
[딥러닝 기초 4편] LSTM 이름 국적 분류기 — 기억하는 신경망
RNN은 긴 문장에서 앞부분을 까먹습니다. LSTM은 '기억할 것/잊을 것'을 선택하는 게이트로 이 문제를 해결해요. 사람 이름만 보고 국적을 맞추는 분류기를 직접 만들어봅시다.
시작하며 — RNN의 기억력 문제
2편에서 RNN으로 다음 단어를 예측하는 모델을 만들어봤죠?
잘 작동했지만, 한 가지 한계가 있었죠 — 장기 의존성 문제.
"나는 한국에서 태어나서 ... (30단어) ... [ ]를 잘 한다"
빈칸에 "한국어"가 들어가야 하는데, "한국"이라는 단서가 너무 멀리 있어서
RNN은 기억을 못 합니다. 기울기 소실(Vanishing Gradient) 때문이에요.
이번 편에서는 이 문제를 해결하는 LSTM (Long Short-Term Memory)을 배우고,
재밌는 걸 만들어볼 거예요 — 사람 이름만 보고 국적을 맞추는 분류기!
"Nakamura" → 일본, "Mueller" → 독일, "김민수" → 한국. 재밌지 않나요? ㅎㅎ
RNN vs LSTM — 뭐가 다를까요?
RNN은 긴 문장에서 앞쪽 정보를 잊어버리는 기울기 소실 문제가 있습니다. LSTM은 Cell State라는 별도의 기억 통로를 추가해서 중요한 정보를 오래 기억할 수 있게 만든 구조입니다. 3개의 게이트(forget, input, output)가 어떤 정보를 기억하고 잊을지 학습합니다.
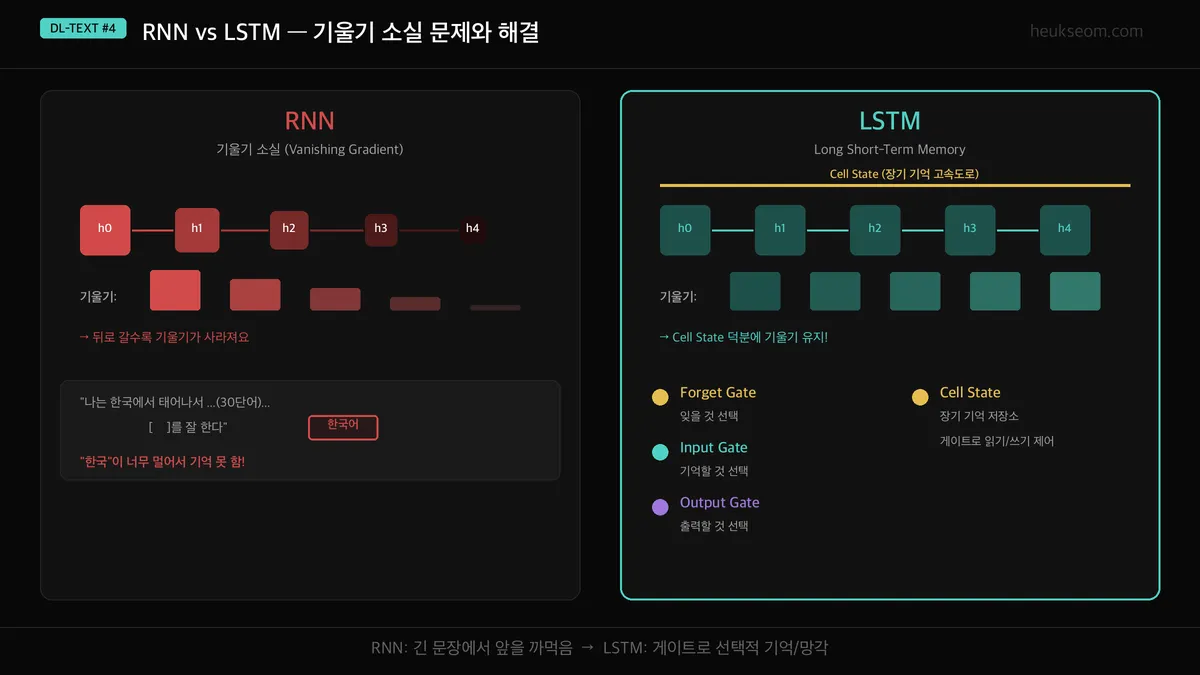
왼쪽이 RNN, 오른쪽이 LSTM이에요.
