
[딥러닝 기초 5편] 텍스트 전처리 파이프라인 — NLP의 기초 체력
매번 반복되는 전처리를 하나의 파이프라인으로 묶어봅시다. NLTK로 정규화 → 토큰화 → 불용어 제거 → 어간 추출까지, 체계적인 전처리 클래스를 직접 만들어요.
시작하며 — 매번 반복되는 전처리, 파이프라인으로 묶자
1~4편에서 Word2Vec, RNN, 빈도 분석, LSTM을 만들어봤죠.
근데 매번 코드에서 반복되는 게 있었어요.
"텍스트를 쪼개고, 의미 없는 단어 빼고, 형태 통일하고..."
이걸 매번 즉석에서 하면 실수가 생깁니다.
어떤 코드에서는 불용어를 뺐는데, 다른 코드에서는 안 빼고...
어떤 데이터는 소문자 변환을 했는데, 다른 데이터는 안 하기도 하고요.
실전에서는 이 전처리 과정을 하나의 "파이프라인"으로 묶어둡니다.
입력: 날것의 텍스트 → 파이프라인 통과 → 출력: 깨끗한 토큰 리스트.
머신러닝 실전 시리즈 6편의 sklearn Pipeline처럼요.
이번 편은 이 시리즈의 마무리이자, 동시에 앞으로 모든 NLP 작업의 기반이 돼요.
전처리 파이프라인은 어떤 5단계로 구성되나요?
텍스트 전처리 파이프라인은 소문자 변환, 특수문자 제거, 토큰화, 불용어 제거, 어간 추출의 5단계입니다. NLTK 기반으로 각 단계를 클래스로 묶으면 어떤 텍스트든 동일한 품질로 정제할 수 있는 재사용 가능한 도구가 됩니다.
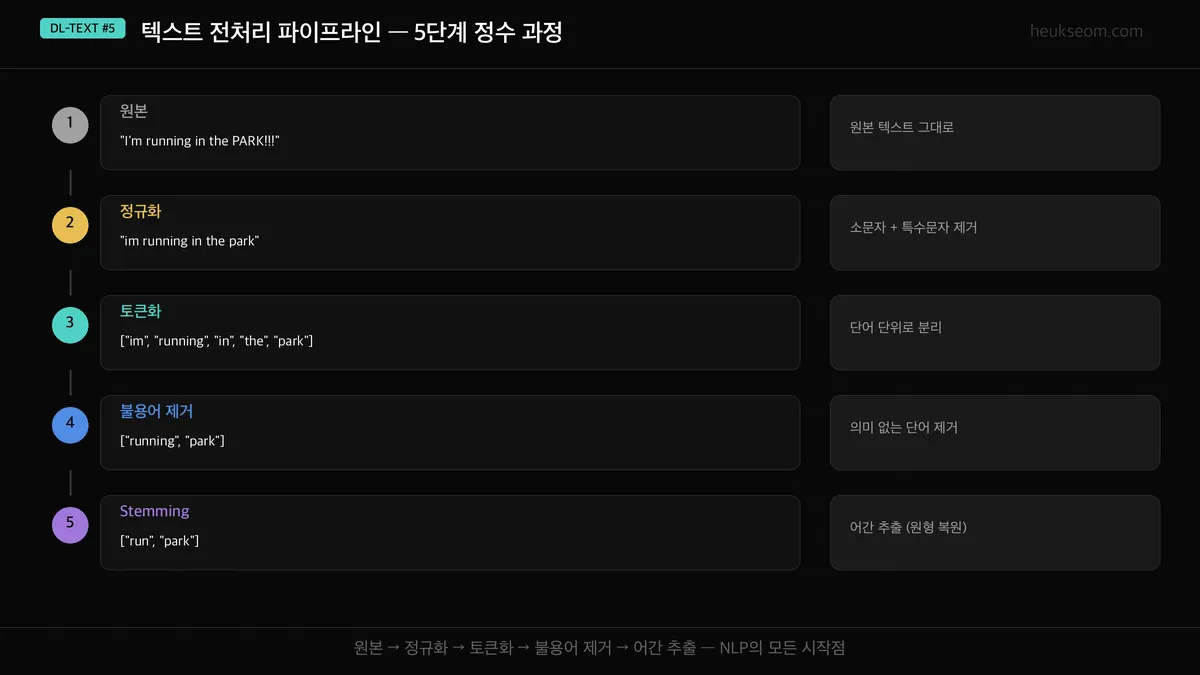
"I'm running in the PARK!!!"가 어떻게 변환되는지 단계별로 볼게요:
- 정규화 — 소문자 변환 + 특수문자 제거 → "im running in the park"
- 토큰화 — 단어 단위로 분리 → ["im", "running", "in", "the", "park"]
- 불용어 제거 — "in", "the" 같은 의미 없는 단어 제거 → ["running", "park"]
- 어간 추출 — "running" → "run"으로 원형 복원 → ["run", "park"]
정수기의 필터처럼, 각 단계를 거치면서 텍스트가 점점 깨끗해집니다.
