
[NLP 프로젝트 1편] 한국어 뉴스 분류기 — BERT fine-tuning 처음부터 끝까지
뉴스 제목 하나로 카테고리를 맞히는 분류기를 만들어봤습니다. TF-IDF 베이스라인부터 BERT fine-tuning까지, Tokenizer가 텍스트를 어떻게 쪼개는지, [CLS] 토큰이 왜 분류에 쓰이는지, Fine-tuning과 Feature Extraction의 차이까지 KLUE-YNAT 데이터셋으로 직접 확인해봤습니다.
시작하며 — 뉴스 제목 하나로 카테고리를 맞힐 수 있을까?
뉴스 제목 하나 읽고 '아 이건 스포츠 기사구나' 하는 판단, 사람은 0.1초면 됩니다.
모델은 어떻게 할까요?
이번 글에서는 KLUE-YNAT 한국어 뉴스 데이터로 BERT 분류기를 직접 만들어봤습니다.
"손흥민 해트트릭" 같은 뉴스 제목을 넣으면 '스포츠'를 출력하는 모델입니다. ㅎㅎ
개념만 보고 끝내기 아쉬워서, Colab 코드로 실제 학습까지 같이 진행했습니다.
TF-IDF 베이스라인을 먼저 잡고, 그 위에서 BERT fine-tuning으로 성능을 끌어올리는 순서로 정리했습니다.
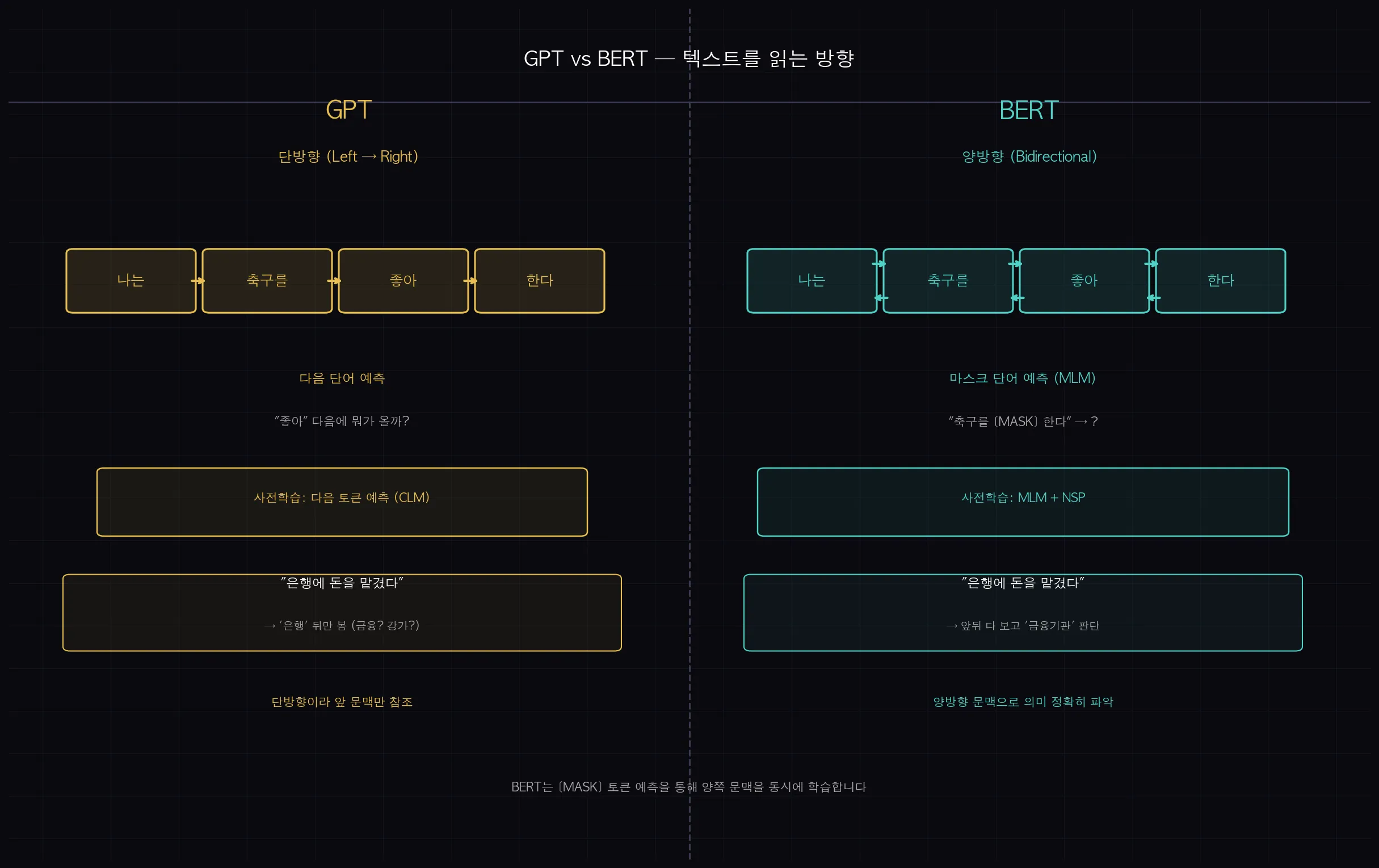
BERT는 어떤 언어 모델인가요?
BERT는 문장을 양방향으로 읽는 언어 모델입니다. GPT가 왼쪽에서 오른쪽으로만 읽는 것과 달리, BERT는 문장 전체를 한 번에 보면서 마스크된 단어를 맞히는 방식으로 학습합니다. 이 덕분에 문맥을 더 정확히 이해할 수 있어서, 텍스트 분류 같은 태스크에서 특히 강합니다.
GPT는 텍스트를 왼쪽에서 오른쪽으로 읽습니다.
"나는 축구를 ___"라는 문장이 있으면 앞 단어들만 보고 다음 단어를 예측하는 방식이에요.
BERT는 반대로 양방향입니다.
문장 전체를 한 번에 보면서 마스크된 단어를 맞히는 방식으로 학습합니다.
"나는 축구를 [MASK] 한다"라는 문장이 있으면, 앞뒤 단어 모두를 참조해서 [MASK] 자리를 채웁니다.
왜 이게 중요할까요?
"은행에 돈을 맡겼다"와 "강가에 은행나무가 있다"에서 '은행'의 의미가 다릅니다.
GPT는 앞 단어만 보기 때문에 '강가에 은행'까지 읽은 시점에선 금융기관인지 나무인지 모릅니다.
BERT는 뒤에 오는 '돈을 맡겼다' 또는 '나무가 있다'까지 보고 의미를 구분하는 거죠.
(쉽게 말하면: BERT는 문장 전체를 한눈에 보는 독자입니다. GPT는 왼쪽부터 한 글자씩 읽어가는 독자고요.)
BERT의 사전학습은 두 가지 방식으로 이뤄집니다.
- MLM (Masked Language Model): 문장에서 일부 토큰을 [MASK]로 가리고, 양방향 문맥을 활용해 맞히는 방식
- NSP (Next Sentence Prediction): 두 문장이 연속된 문장인지 아닌지 판별하는 방식
Tokenizer는 텍스트를 어떻게 숫자로 바꾸나요?
