 넣는 순환 구조를 가지고 있습니다. 일반 신경망은 각 입력을 독립적으로 처리하지만, RNN은 hidden state를 통해 이전 정보를 기억하면서 순서가 있는 데이터를 처리할 수 있습니다.
일반적인 신경망은 입력을 받으면 바로 출력을 내놓습니다.
이전에 뭘 봤는지 기억 못 해요.
RNN은 다릅니다. 매 시점마다 "이전 기억(hidden state)"을 받아서
새 입력과 합친 다음, 새로운 기억을 만들어냅니다.
이 기억이 다음 시점으로 전달되면서, 순서 정보가 유지됩니다.
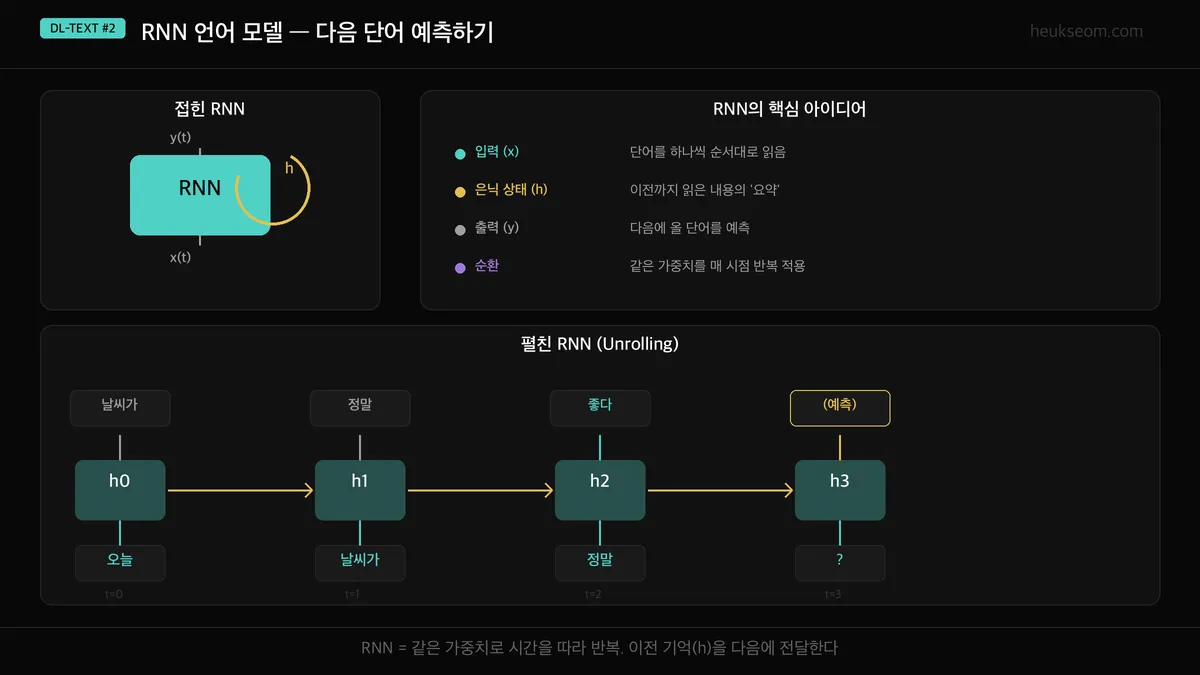
위 그림에서 핵심을 정리하면 이렇습니다:
- 입력 (x) — 단어를 하나씩 순서대로 읽어요
- 은닉 상태 (h) — 이전까지 읽은 내용의 "요약"이에요. 이게 바로 기억!
- 출력 (y) — 다음에 올 단어를 예측합니다
- 순환 — 같은 가중치를 매 시점마다 반복 적용해요
예를 들어 "오늘 날씨가 정말 ?"이라는 문장이 있다면:
t=0에서 "오늘"을 읽고, t=1에서 "날씨가"를 읽고, t=2에서 "정말"을 읽으면서
매번 이전 기억에 새 정보를 쌓아요.