RNN은 시간이 지날수록 기울기가 점점 작아져요 (빨간 막대가 줄어드는 거 보이시죠?).
그래서 먼 과거의 정보를 학습하지 못합니다.
LSTM은 Cell State라는 "장기 기억 고속도로"가 있어요.
이 고속도로를 통해 중요한 정보가 손실 없이 먼 미래까지 전달됩니다.
기울기 막대가 일정하게 유지되는 게 보이시죠?
LSTM 내부에서 3개의 게이트는 어떻게 작동하나요?
LSTM이 "선택적 기억"을 할 수 있는 비결은 3개의 게이트에 있어요.
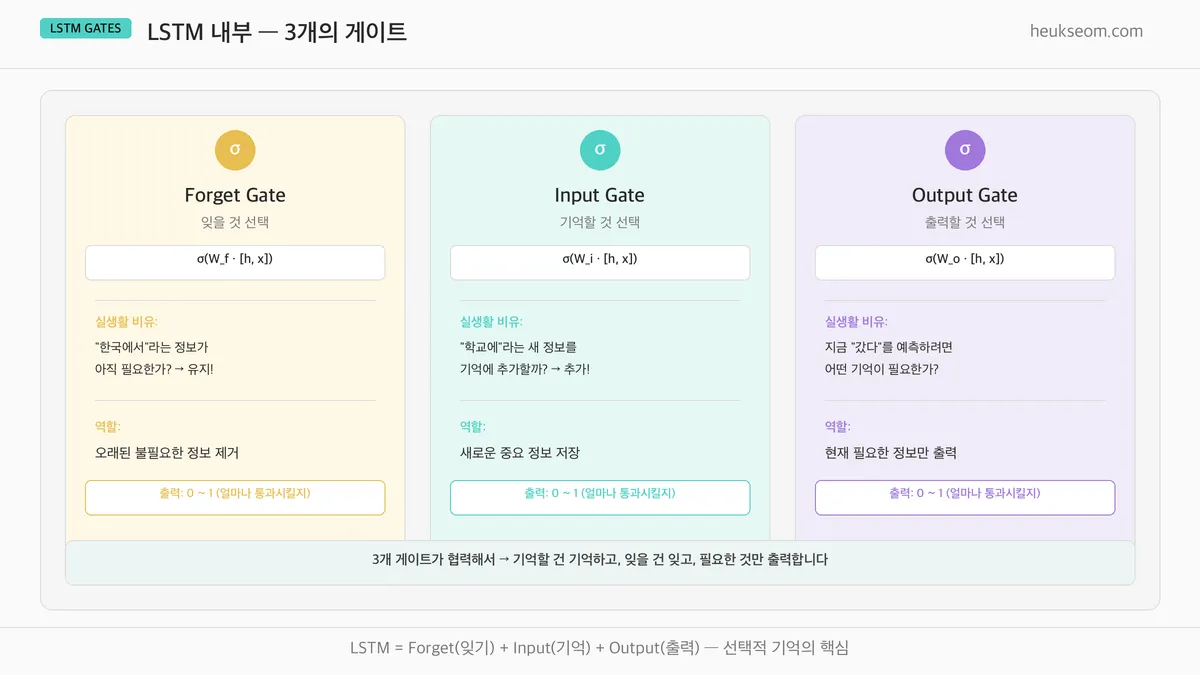
| 게이트 | 역할 | 비유 |
|---|---|---|
| Forget Gate | 이전 기억 중 뭘 잊을지 결정 | "이 정보 아직 필요해?" → 불필요하면 제거 |
| Input Gate | 새 정보 중 뭘 기억할지 결정 | "이 새 정보 중요해?" → 중요하면 저장 |
| Output Gate | 현재 기억 중 뭘 출력할지 결정 | "지금 뭘 내보내야 해?" → 필요한 것만 출력 |
3개 게이트 모두 0~1 사이의 값을 출력해요 (시그모이드 함수!).