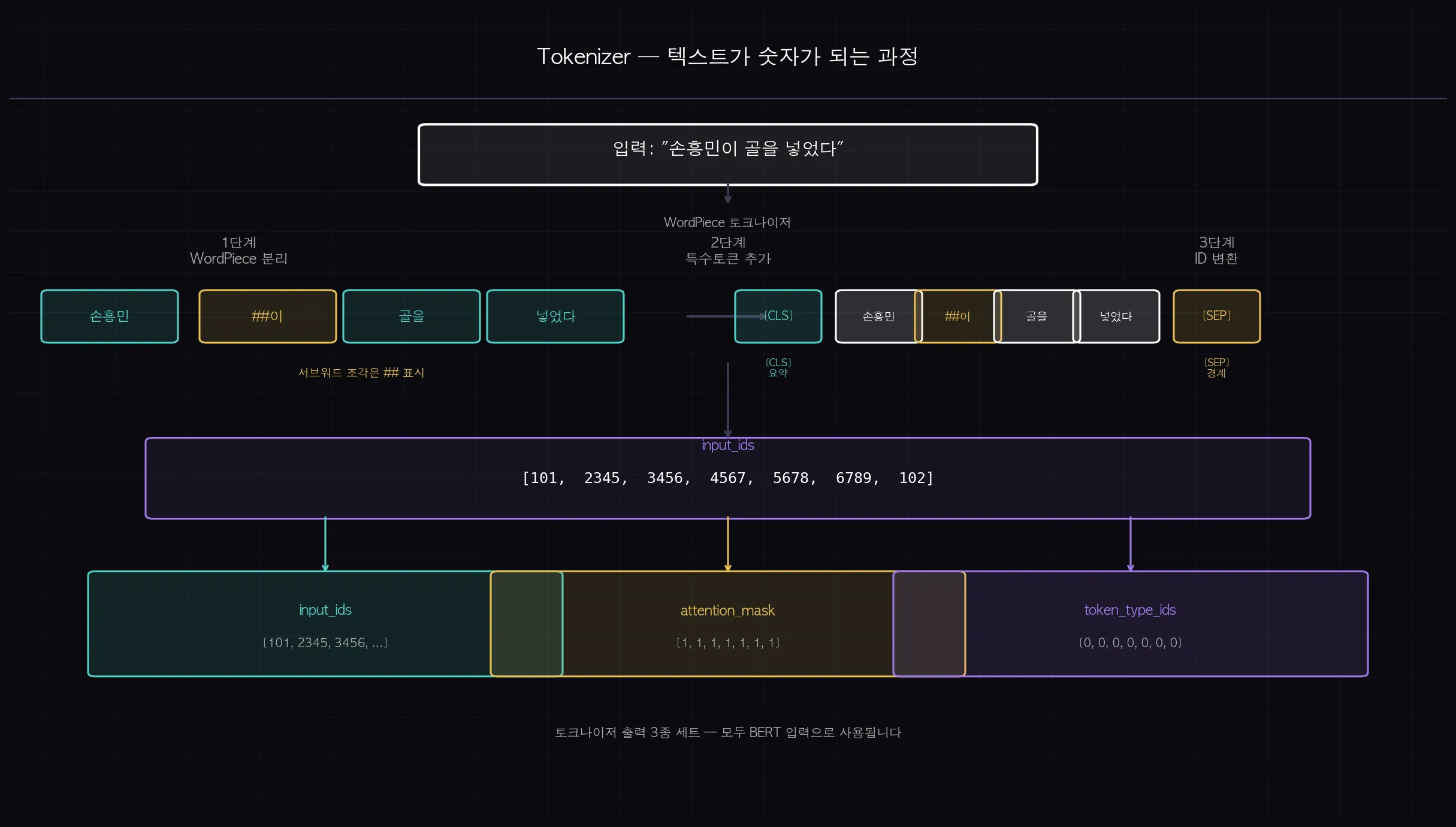
모델은 텍스트를 직접 읽지 못합니다.
모든 입력은 숫자로 변환되어야 하고, 이 변환을 담당하는 게 토크나이저입니다.
BERT는 WordPiece 방식을 씁니다.
사전에 없는 단어를 서브워드 단위로 쪼개는 방식인데요, klue/bert-base 기준으로 "안녕하세요"는 ["안녕", "##하세요"]로 나뉩니다.
"##"이 붙으면 앞 토큰의 연속이라는 뜻입니다.
(쉽게 말하면: 처음 보는 단어가 나와도 작은 조각으로 쪼개서 처리합니다. 완전히 모르는 단어가 생기는 상황을 줄이기 위해서예요.)
토크나이징을 거치면 두 가지 특수 토큰이 추가됩니다.
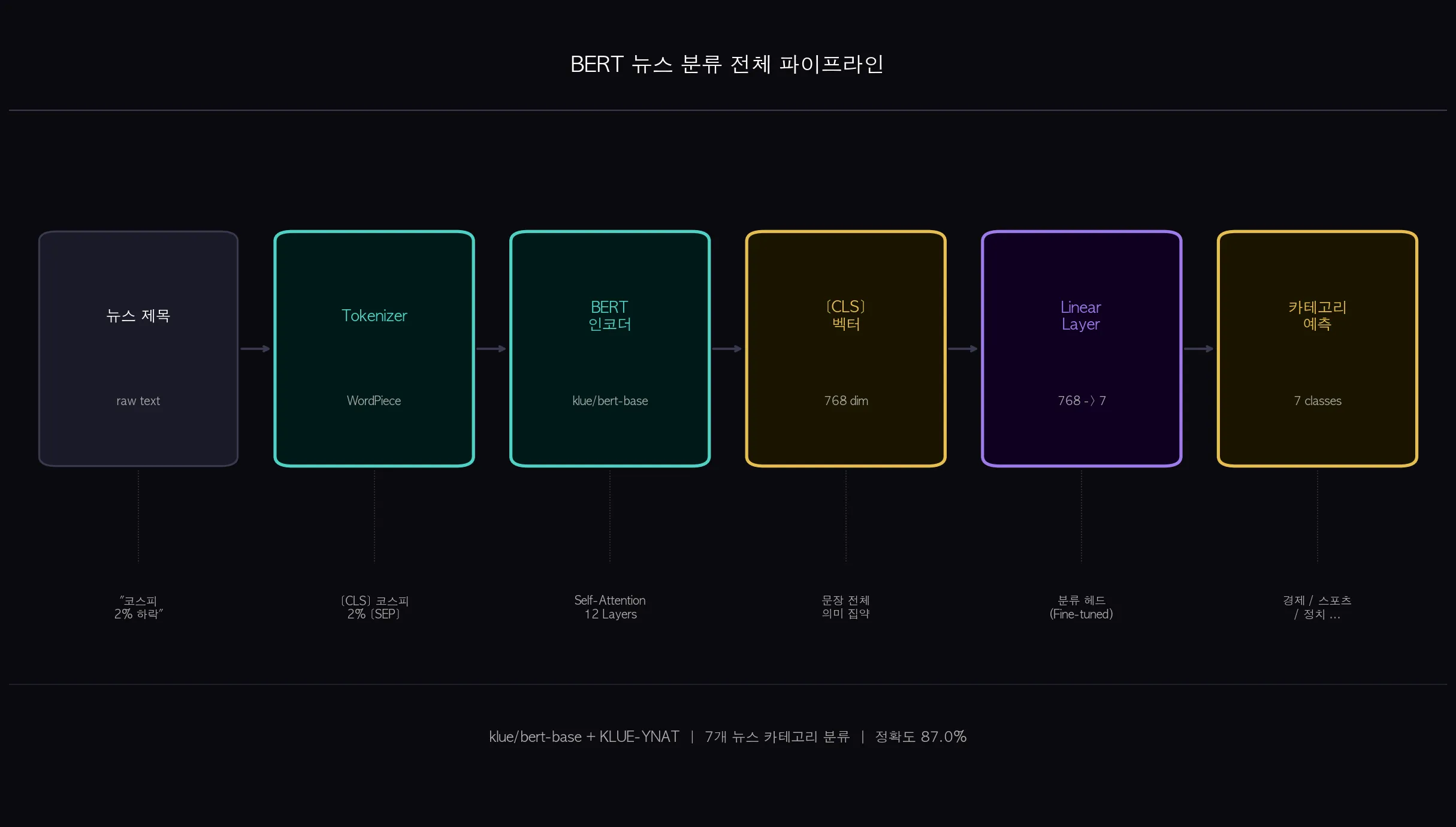
- [CLS]: 문장 맨 앞에 붙는 토큰. 문장 전체 의미를 담는 요약 자리입니다. 분류 태스크에서 핵심 역할을 합니다.
