
[딥러닝 기초 3편] 단어 빈도 분석기 — 텍스트의 핵심을 한눈에
뉴스 기사 20개에서 가장 많이 나온 단어를 뽑으면, 세상이 뭘 말하는지 보입니다. Counter로 빈도를 세고, 막대그래프와 워드클라우드로 시각화하는 방법을 같이 해봅시다.
시작하며 — 텍스트 1000개를 어떻게 요약할까요?
1편에서 단어를 벡터로, 2편에서 순서대로 읽는 법을 배웠죠.
이번 편은 한 발짝 물러서서 생각해볼게요.
텍스트 분석의 가장 기본은 뭘까요?
바로 "어떤 단어가 많이 나왔는가"입니다.
뉴스 기사 1000개를 받았을 때, 일일이 읽는 건 현실적으로 어렵습니다.
근데 빈도 Top 10만 뽑으면?
"아, 사람들이 이 주제에 관심이 많구나"가 바로 보입니다.
이번 편은 2편에서 PyTorch를 집중적으로 다뤘으니, 잠시 호흡을 고르는 편입니다.
하지만 실무에서 가장 자주 쓰이는 분석이기도 합니다.
빈도 분석 파이프라인은 어떤 단계로 구성되나요?
빈도 분석 파이프라인은 텍스트 수집, 토큰화, 불용어 제거, 빈도 집계, 시각화의 5단계로 구성됩니다. Counter와 NLTK만 있으면 텍스트 수천 개에서도 핵심 키워드를 자동으로 뽑아낼 수 있고 워드클라우드로 한눈에 확인할 수 있습니다.
텍스트를 받아서 핵심 키워드를 뽑기까지, 5단계를 거칩니다.
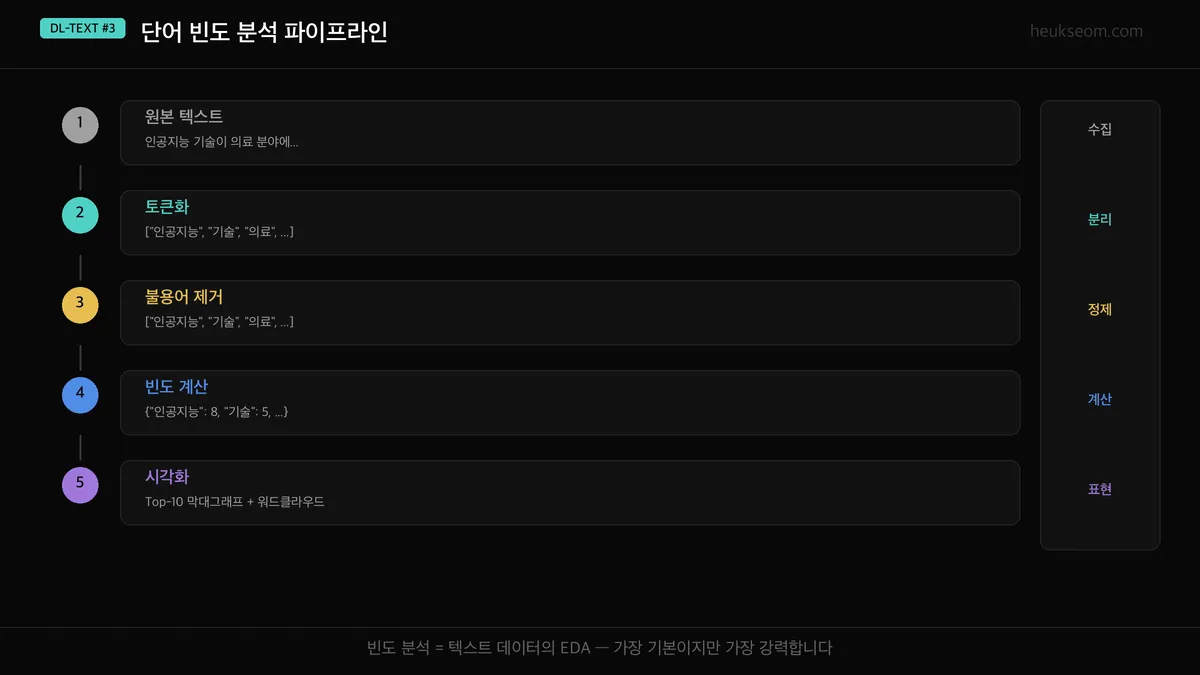
- 원본 텍스트 — 분석할 텍스트 데이터를 모아요
- 토큰화 — 문장을 단어 단위로 쪼갭니다
- 불용어 제거 — "이", "가", "를" 같은 의미 없는 단어를 걸러내요
- 빈도 계산 — Counter로 각 단어가 몇 번 나왔는지 세요
- 시각화 — 막대그래프나 워드클라우드로 한눈에 보여줍니다
머신러닝 실전 시리즈에서 EDA를 먼저 하는 것처럼,
텍스트 분석에서도 빈도 분석이 가장 먼저 하는 EDA인 거예요.