0이면 "완전히 차단", 1이면 "완전히 통과"
이 게이트들이 협력해서 기억할 건 기억하고, 잊을 건 잊고, 필요한 것만 출력합니다.
더 깊이 알고 싶다면
Chris Olah — Understanding LSTM Networks
LSTM 게이트를 시각적으로 가장 잘 설명한 블로그예요. 강력 추천합니다.
이름 국적 분류기 — 어떻게 동작할까요?
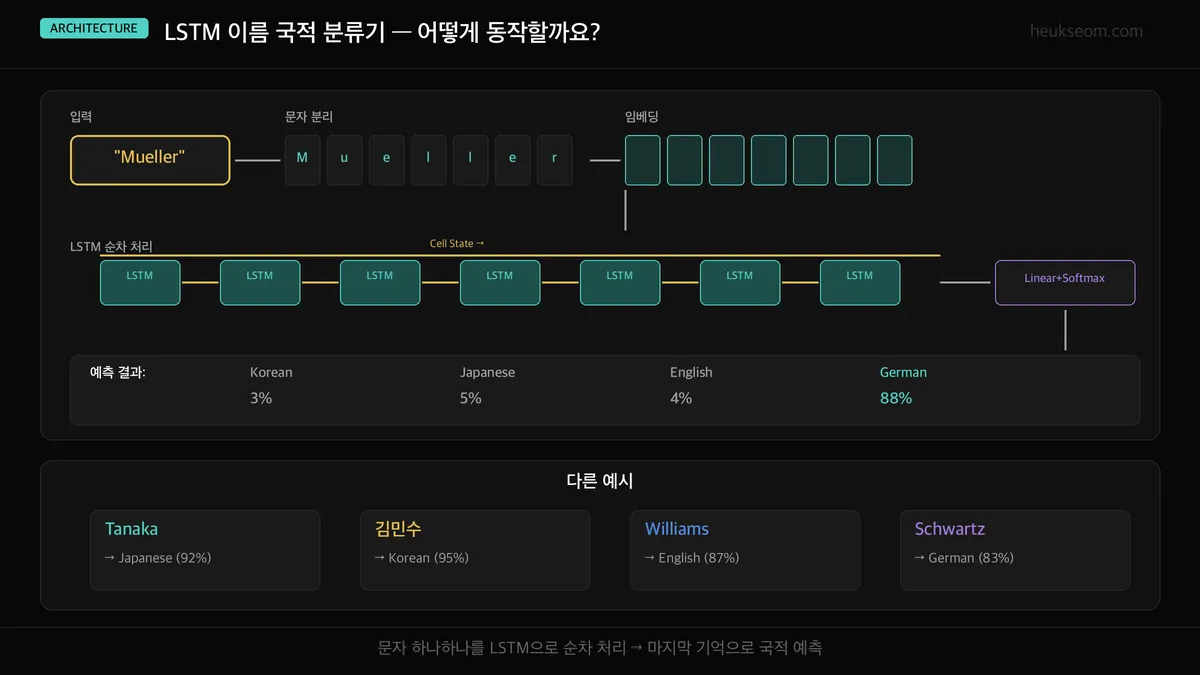
"Mueller"라는 이름이 들어오면:
- 문자 분리 — ['M', 'u', 'e', 'l', 'l', 'e', 'r']로 쪼개요
- 임베딩 — 각 문자를 32차원 벡터로 변환합니다
- LSTM 순차 처리 — 문자를 하나씩 순서대로 읽으면서 기억을 쌓아요
- 마지막 기억 → Linear → Softmax → "German 88%"
왜 문자 단위(Character-Level)로 할까요?
단어 단위로 하면 "Mueller"라는 단어가 사전에 없을 수 있지만,
문자 단위로 하면 알파벳과 한글만으로 어떤 이름이든 처리 가능합니다.
직접 만들어봅시다 — PyTorch LSTM 분류기
한국, 일본, 영미권, 독일 이름을 각 30개씩 준비하고,
Bidirectional LSTM(양방향)으로 학습시켜볼게요.