- [SEP]: 문장 끝에 붙는 토큰. 두 문장을 구분하는 경계 역할을 합니다.
토크나이저 출력은 세 가지입니다.
- input_ids: 각 토큰의 어휘 사전 인덱스 번호
- attention_mask: 실제 토큰(1)과 패딩(0)을 구분하는 마스크
- token_type_ids: 두 문장이 있을 때 첫 번째 문장(0)과 두 번째 문장(1) 구분
[CLS] 토큰이 왜 분류에 쓰이나요?
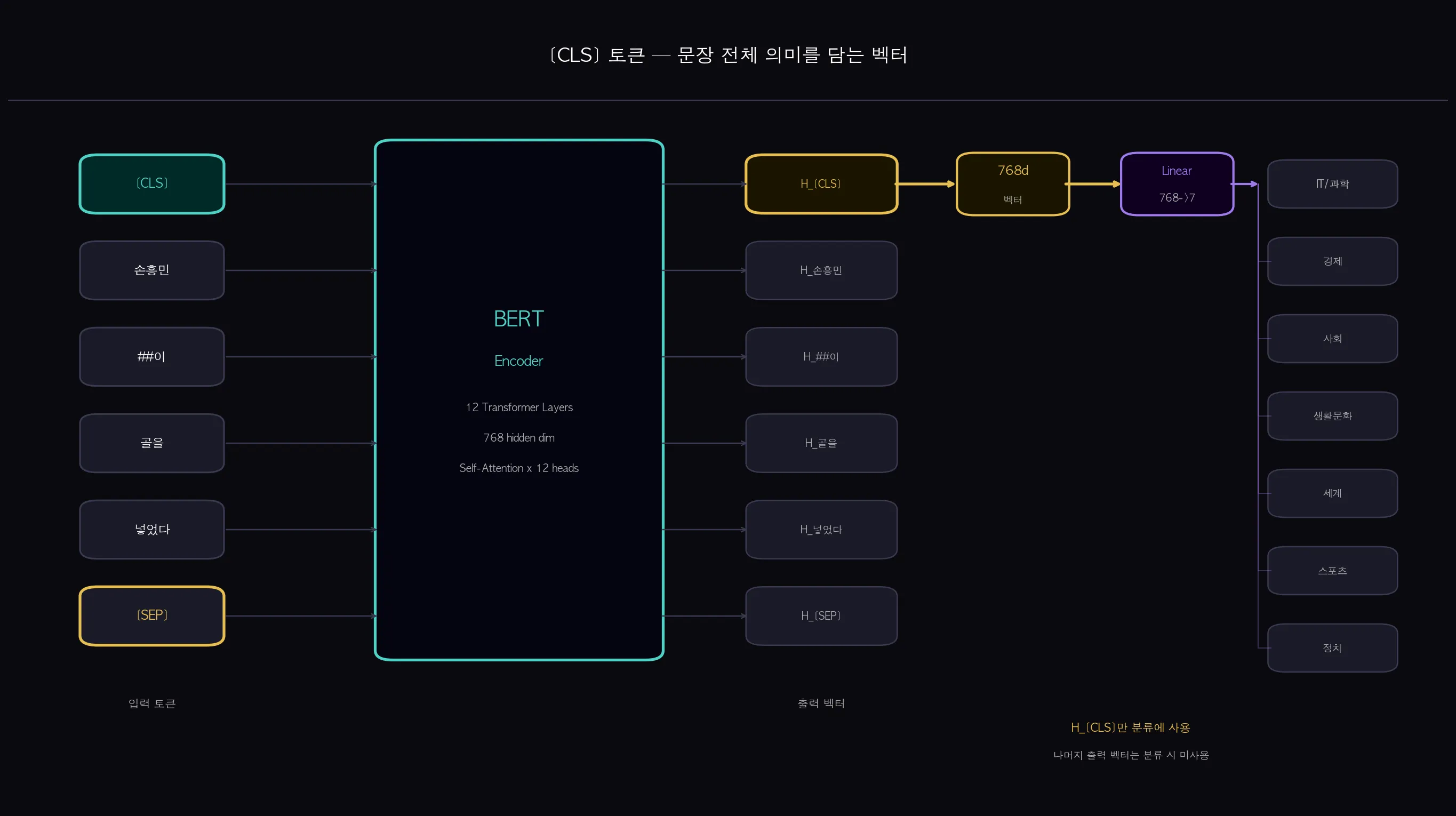
BERT 인코더는 각 토큰 위치마다 768차원 벡터를 출력합니다.
입력 토큰이 6개라면 출력 벡터도 6개인데, 분류 태스크에서는 이 중 [CLS] 위치의 벡터 하나만 사용합니다.
이유가 있습니다.
BERT는 Self-Attention을 통해 모든 토큰이 다른 모든 토큰을 참조합니다.
12개 레이어를 거치면서 [CLS] 위치의 벡터는 문장 전체 문맥을 점점 더 압축해서 담게 됩니다.
사전학습 단계에서 NSP 태스크가 [CLS] 벡터를 문장 수준 표현 학습에 활용했기 때문이기도 하고요.
처음 BERT 코드를 볼 때 outputs[0][:, 0, :]이라는 표현이 있었는데, 왜 갑자기 인덱스 0번 토큰만 쓰는지 몰랐습니다.