그리고 t=3에서 지금까지의 기억을 바탕으로 "좋다"를 예측하게 됩니다.
언어 모델은 다음 단어를 어떻게 예측하나요?
언어 모델이 하는 일은 놀라울 정도로 단순합니다.
언어 모델의 핵심
"지금까지 나온 단어들을 보고, 다음에 올 단어를 예측한다"
— 이게 GPT, Claude 등 모든 대형 언어모델의 기본 원리입니다
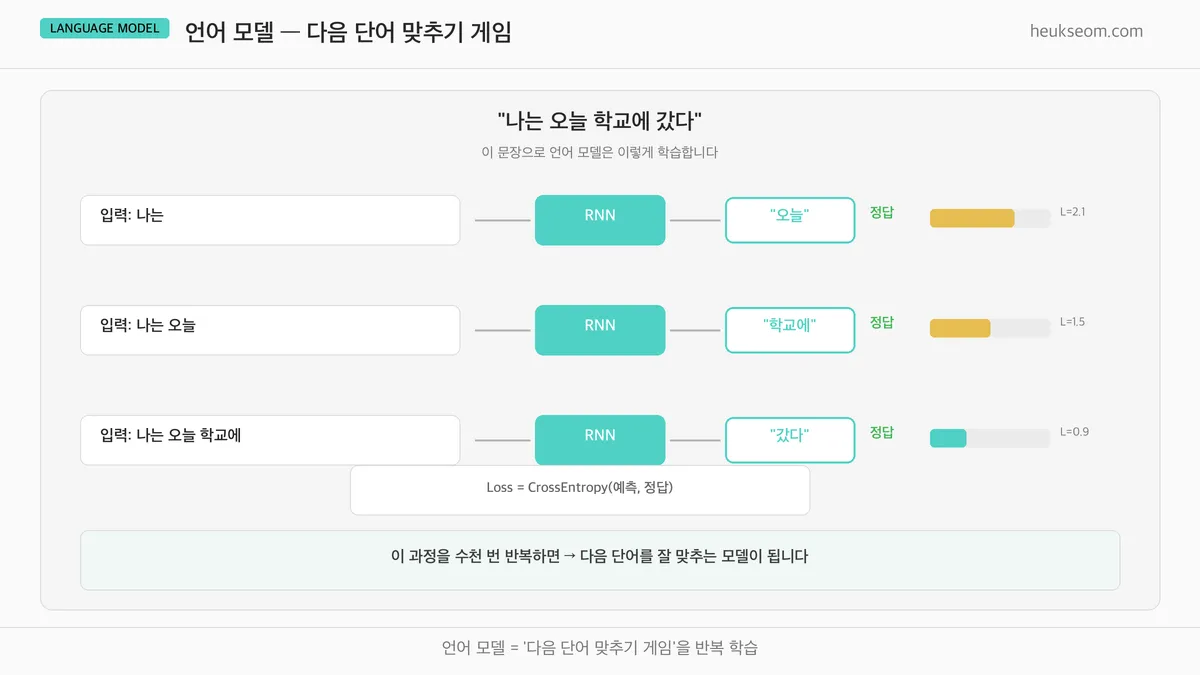
"나는 오늘 학교에 갔다"라는 문장이 있으면:
- "나는" → 다음 단어 "오늘" 예측
- "나는 오늘" → 다음 단어 "학교에" 예측
- "나는 오늘 학교에" → 다음 단어 "갔다" 예측
틀릴 때마다 가중치를 조금씩 조정하고 (경사 하강법),
이 과정을 수천 번 반복하면 점점 더 정확해집니다.
Loss(예측과 정답의 차이)가 줄어드는 걸 학습 곡선에서 확인할 수 있어요.