Jupyter 실습 — 데이터 준비 + 모델 정의 (셀 2)
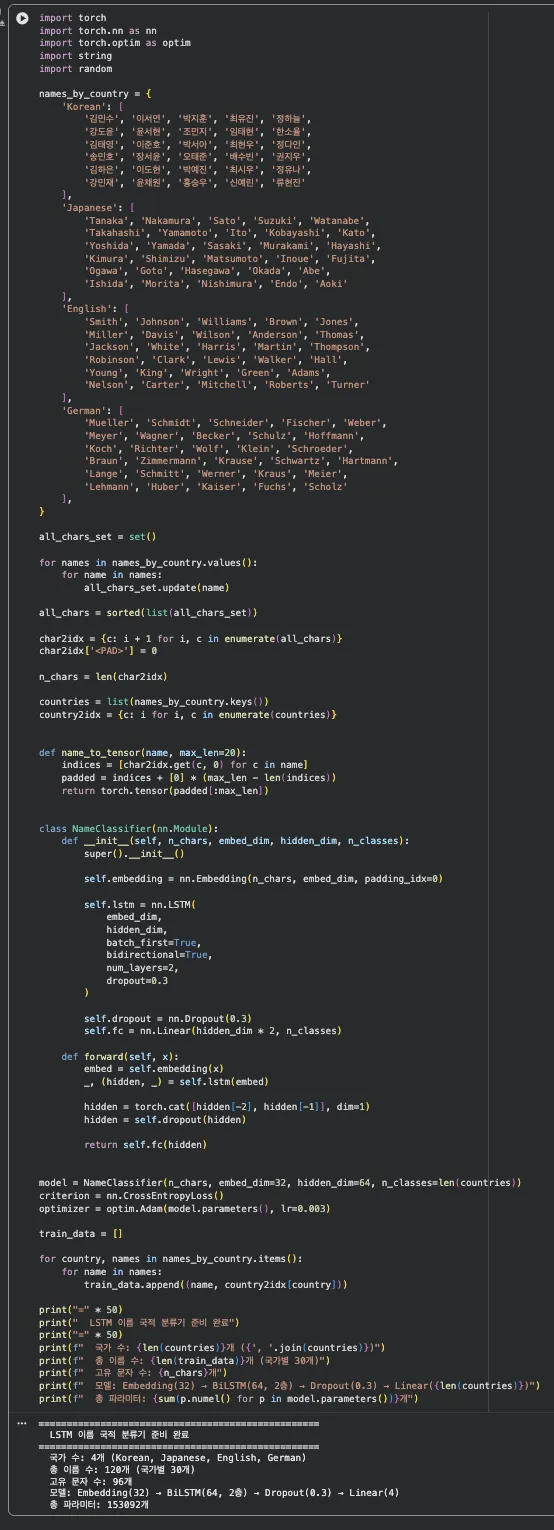
4개 국가 × 30개 이름 = 120개 학습 데이터. Embedding(32) → BiLSTM(64, 2층) → Dropout(0.3) → Linear(4) 구조예요.
학습
200 에포크 동안 학습시킵니다. Dropout을 넣어서 과적합을 방지했어요.
Jupyter 실습 — 학습 코드 (셀 3)
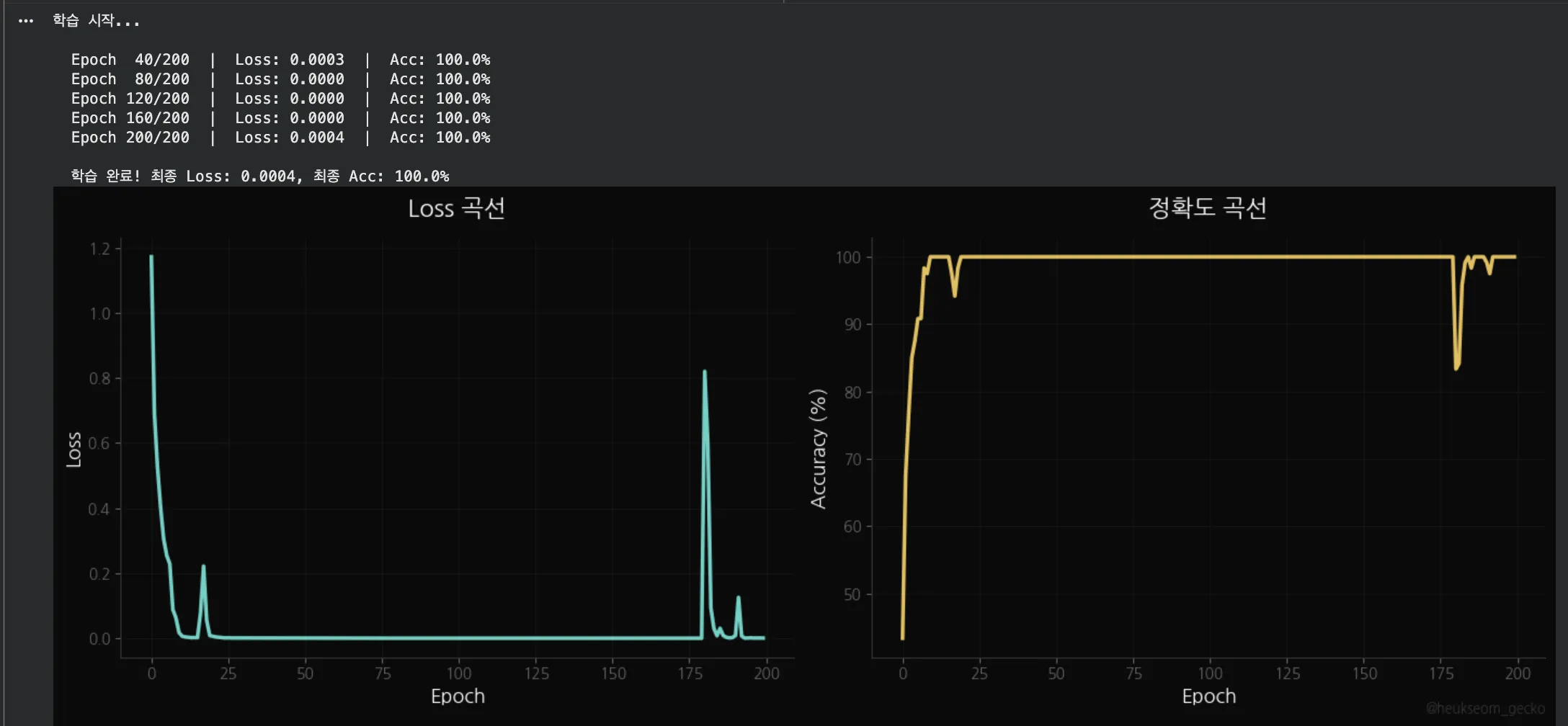
학습 곡선에서 중간중간 스파이크가 보이는데, 이건 Dropout 때문이에요.
학습할 때 뉴런의 30%를 랜덤으로 꺼서 과적합을 방지하는 기법인데,
그 과정에서 일시적으로 Loss가 올라갔다가 다시 내려오는 현상이 나타납니다. 정상적인 패턴입니다.
결과를 볼까요 — 이름으로 국적 맞추기
학습이 끝난 모델에게 학습 데이터에 없는 새로운 이름을 넣어봤어요.
Jupyter 실습 — 예측 테스트 코드 (셀 4)
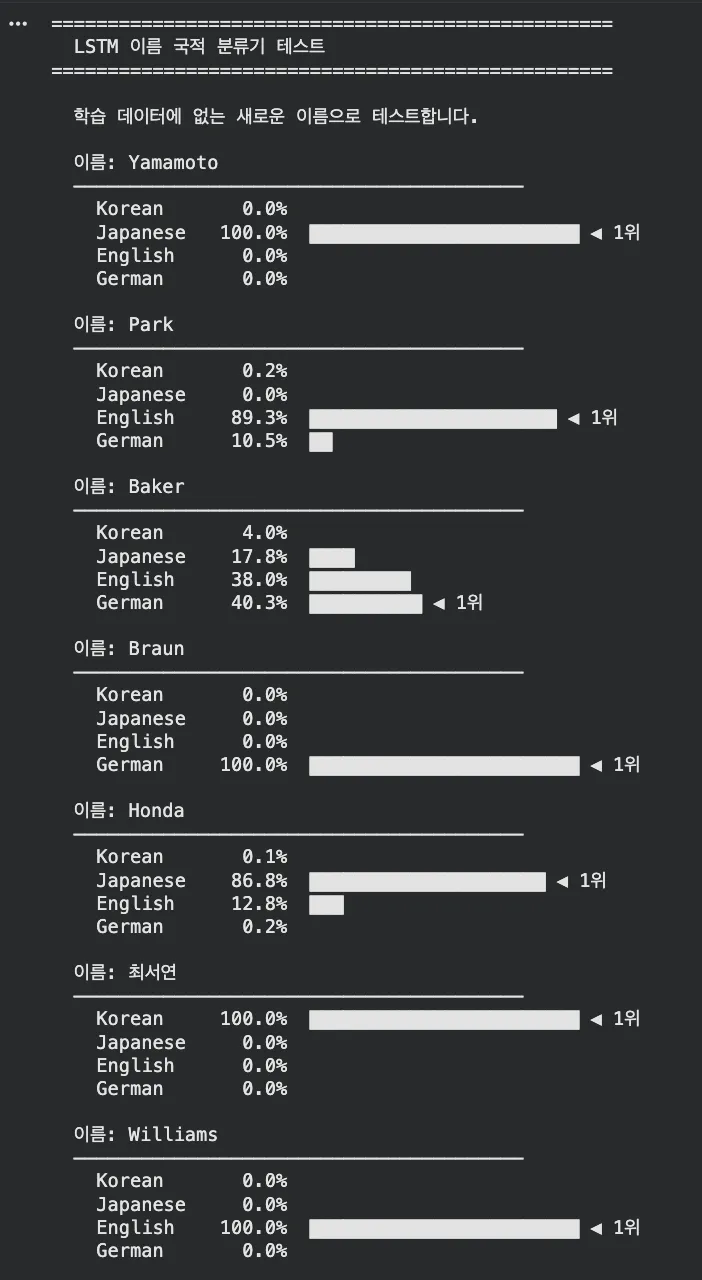

| 이름 | 예측 | 확률 | 해석 |