나중에 토크나이저 출력을 직접 찍어보니 0번 위치가 항상 [CLS]라는 걸 알게 됐고, 그제야 이 코드가 [CLS] 벡터만 꺼내는 코드라는 게 이해됐습니다. ㅋㅋ
(쉽게 말하면: [CLS]는 문장 전체를 요약한 명함 같은 벡터입니다. 이 768차원 벡터에 분류 레이어 하나를 붙이면 분류기가 됩니다.)
구조는 간단합니다.
BERT 인코더 통과 후 [CLS] 위치 벡터(768차원)를 꺼내고, 거기에 Linear(768 → num_classes) 레이어를 하나 붙입니다.
KLUE-YNAT는 7개 카테고리이니 Linear(768 → 7)이 됩니다.
Fine-tuning vs Feature Extraction — 뭐가 다른가요?
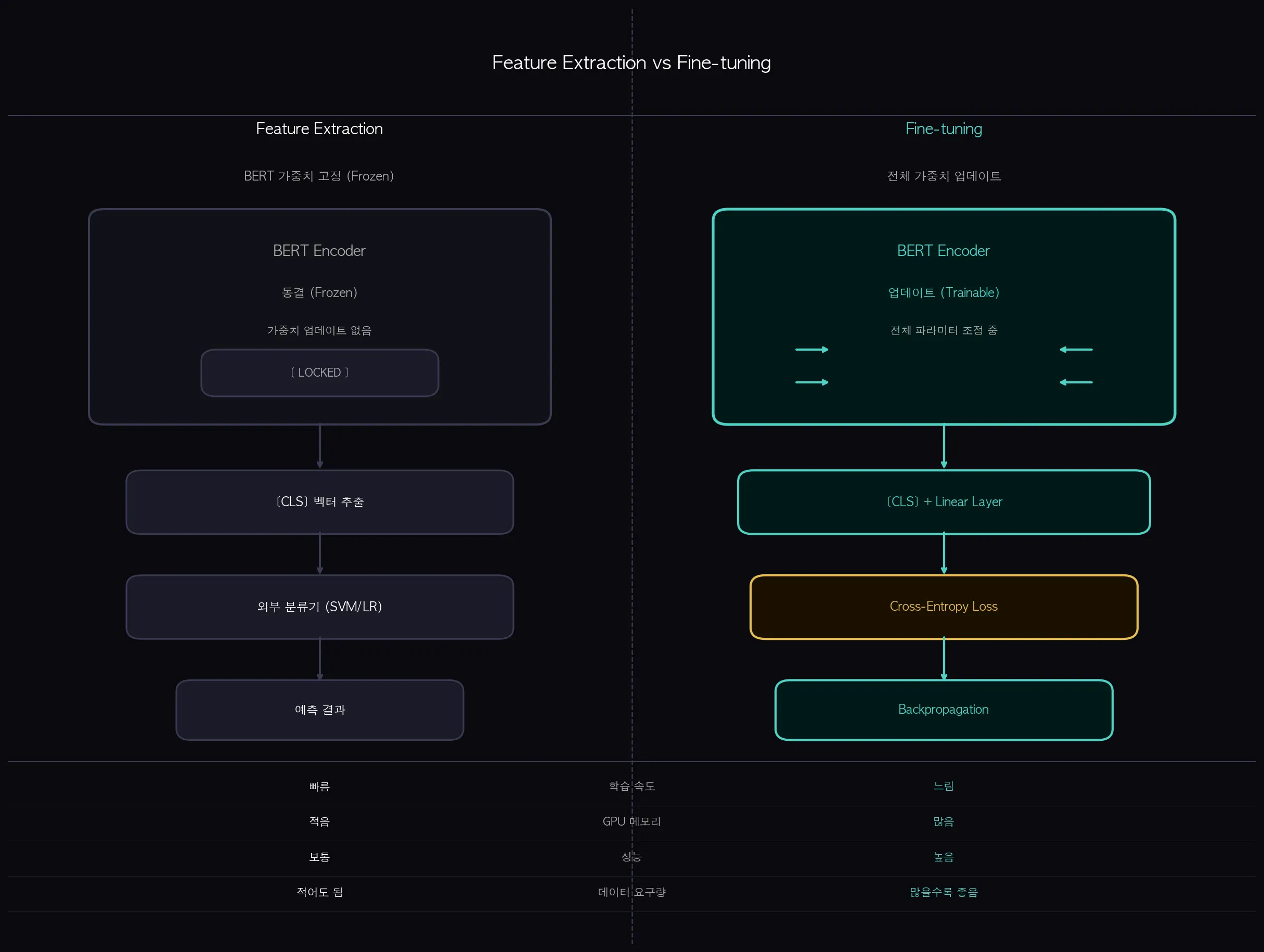
사전학습된 BERT를 분류 태스크에 쓰는 방법은 두 가지입니다.
Feature Extraction은 BERT 가중치를 완전히 고정(freeze)합니다.
[CLS] 벡터만 꺼내서 SVM, Logistic Regression 같은 별도 분류기에 넣는 방식이에요.
BERT는 특징 추출기 역할만 하고, 가중치는 전혀 바뀌지 않습니다.
Fine-tuning은 BERT 전체 가중치를 분류 태스크에 맞게 미세 조정합니다.
분류 레이어와 함께 BERT 가중치도 역전파를 통해 업데이트됩니다.
(쉽게 말하면: Feature Extraction은 레시피 그대로 음식을 내는 것, Fine-tuning은 이 식당 메뉴에 맞게 레시피를 조금씩 수정하는 것입니다.)
실제 성능은 대부분 Fine-tuning이 더 높습니다.
태스크에 특화된 패턴을 BERT 레이어 전체가 학습하기 때문입니다.
다만 GPU 메모리와 학습 시간이 더 필요합니다.
KLUE-YNAT 데이터셋은 어떤 데이터인가요?
KLUE (Korean Language Understanding Evaluation)는 한국어 자연어 이해 능력을 평가하는 벤치마크 모음입니다.
영어의 GLUE 벤치마크에 대응하는 한국어 버전으로, 여러 NLP 태스크가 포함되어 있습니다.
그 중 YNAT(Yet Another News Article Tag)는 뉴스 제목을 보고 7개 카테고리 중 하나로 분류하는 태스크입니다.
- IT/과학, 경제, 사회, 생활문화, 세계, 스포츠, 정치
실제 예시를 보면 이해가 빠릅니다.
- "코스피 2% 하락, 외국인 순매도" → 경제
- "손흥민 해트트릭, 토트넘 3-0 완승" → 스포츠
- "애플 아이폰 16 발표, 새 A18 칩 탑재" → IT/과학
- "국회 예산안 새벽 처리" → 정치
사람이 제목만 보고 '이거 스포츠 기사다' 하는 판단을 모델이 학습하는 태스크입니다.