Stemming과 Lemmatization은 어떤 차이가 있나요?
4단계 "어간 추출"에서 선택지가 두 개 있어요.

| 원본 | Stemming | Lemmatization |
|---|---|---|
| running | run | run |
| studies | studi (과도 절단!) | study (정확!) |
| wolves | wolv (과도 절단!) | wolf (정확!) |
| beautiful | beauti (과도 절단!) | beautiful (보존) |
Stemming은 규칙 기반이라 빠르지만, "studies" → "studi"처럼 과도하게 잘라버릴 수 있어요.
Lemmatization은 사전을 참조해서 정확하지만, 좀 느립니다.
대량 데이터를 빠르게 처리할 때는 Stemming, 정밀 분석에는 Lemmatization이 적합합니다.
직접 만들어봅시다 — NLTK 전처리 파이프라인 클래스
Python 클래스로 전처리 파이프라인을 만들면,
preprocessor.process(text) 한 줄로 전처리가 끝나요.
Jupyter 실습 — NLTK 설치 + 파이프라인 클래스 정의 (셀 1~2)
NLTK 설치 후 필요한 데이터(punkt, stopwords, wordnet)를 다운로드합니다.
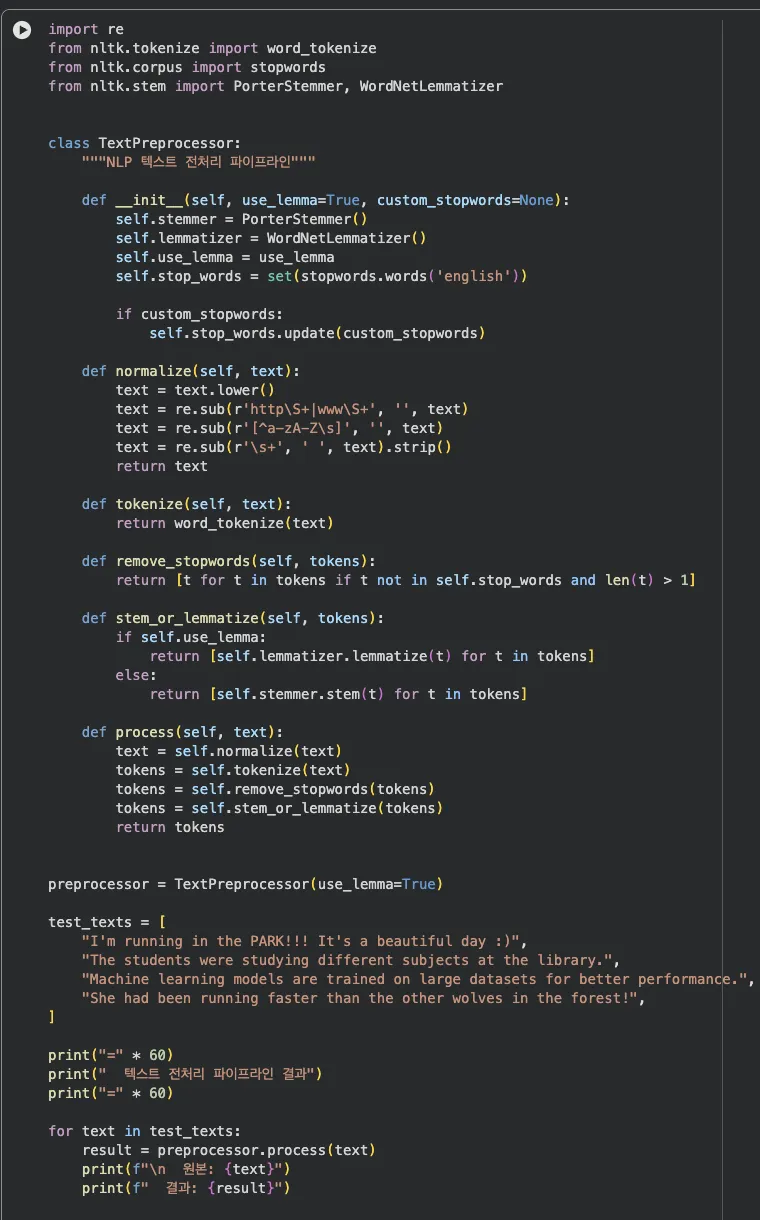
normalize → tokenize → remove_stopwords → stem_or_lemmatize 4단계를 하나의 클래스로 묶었어요.
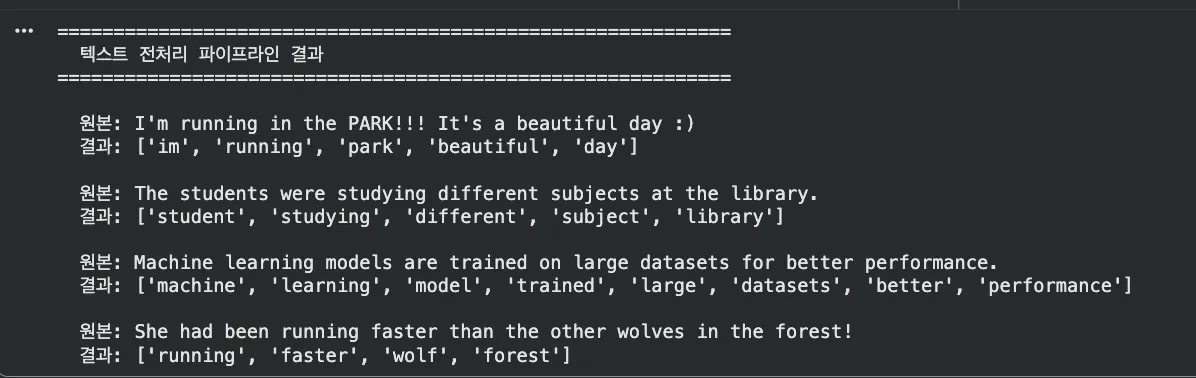
"wolves" → "wolf", 대문자 → 소문자, 특수문자 제거, 불용어 제거까지
한 줄(preprocessor.process(text))로 전부 처리됐어요!
Stemming과 Lemmatization 결과를 비교하면 어떤가요?