토큰화는 텍스트를 어떻게 쪼개나요?
빈도를 세려면 먼저 텍스트를 단어 단위로 쪼개야 해요.
이걸 토큰화(Tokenization)라고 합니다.
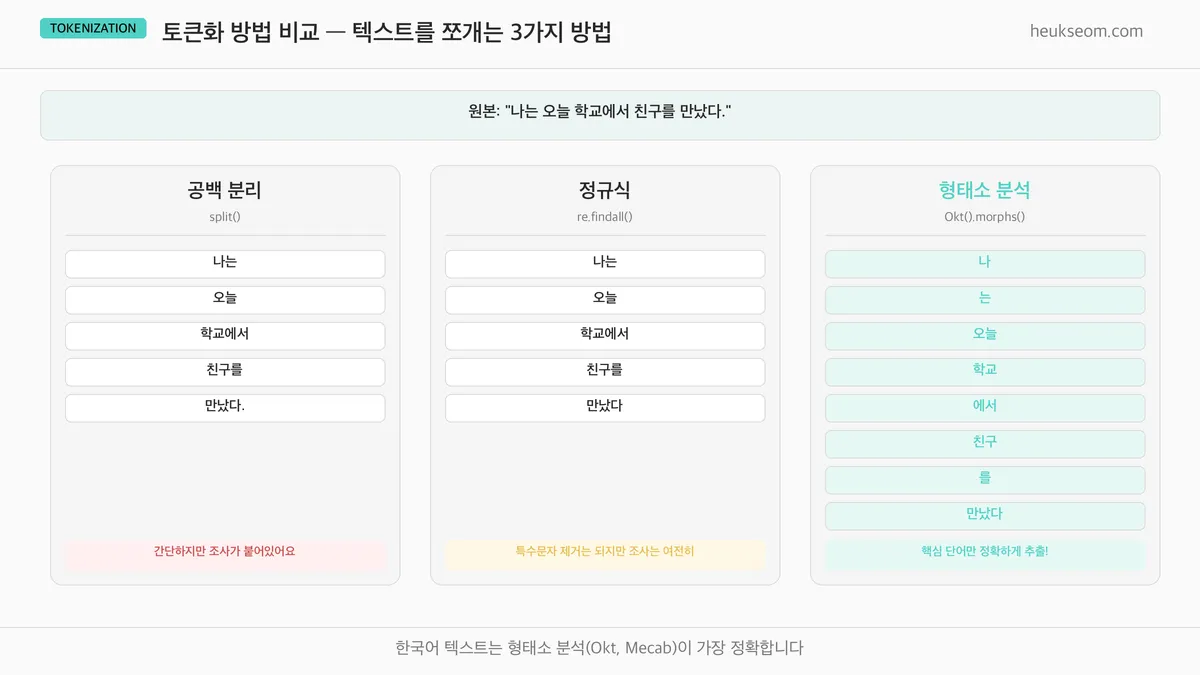
"나는 오늘 학교에서 친구를 만났다."를 세 가지 방법으로 쪼개본 결과예요.
| 방법 | 코드 | 장단점 |
|---|---|---|
| 공백 분리 | text.split() |
간단하지만 조사("학교에서")가 붙어있어요 |
| 정규식 | re.findall() |
특수문자는 제거되지만 조사는 여전히 |
| 형태소 분석 | Okt().morphs() |
핵심 단어만 정확하게 추출! 한국어에 최적 |
이번 실습에서는 정규식(re.findall)으로 간단하게 처리하고,
불용어 제거로 조사를 걸러낼 거예요.