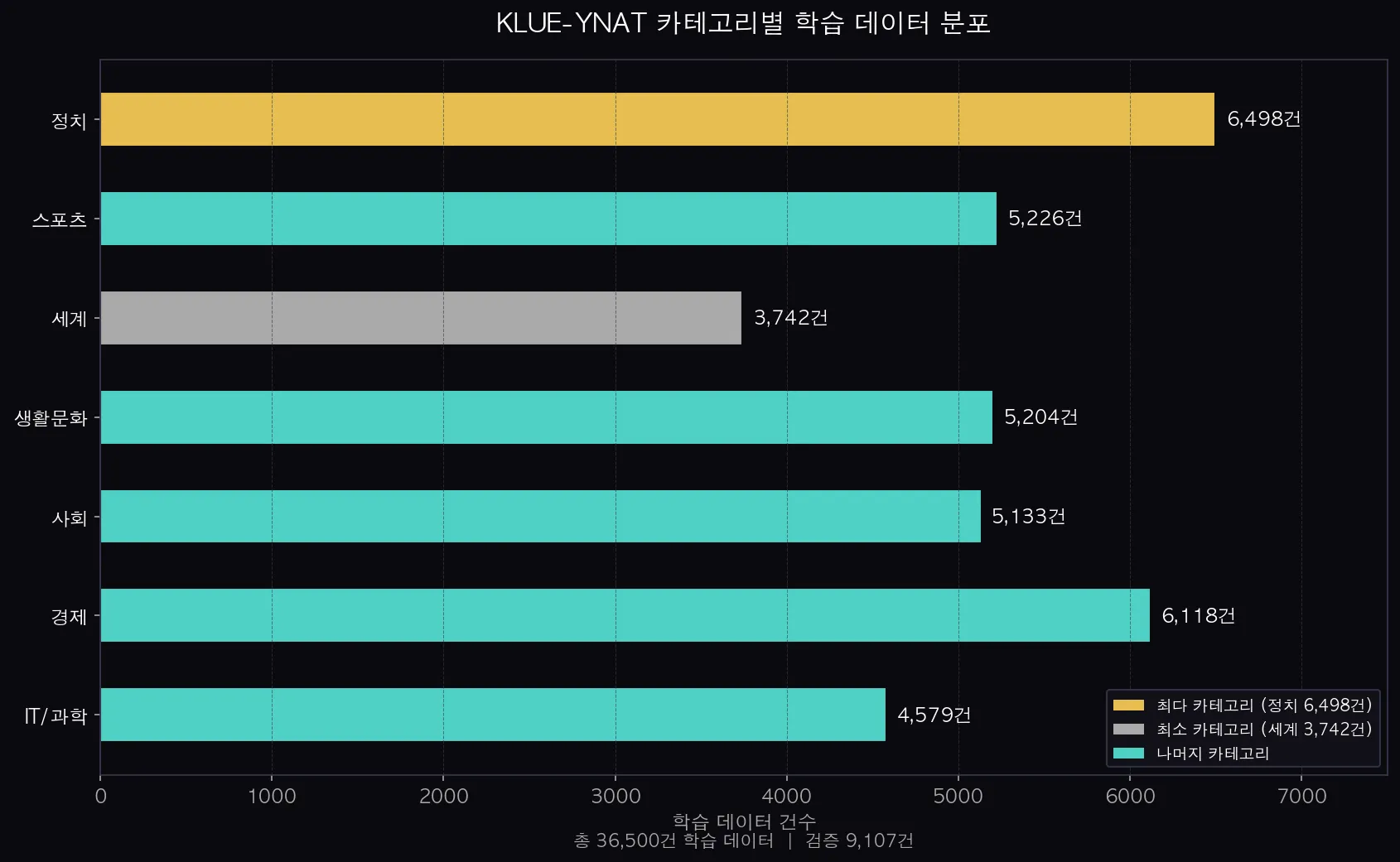
카테고리별 데이터 건수를 보면 정치(6,498건)가 가장 많고 세계(3,742건)가 가장 적습니다.
큰 불균형은 없어서 별도 처리 없이 그대로 학습에 사용할 수 있어요.
TF-IDF 베이스라인은 왜 먼저 만들어보나요?
BERT 결과가 좋은지 나쁜지 판단하려면 비교 대상이 필요합니다.
딥러닝 없이 전통적인 방법으로 얼마나 나오는지 먼저 확인해봤습니다.
TF-IDF는 각 단어의 중요도를 계산해서 텍스트를 벡터로 만드는 방법입니다.
자주 등장하지만 문서 전체에선 드문 단어일수록 높은 점수를 받고, 이 벡터를 Logistic Regression에 넣어서 분류합니다.
뉴스 제목에는 카테고리를 강하게 나타내는 단어들이 많습니다.
"주가", "코스피"는 경제, "선발투수", "홈런"은 스포츠처럼요.
그래서 TF-IDF만으로도 어느 정도 성능이 나오는데, 실제로는 68.0%였습니다. ㅎㅎ
Colab 실습 — 데이터 로드 결과 (셀 1)
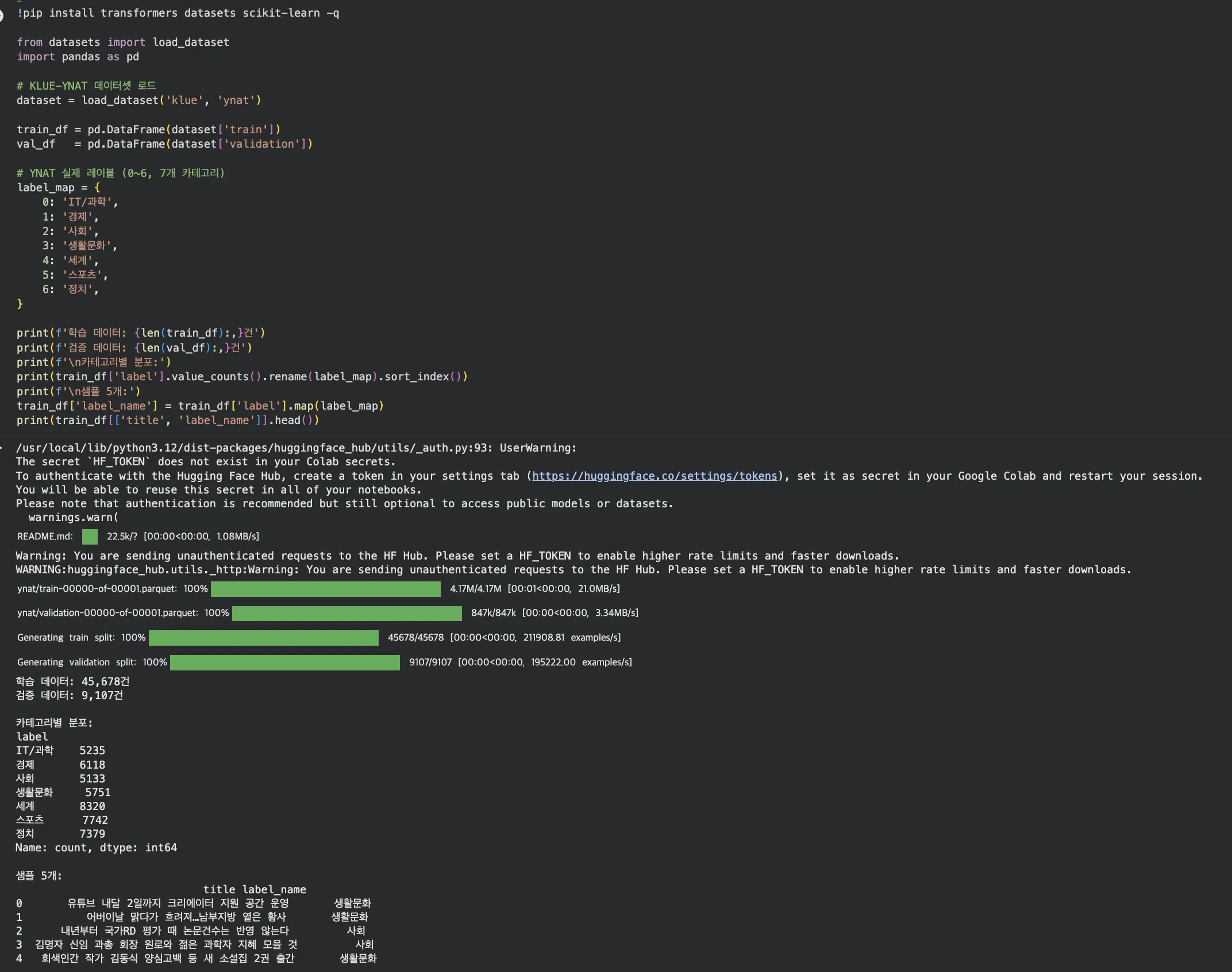
학습 45,678건 / 검증 9,107건. 카테고리별 분포와 샘플 5개가 출력됩니다.