직접 만들어봅시다 — PyTorch로 RNN 언어 모델
이론은 여기까지! 이제 직접 만들어봅시다.
PyTorch로 간단한 RNN 언어 모델을 구현하고, 한국어 문장 15개로 학습시켜볼 거예요.
Step 1. 코퍼스 준비 + 단어 사전
먼저 학습 데이터(코퍼스)를 준비하고, 모든 단어에 번호를 매깁니다.
RNN은 숫자만 읽을 수 있으니까요 — 1편에서 배운 것처럼요.
Jupyter 실습 — 한글 폰트 설치 + 코퍼스 준비 (셀 1~2)
Colab 환경에서 한글 폰트 설치 및 테스트. NanumGothic 폰트가 정상 동작하는지 확인합니다.
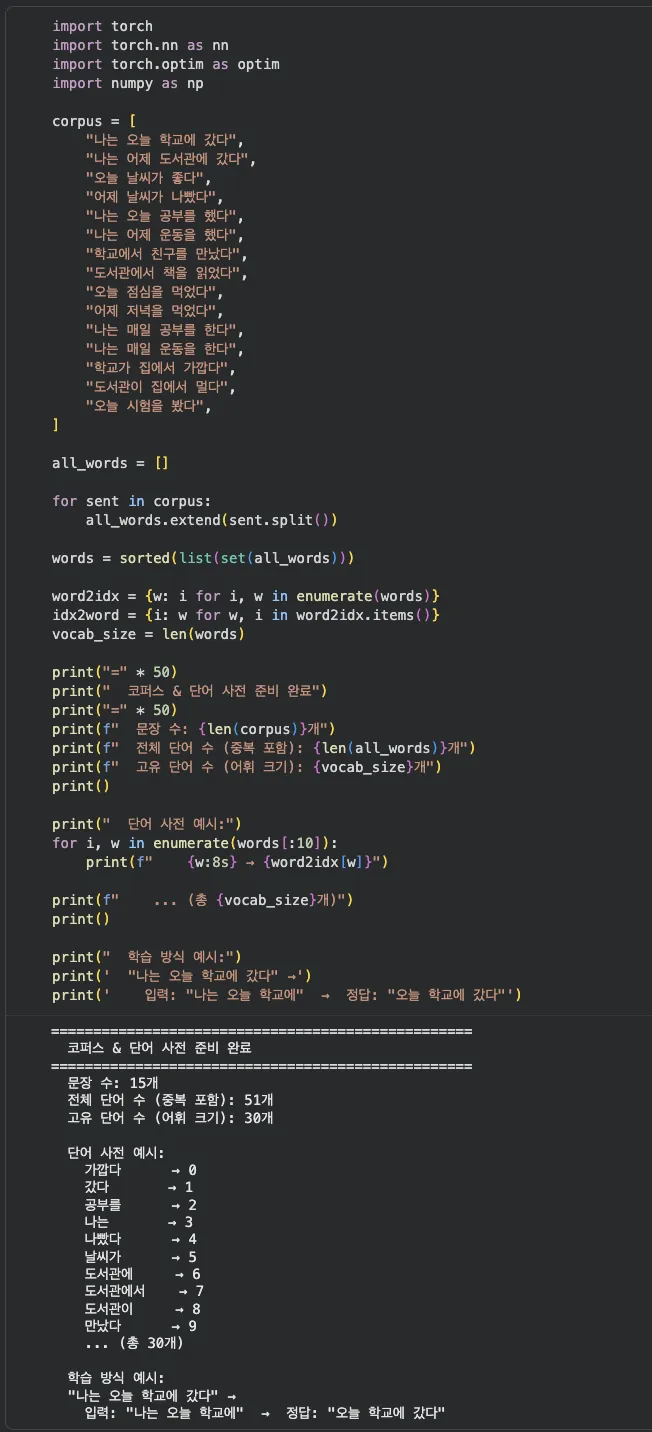
15개 한국어 문장으로 코퍼스를 구성하고, 고유 단어 사전을 만듭니다. "나는 오늘 학교에 갔다" → 입력: "나는 오늘 학교에" / 정답: "오늘 학교에 갔다" 방식으로 학습해요.