한국어 텍스트를 더 정밀하게 분석하려면 KoNLPy의 Okt를 사용하는 것이 좋습니다.
직접 해봅시다 — AI 뉴스 빈도 분석
AI 관련 뉴스 제목 20개를 모아서, 어떤 키워드가 많이 나오는지 분석해볼게요.
Jupyter 실습 — 텍스트 준비 + 빈도 계산 (셀 2)
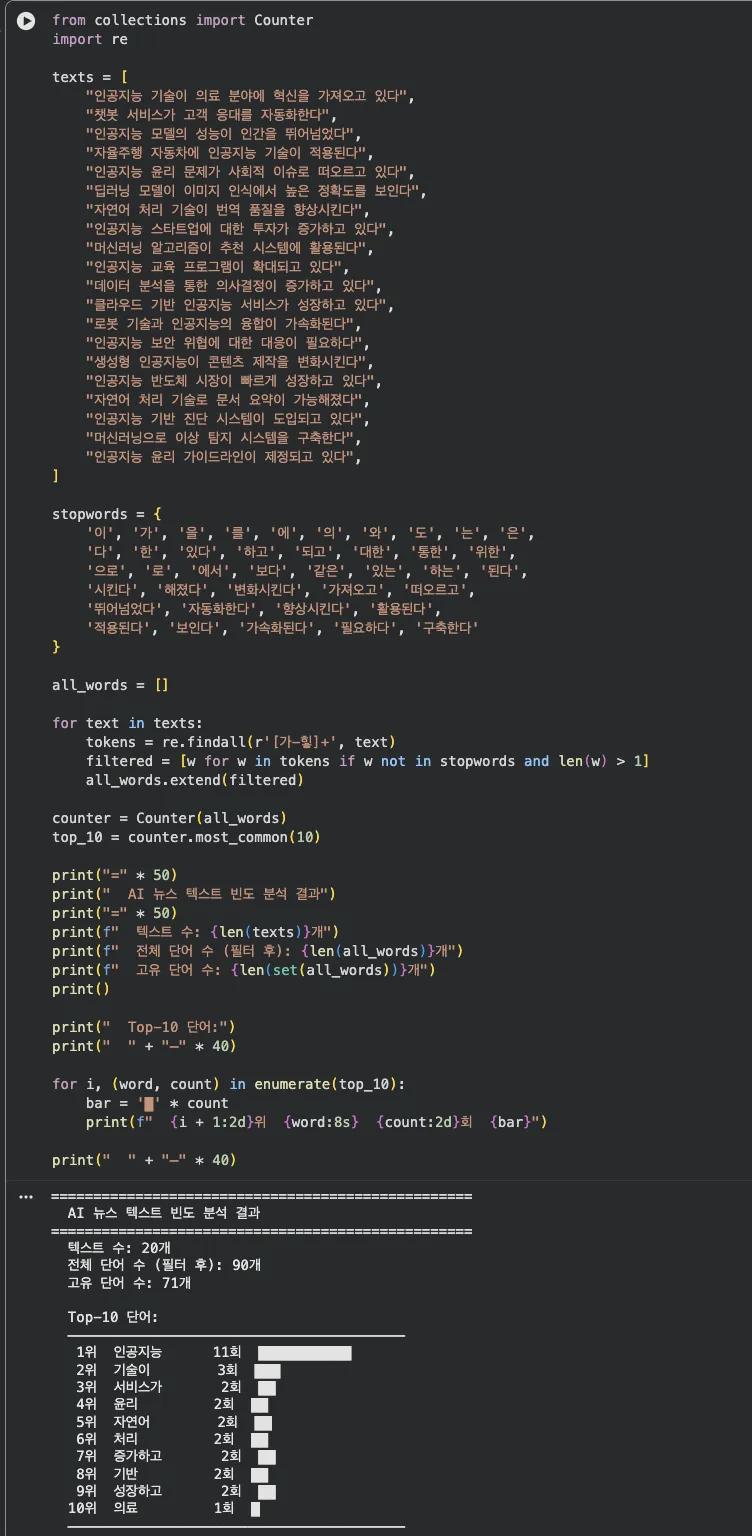
20개 AI 뉴스 제목에서 정규식으로 한글 추출 → 불용어 제거 → Counter로 빈도 계산. "인공지능"이 11회로 압도적 1위예요.