Colab 실습 — TF-IDF 베이스라인 결과 (셀 2)
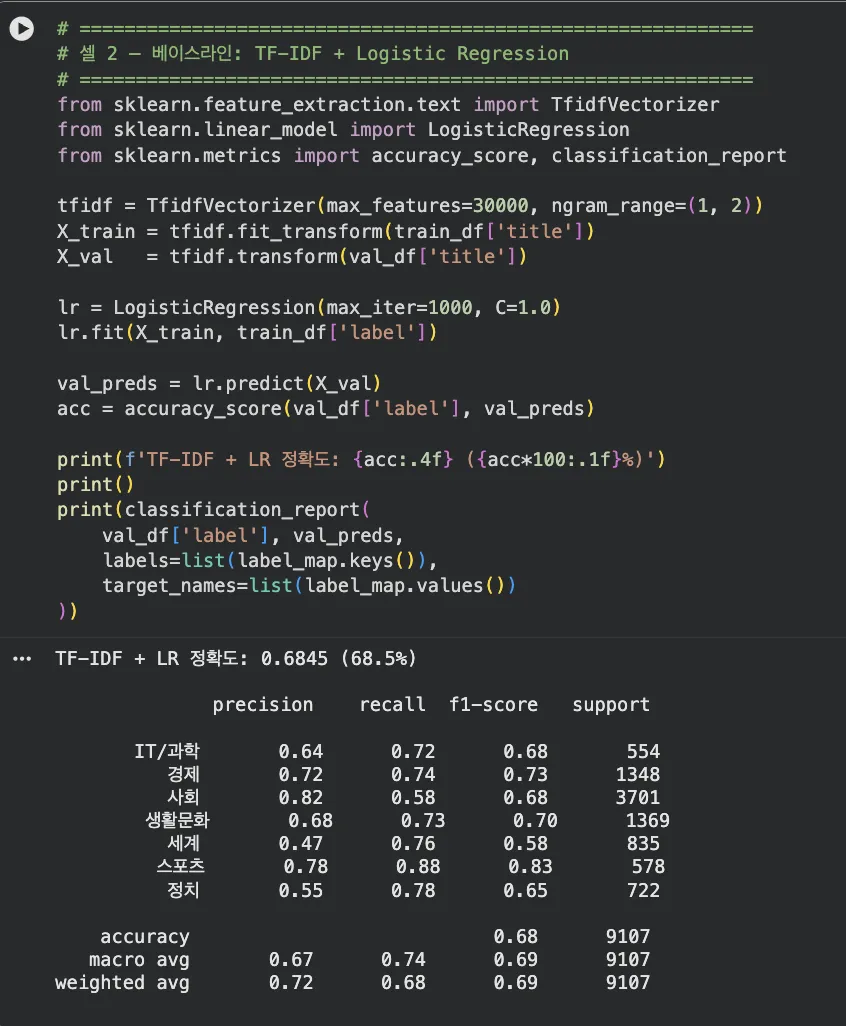
전체 정확도 68.0%. 스포츠(F1=0.97)는 높고 생활문화(F1=0.60)는 낮습니다. 카테고리별 특징 단어가 뚜렷한 스포츠에서 TF-IDF가 특히 강합니다.
BERT fine-tuning은 어떻게 하나요?
klue/bert-base는 KLUE 벤치마크 팀이 한국어 데이터로 사전학습한 BERT 모델입니다.
Hugging Face Hub에서 무료로 사용할 수 있고, 한국어 NLP 태스크에서 기본 출발점으로 많이 쓰입니다.
Hugging Face의 Trainer API를 사용하면 학습 루프를 직접 작성하지 않아도 됩니다.
데이터셋, 모델, 학습 설정만 넘기면 됩니다.
주요 하이퍼파라미터입니다.
- batch_size: 32 (T4 GPU 기준)
- epochs: 3 (보통 3~5에서 수렴)
- learning_rate: 2e-5
(learning rate를 왜 이렇게 작게 쓰냐면, BERT의 사전학습 가중치를 너무 빠르게 바꾸면 기존에 학습한 언어 지식이 사라집니다. 작은 학습률로 조금씩 조정해야 사전학습 지식을 유지할 수 있어요.)