Step 2. RNN 모델 정의
모델 구조는 3단계입니다:
- Embedding — 단어를 32차원 벡터로 변환 (1편 Word2Vec과 같은 역할!)
- RNN — 벡터를 순서대로 처리하면서, 이전 기억 + 새 입력 → 새 기억 생성
- Linear — 기억(hidden state)을 바탕으로 다음 단어 예측
Jupyter 실습 — RNN 모델 정의 (셀 3)
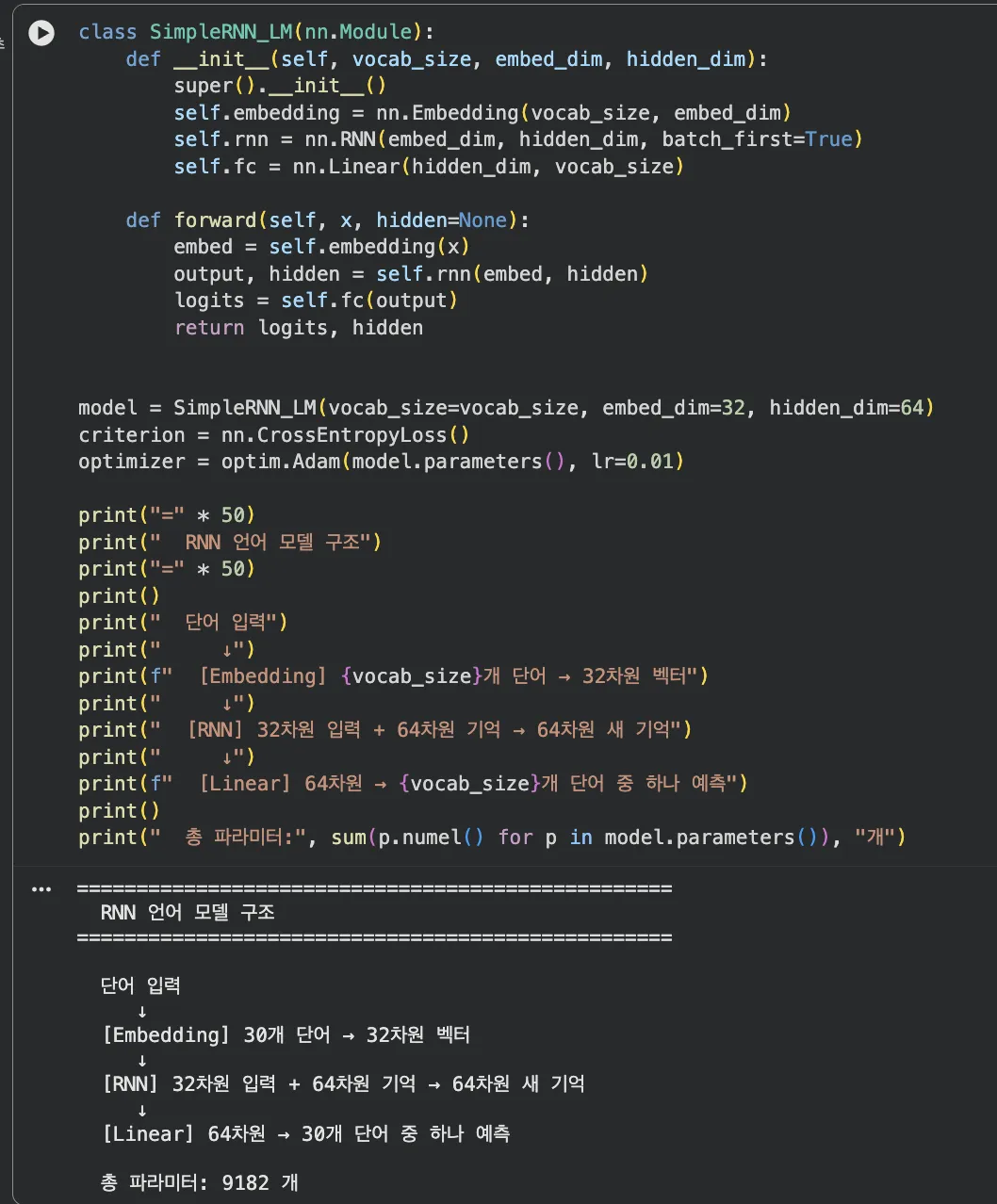
Embedding(단어→벡터) → RNN(순서 처리) → Linear(다음 단어 예측) 3단계 구조. 총 파라미터 약 9,000개 — 아주 작은 모델이에요.