|---|---|---|---|
| Yamamoto | Japanese | 100% | 'moto' 패턴 → 일본 |
| Braun | German | 100% | 'aun' 패턴 → 독일 |
| 최서연 | Korean | 100% | 한글 문자 → 한국 |
| Williams | English | 100% | 'lliams' 패턴 → 영미권 |
| Schwartz | German | 100% | 'sch', 'tz' 패턴 → 독일 |
| Honda | Japanese | 86.8% | 'onda' 패턴 → 일본 (약간 불확실) |
LSTM이 문자 하나하나의 패턴을 학습한 거예요!
'sch', 'tz' → 독일, 'moto', 'shi' → 일본, 한글 → 한국, 'son', 'ker' → 영미권.
120개 이름으로 학습한 작은 모델인데도 꽤 정확하죠? ㅋㅋ
더 알고 싶으시다면 — 참고 자료
| 자료 | 설명 |
|---|---|
| Chris Olah — Understanding LSTM Networks | LSTM 게이트를 시각적으로 가장 잘 설명한 블로그예요 |
| PyTorch 공식 RNN 분류 튜토리얼 | 이번 편과 비슷한 공식 튜토리얼이에요 |
| Hochreiter & Schmidhuber (1997) | LSTM 원논문 — 여기서 모든 게 시작됐습니다 |
| Graves (2012) — Supervised Sequence Labelling | RNN/LSTM을 활용한 시퀀스 라벨링 교과서 |
정리
핵심 3줄 요약
- RNN은 기울기 소실로 긴 시퀀스를 처리하지 못하지만, LSTM은 게이트로 해결합니다.
- LSTM의 3개 게이트(Forget/Input/Output)가 "기억할 것/잊을 것/출력할 것"을 선택해요.
- 문자 수준(Character-Level) LSTM으로 이름의 패턴을 학습하면 국적까지 분류할 수 있습니다.
다음 편 예고 (시리즈 마지막!)
1~4편에서 Word2Vec, RNN, 빈도 분석, LSTM을 다뤘어요.
매번 코드에서 반복되는 게 있었죠 — 텍스트를 쪼개고, 불용어 빼고, 형태 통일하고...
5편에서는 이 전처리 과정을 하나의 "파이프라인"으로 묶어봅니다.
NLTK로 체계적인 텍스트 전처리 파이프라인을 구축하는 시리즈 마무리편이에요!