막대그래프로 시각화
Jupyter 실습 — 막대그래프 코드 (셀 3)
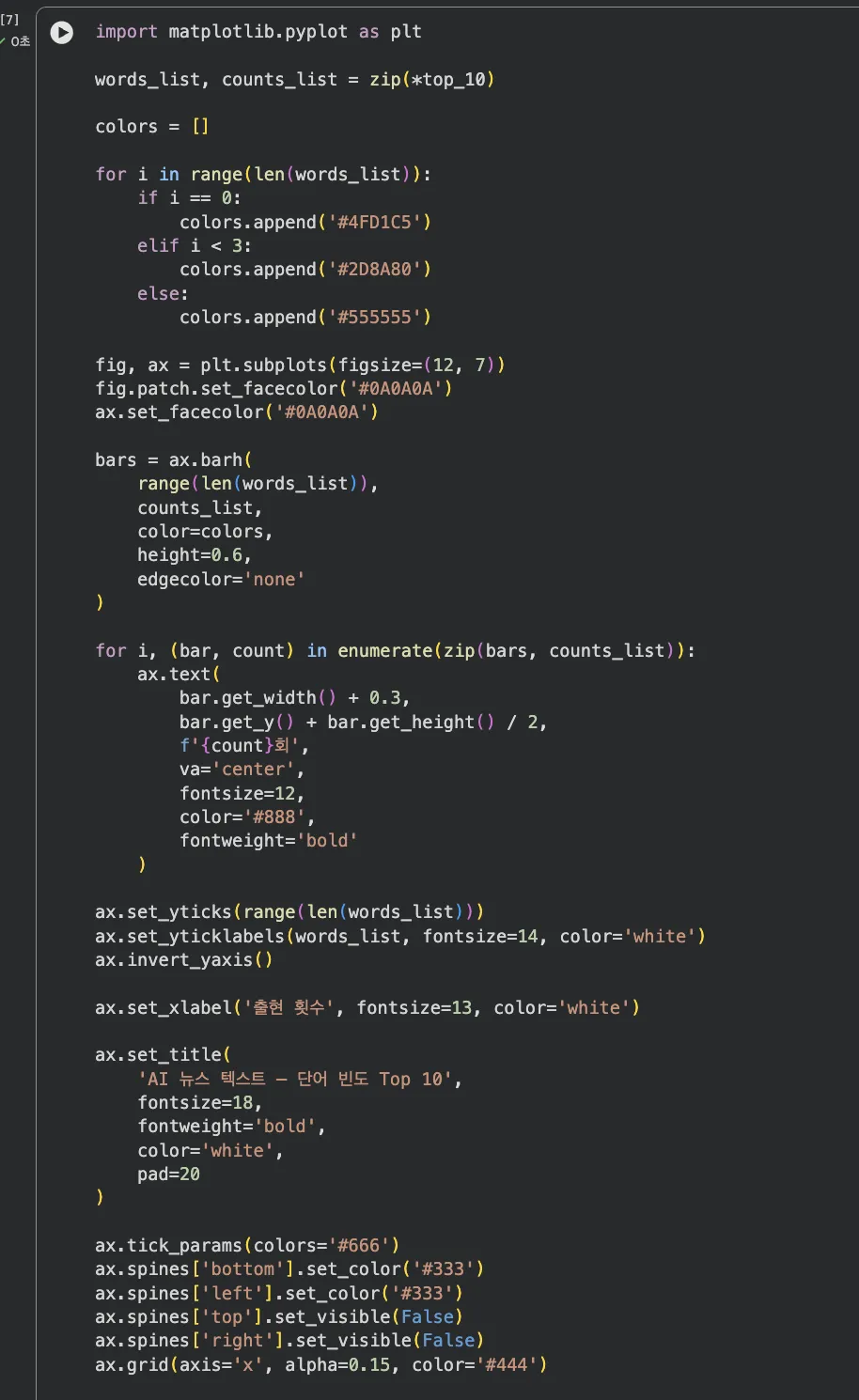
다크 테마 가로 막대그래프로 Top-10 키워드를 시각화합니다.