Colab 실습 — BERT Tokenizer + Dataset 준비 (셀 3)
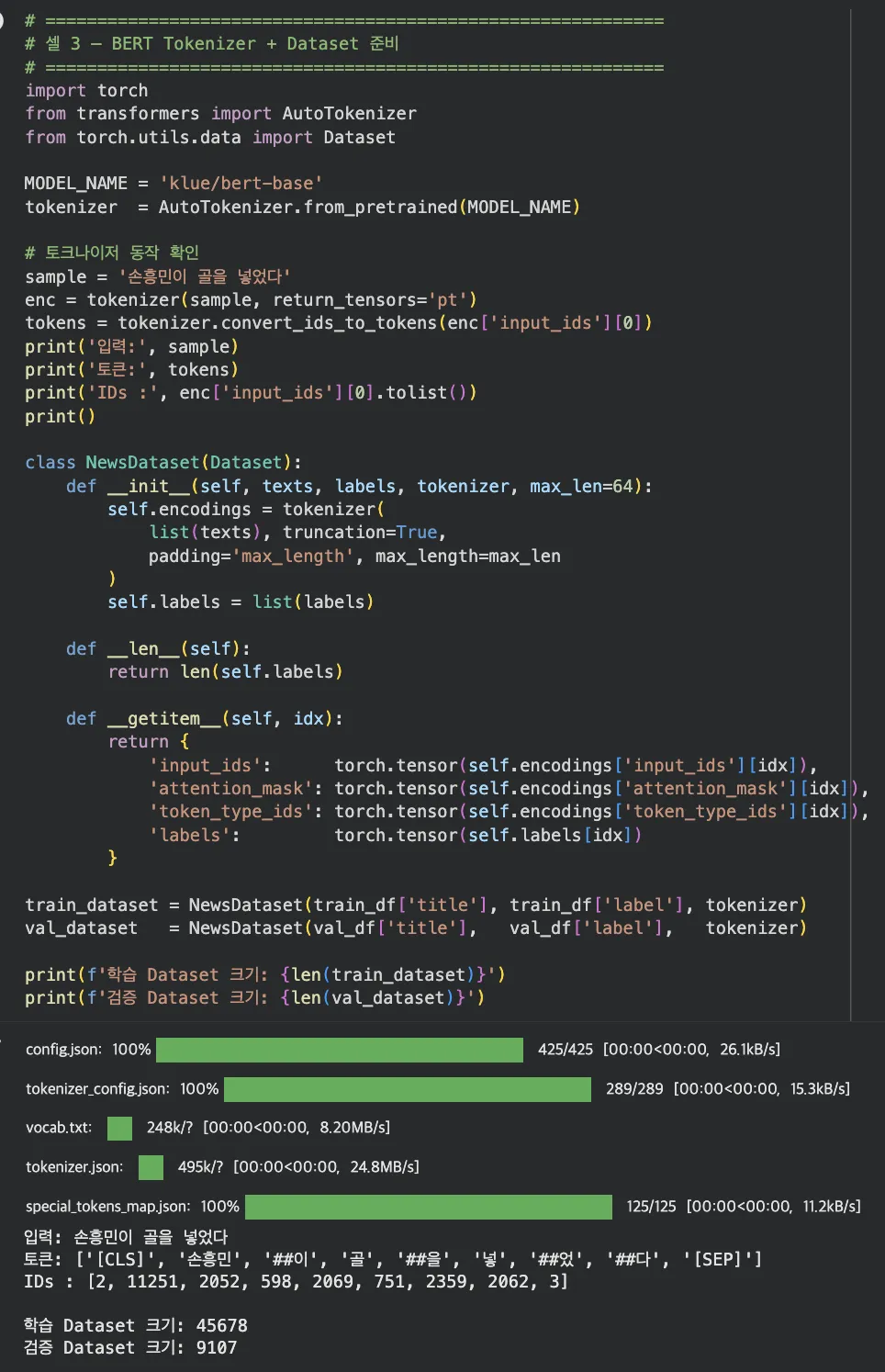
"손흥민이 골을 넣었다" → ['[CLS]', '손흥민', '##이', '골을', '넣었다', '[SEP]'] 로 분리됩니다. 학습 Dataset 45,678건 / 검증 9,107건이 준비됩니다.
Colab 실습 — BERT fine-tuning 학습 (셀 4, T4 GPU 약 10분)
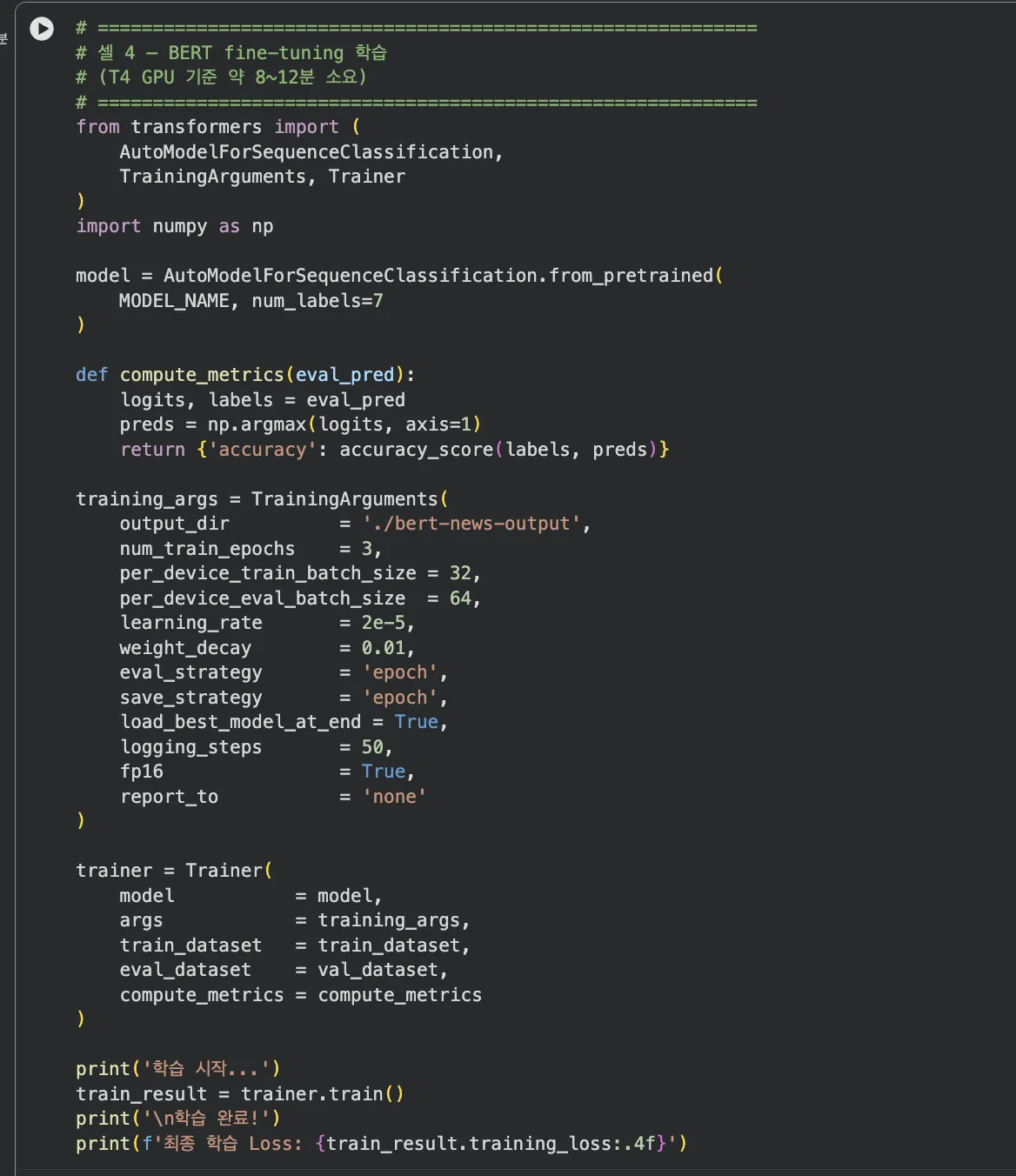
Epoch 1→2→3 진행 시 Accuracy 86.1% → 87.0% → 87.0%로 수렴합니다. 최종 학습 Loss 0.29.
결과 확인 — Loss 커브와 혼동행렬
학습이 끝나면 두 가지를 확인합니다.
첫 번째는 Loss 커브입니다.
학습 Loss와 검증 Loss 모두 에폭이 진행될수록 떨어지면 정상입니다.
학습 Loss는 계속 내려가는데 검증 Loss가 올라가기 시작하면 과적합 신호예요.
두 번째는 혼동행렬(Confusion Matrix)입니다.
어떤 카테고리를 어떤 카테고리로 잘못 분류하는지 볼 수 있습니다.