Step 3. 학습
300번(epoch) 반복하면서 "다음 단어 맞추기"를 연습합니다.
Loss가 내려갈수록 다음 단어를 잘 맞추고 있다는 뜻이에요.
Jupyter 실습 — 학습 코드 (셀 4, 약 10초 소요)
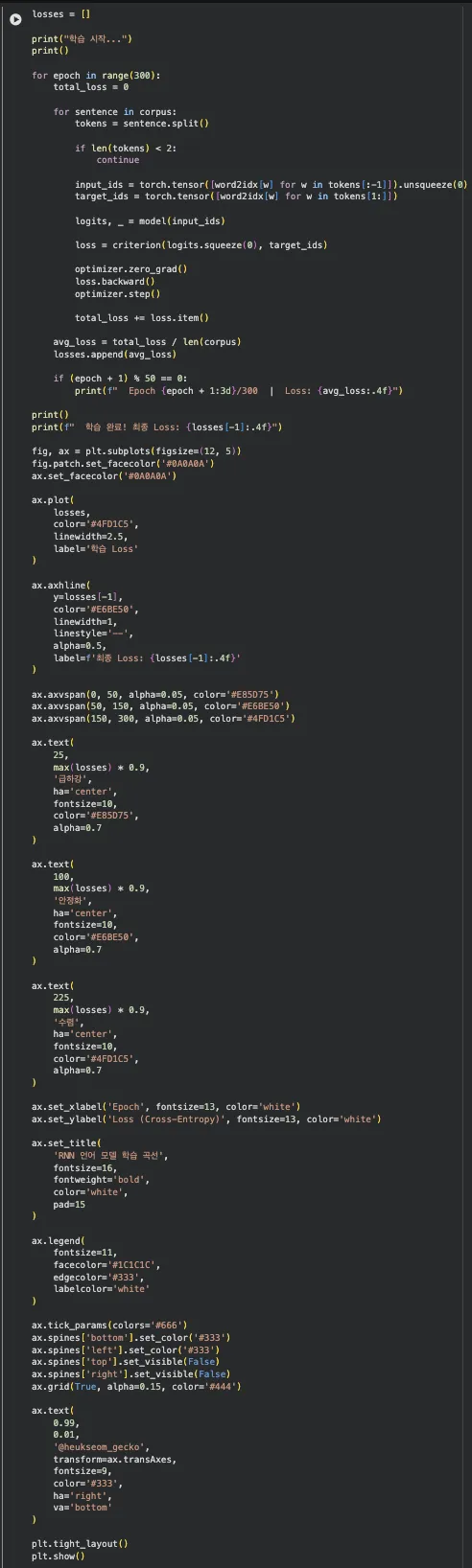
각 문장에서 "입력 → 정답"을 추출하고, 예측과 정답의 차이(Loss)를 줄여나가는 학습 루프입니다.