Jupyter 실습 — 단계별 변환 과정 + 비교 차트 (셀 3)
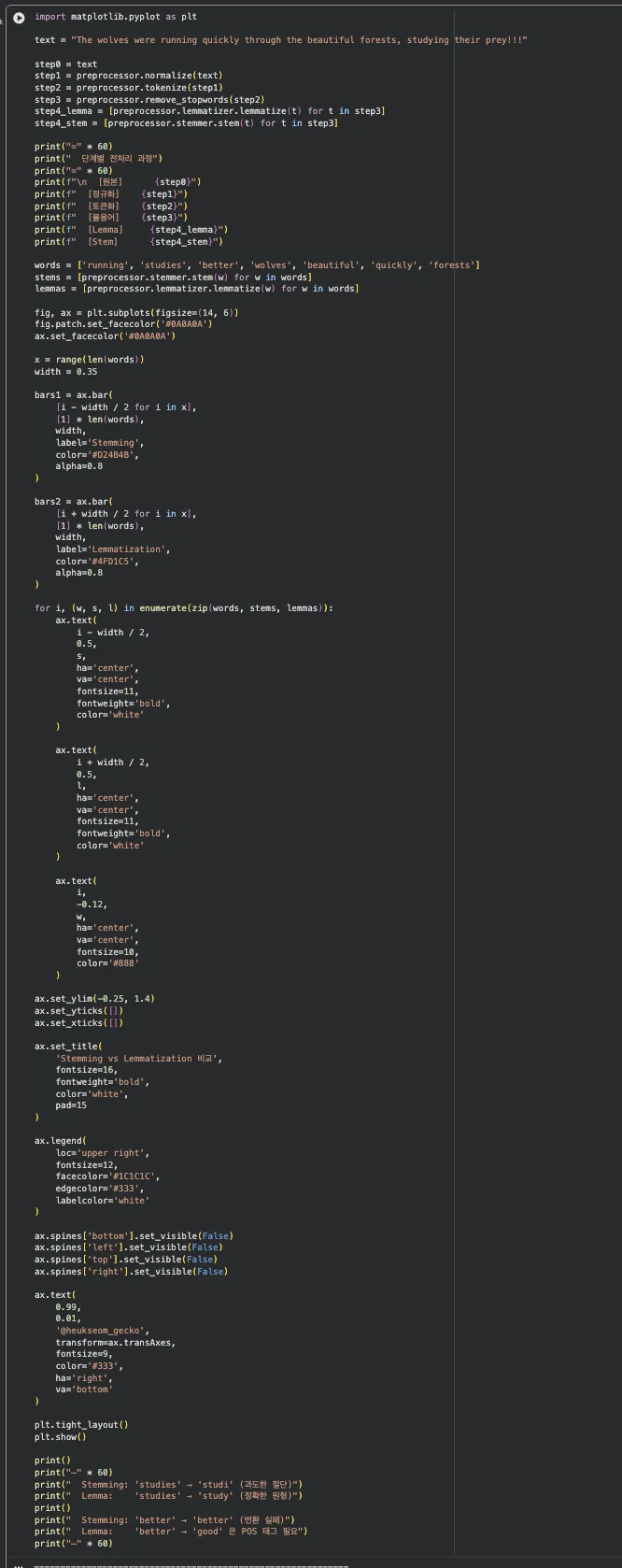
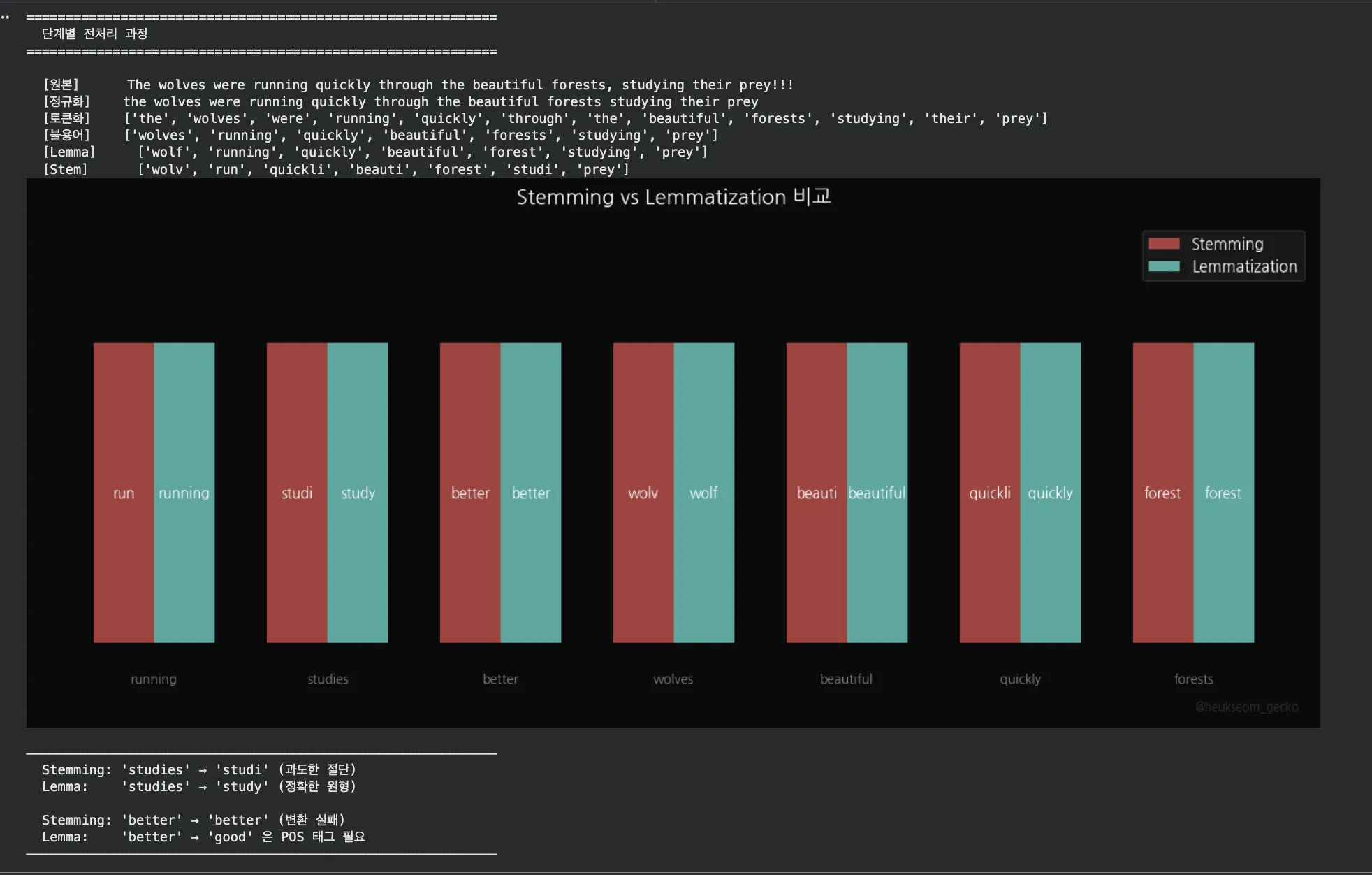
빨간색이 Stemming, 민트색이 Lemmatization이에요.
"studies" → Stem은 "studi", Lemma는 "study".
"wolves" → Stem은 "wolv", Lemma는 "wolf".
정확도 차이가 확실히 보이시죠?
이 파이프라인은 어디에 연결해서 쓸 수 있나요?
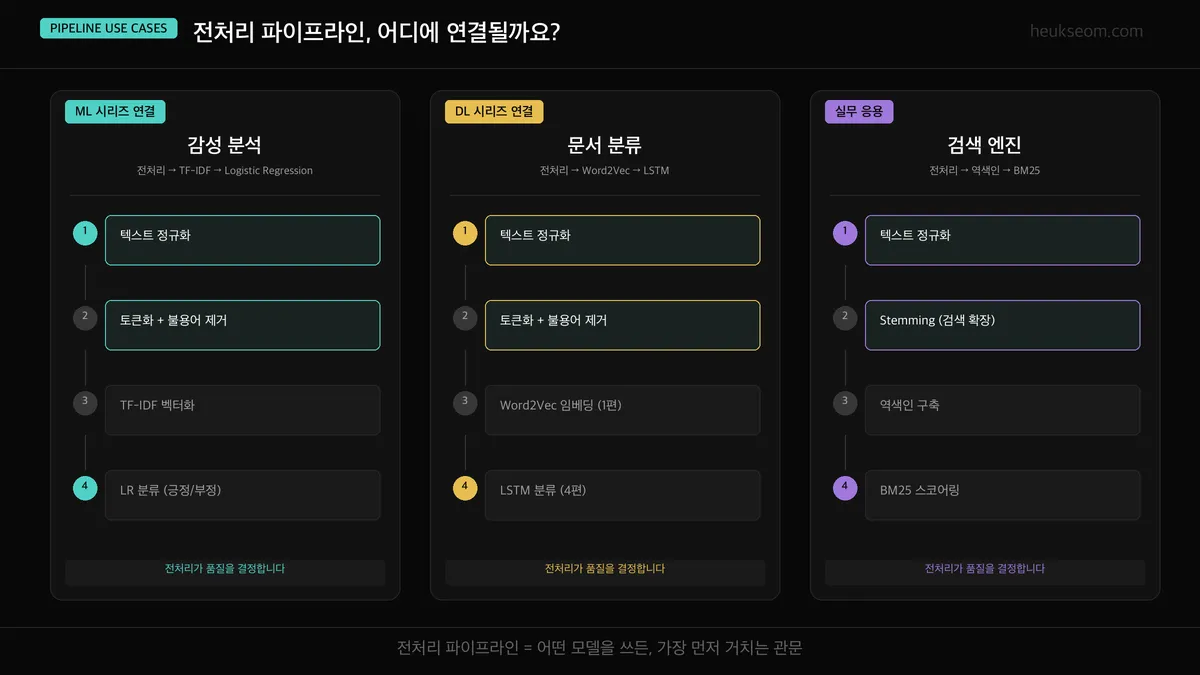
| 시나리오 | 파이프라인 | 연결 |
|---|---|---|
| 감성 분석 | 전처리 → TF-IDF → Logistic Regression | ML 시리즈와 연결 |
| 문서 분류 | 전처리 → Word2Vec(1편) → LSTM(4편) | 이번 DL 시리즈와 연결 |