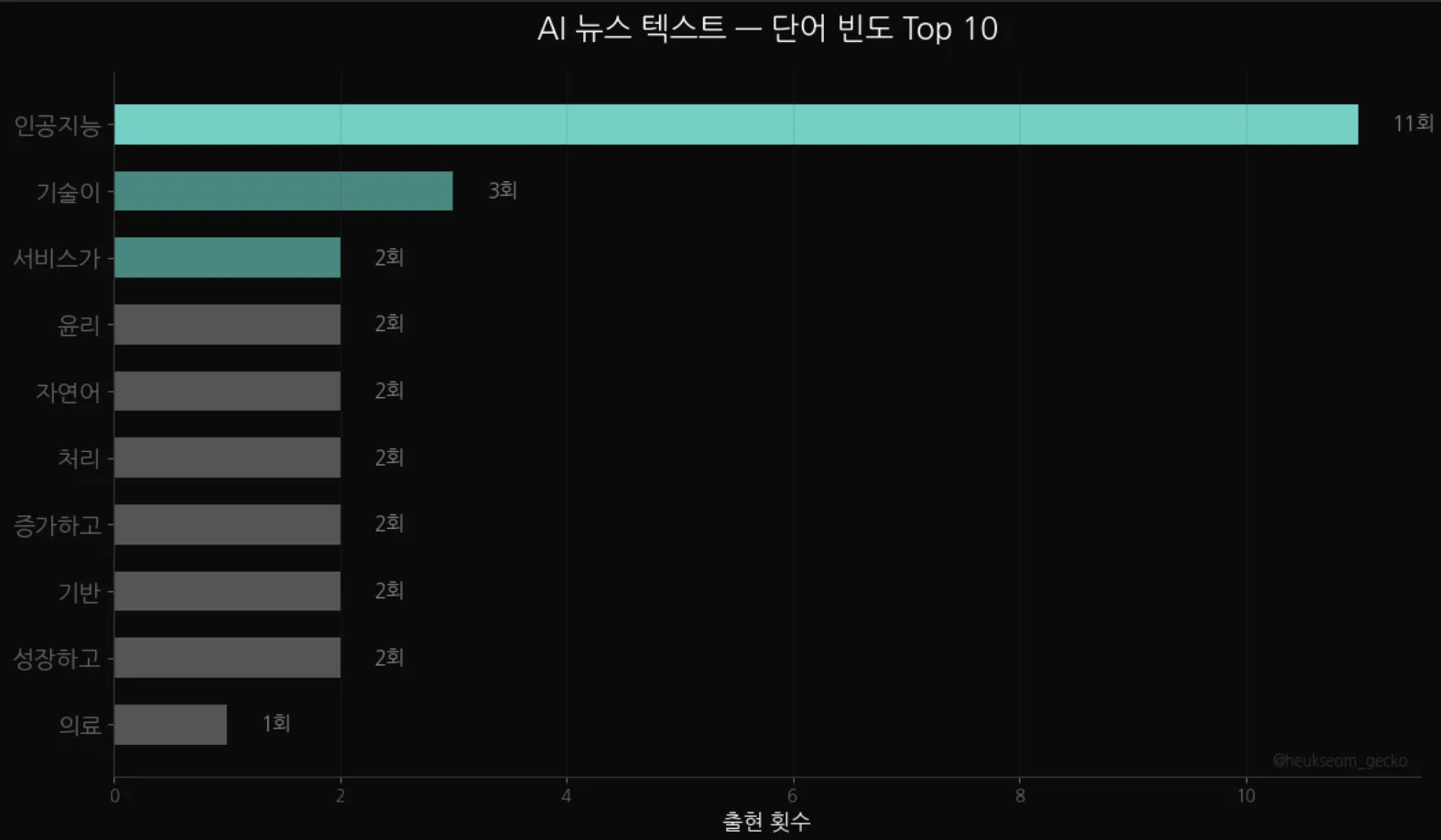
"인공지능"이 11회로 압도적 1위예요.