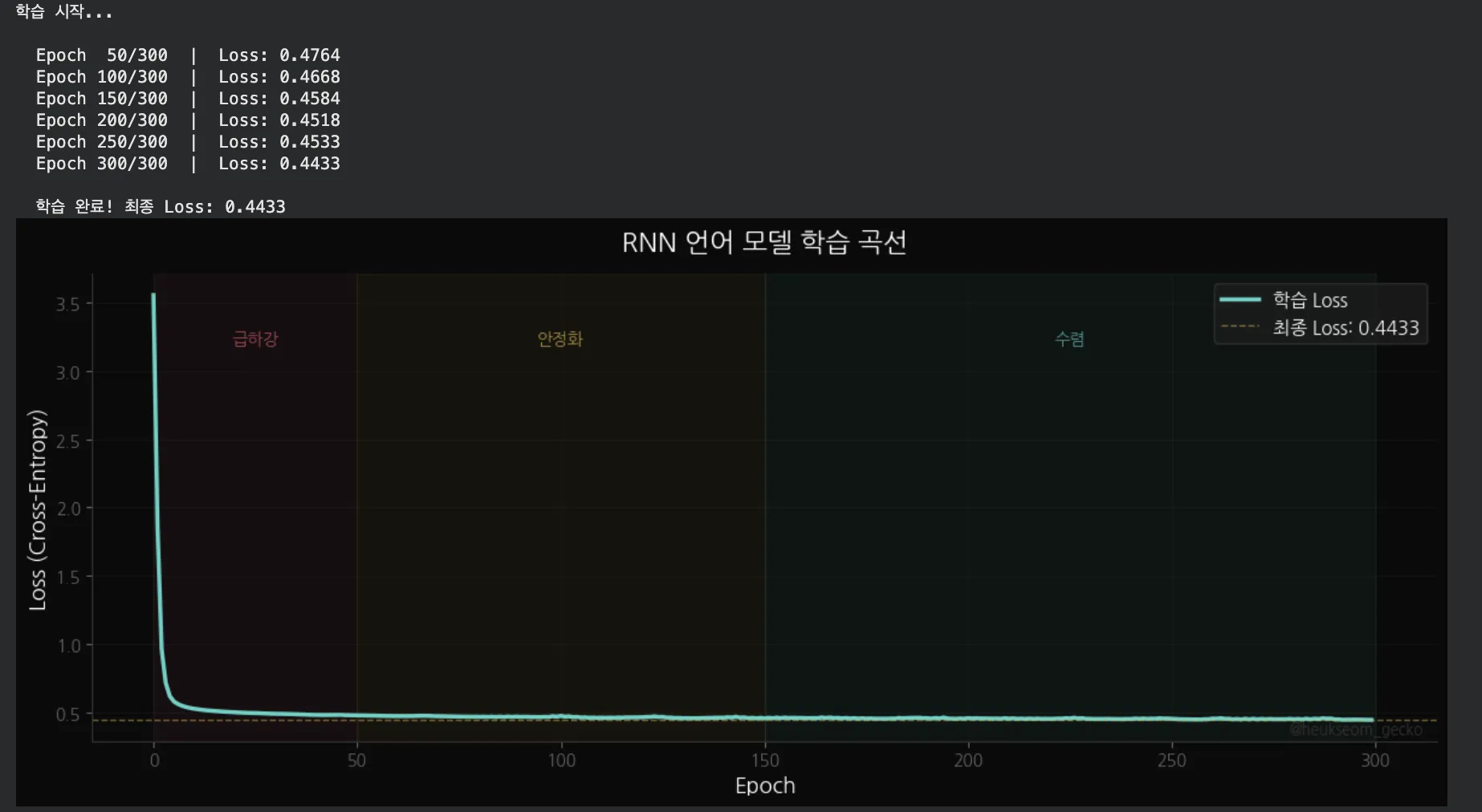
학습 곡선을 보면 3단계가 보여요:
- 급하강 (0~50) — 처음에는 아무것도 모르니까 Loss가 높아요. 빠르게 학습합니다
- 안정화 (50~150) — 대략적인 패턴은 잡았고, 세부 조정 단계예요
- 수렴 (150~300) — 더 이상 크게 개선되지 않아요. 학습 완료!