| 검색 엔진 | 전처리 → 역색인 → BM25 스코어링 | 실무 응용 |
어떤 모델을 쓰든, 전처리가 가장 먼저예요.
전처리 품질이 곧 모델 성능을 결정합니다.
더 알고 싶다면 — 참고 자료
| 자료 | 설명 |
|---|---|
| NLTK Book (Ch.3) | 텍스트 전처리의 체계적 설명이에요 |
| spaCy 공식 문서 | 산업 수준 NLP 전처리 라이브러리 — NLTK보다 빠릅니다 |
| Hugging Face Tokenizers | 최신 서브워드 토크나이저 (BPE, WordPiece) — GPT/BERT가 사용하는 방식이에요 |
| Jurafsky & Martin (Ch.2) | 텍스트 정규화 교과서 — NLP의 바이블이에요 |
| KoNLPy 문서 | 한국어 전처리는 여기! Okt, Mecab 등 형태소 분석기 |
시리즈 마무리 — 딥러닝 기초 5편을 돌아보며
이번 편 핵심 3줄 요약
- 전처리 파이프라인은 정규화 → 토큰화 → 불용어 제거 → 어간 추출, 4단계로 구성돼요.
- Stemming은 빠르지만 부정확, Lemmatization은 느리지만 정확합니다.
- 어떤 모델을 쓰든 전처리가 가장 먼저예요 — 전처리 품질 = 모델 성능.
딥러닝 기초 시리즈 전체 여정
| 1편 | Word2Vec — 단어를 의미가 담긴 벡터로 바꾸기 |
| 2편 | RNN — 순서를 기억하는 신경망으로 다음 단어 예측 |
| 3편 | 빈도 분석 — 텍스트의 핵심을 한눈에 파악 |
| 4편 | LSTM — 기억하는 신경망으로 이름 국적 분류 |
| 5편 | 전처리 파이프라인 — NLP의 기초 체력 완성 (이번 편!) |
다음 시리즈 예고
딥러닝 기초 시리즈 5편을 다뤄봤습니다.
다음 시리즈에서는 이미지 처리 딥러닝을 다룰 예정이에요.
CNN(합성곱 신경망), 이미지 분류, 전이 학습까지 — 기대해주세요!