2위 "기술이"가 3회인 것과 비교하면, 이 뉴스 데이터의 핵심 키워드가 뭔지 한눈에 보이죠? ㅎㅎ
워드클라우드로 핵심 키워드를 어떻게 확인하나요?
막대그래프가 정확한 수치를 보여준다면,
워드클라우드는 직관적으로 핵심 키워드를 파악하기 좋아요.
Jupyter 실습 — 워드클라우드 코드 (셀 4)
wordcloud 라이브러리로 다크 배경 워드클라우드를 생성합니다. 단어 크기 = 출현 빈도예요.

"인공지능"이 압도적으로 크게 보이죠? ㅋㅋ
20개 뉴스 제목 중 11개에 "인공지능"이 들어있으니 당연한 결과예요.
워드클라우드는 보고서나 발표 자료에 넣으면 전달력이 좋습니다.
실무에서는 어떻게 쓰일까요?

| 분야 | 활용 방식 |
|---|---|
| 뉴스 트렌드 | 이번 주 가장 많이 언급된 키워드로 핫이슈를 파악해요 |
| 고객 VOC | 리뷰/댓글에서 "배송", "교환", "느리다" 같은 불만 키워드를 추출합니다 |
| 면접 후기 | 자주 출제되는 질문 유형을 키워드 빈도로 파악할 수 있어요 |
| 검색 키워드 | 사용자가 많이 검색한 키워드 Top-N으로 콘텐츠 전략을 세워요 |
빈도 분석은 가장 단순한 텍스트 분석이지만,
실무에서 가장 자주, 가장 먼저 쓰이는 기법이에요.
더 알고 싶으시다면 — 참고 자료
| 자료 | 설명 |
|---|---|
| NLTK Book (Ch.1) | 텍스트 빈도 분석의 기초를 다루는 교과서예요 |
| KoNLPy 공식 문서 | 한국어 형태소 분석기 사용법 — Okt, Mecab 등 |
| WordCloud 라이브러리 | Python 워드클라우드 생성 공식 문서 |
| Zipf's Law | 단어 빈도의 통계적 법칙 — 상위 몇 개 단어가 전체를 지배합니다 |
정리
핵심 3줄 요약
- 빈도 분석은 텍스트 데이터의 EDA예요 — 가장 먼저, 가장 자주 쓰입니다.
- Counter로 단어 빈도를 세고, 막대그래프와 워드클라우드로 시각화할 수 있어요.
- 한국어는 토큰화 + 불용어 제거가 핵심이에요. 형태소 분석기를 쓰면 더 정확합니다.
다음 편 예고
쉬어가는 편은 여기까지! 4편에서는 다시 딥러닝으로 돌아갑니다.
2편에서 RNN의 한계(장기 의존성 문제)를 얘기했었죠?
4편에서는 이걸 해결하는 LSTM(Long Short-Term Memory)으로
사람 이름만 보고 국적을 맞추는 분류기를 만들어볼 거예요.
"Nakamura" → 일본, "Mueller" → 독일, "김" → 한국. 기대해주세요!