결과를 볼까요 — 다음 단어 예측 테스트
학습이 끝난 모델에게 문장 앞부분을 주고,
다음에 올 단어를 맞춰보라고 해봤습니다.

| 입력 | 1위 예측 | 확률 | 해석 |
|---|---|---|---|
| "나는 오늘" | 공부를 / 학교에 | 높음 | 코퍼스에 "나는 오늘 학교에/공부를" 있었으니까요 |
| "오늘 날씨가" | 좋다 | 100% | "오늘 날씨가 좋다" 문장이 학습 데이터에 있었어요 |
| "나는 어제" | 운동을 / 도서관에 | 높음 | "나는 어제 도서관에/운동을" 패턴 학습 |
| "학교에서 친구를" | 만났다 | 100% | 정확하게 맞췄어요! |
| "나는 매일" | 공부를 / 운동을 | 높음 | "나는 매일 공부를/운동을" 두 패턴 모두 학습 |
15개 문장으로 학습한 아주 작은 모델인데도,
문맥에 따라 다음 단어를 꽤 정확하게 예측하고 있어요 ㅋㅋ
이게 바로 GPT의 가장 기본적인 원리입니다.
RNN은 뭐가 달라졌고 한계는 뭔가요?

1편까지의 방식(Bag of Words, Word2Vec)과 비교해보면,
RNN은 순서 반영, 문맥 이해, 가변 길이 처리를 전부 할 수 있어요.
하지만 RNN에도 한계가 있습니다.
장기 의존성 문제 (Long-Term Dependency)
"나는 한국에서 태어나서 ... (30단어) ... [ ]를 잘 한다"
빈칸에 들어갈 말은 "한국어"인데, "한국"이라는 단서가 너무 멀리 있어요.
RNN은 기울기 소실(Vanishing Gradient) 때문에 이렇게 먼 정보를 기억하지 못합니다.
이 문제의 해결책은 LSTM (Long Short-Term Memory)이에요.
"기억할 것"과 "잊을 것"을 선택하는 게이트를 가지고 있어서,
긴 문장에서도 중요한 정보를 유지할 수 있습니다.
→ 4편에서 같이 만들어볼 거예요!
더 알고 싶으시다면 — 참고 자료
| 자료 | 설명 |
|---|---|
| Andrej Karpathy — The Unreasonable Effectiveness of RNNs | RNN이 얼마나 다양한 일을 할 수 있는지 보여주는 명 블로그 |
| Chris Olah — Understanding LSTM Networks | RNN 한계와 LSTM 해결 원리를 시각적으로 설명 (4편 예습용!) |
| PyTorch 공식 RNN Tutorial | PyTorch로 RNN 문자 분류기 만드는 공식 튜토리얼이에요 |
| Jay Alammar — Visualizing Seq2Seq | RNN 기반 번역 모델의 동작을 시각적으로 이해할 수 있어요 |
정리
핵심 3줄 요약
- RNN은 단어를 순서대로 읽으면서 이전 기억(hidden state)을 다음에 전달하는 신경망이에요.
- 언어 모델은 "다음 단어 맞추기 게임"을 반복 학습합니다 — 이게 GPT의 기본 원리예요.
- RNN은 순서를 처리할 수 있지만, 긴 문장에서 앞부분을 까먹는 한계가 있습니다 (장기 의존성 문제).
다음 편 예고
이번 편에서는 RNN으로 다음 단어를 예측하는 모델을 만들어봤습니다.
3편에서는 잠깐 쉬어가는 편으로, 단어 빈도 분석기를 만들어볼 거예요.
뉴스 기사 1000개에서 가장 많이 나온 단어 Top 10을 뽑고, 워드클라우드까지 그려봅시다.