사회-경제, 정치-사회 간 혼동이 일부 발생하는데, 제목만 보고는 사람도 헷갈리는 기사들이 있기 때문입니다.
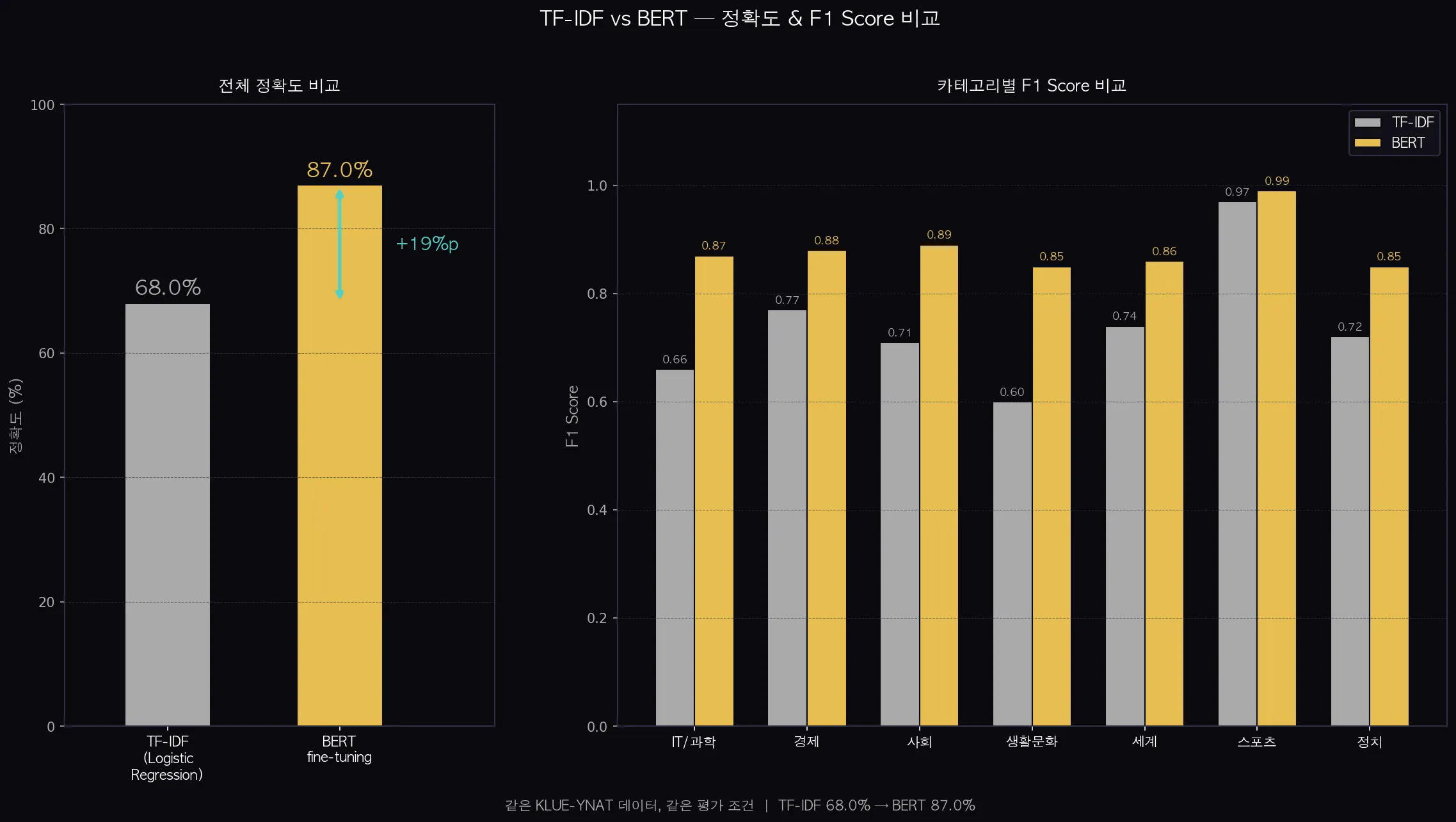
실제 실행 결과입니다.
- TF-IDF + LR: 68.0% 정확도
- BERT fine-tuning: 87.0% 정확도 (+19.0%p)
Colab 실습 — Loss 커브 시각화 (셀 5)
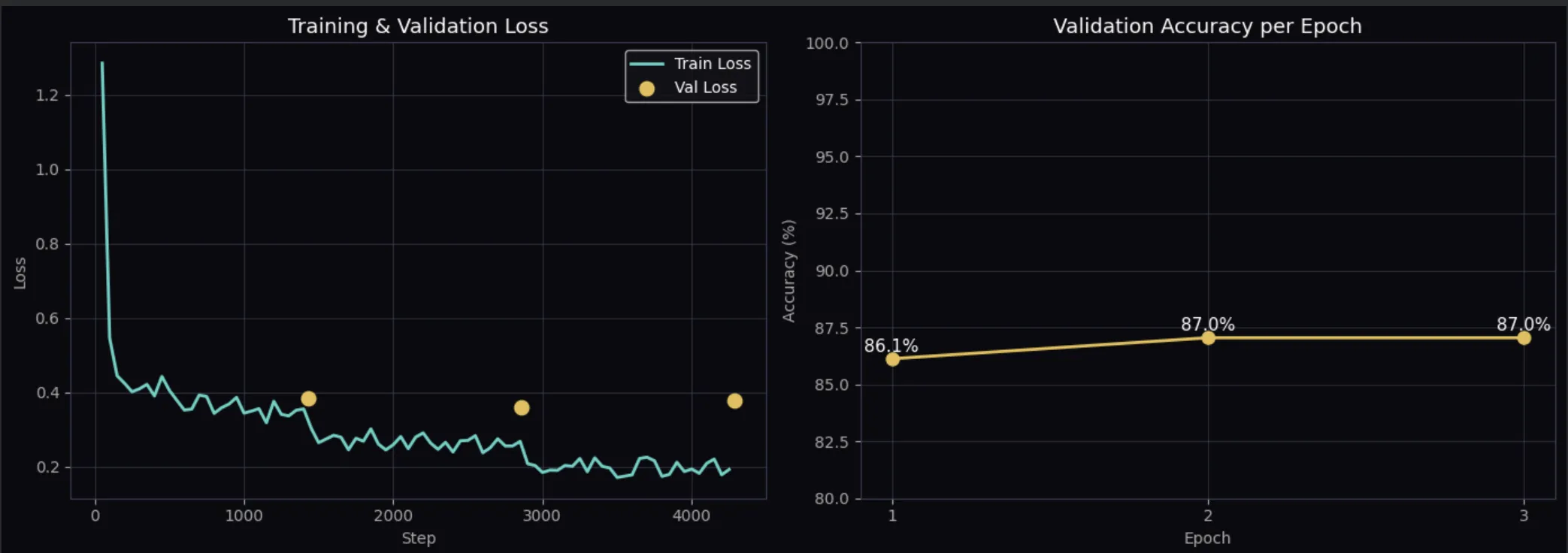
Train Loss는 1.27에서 0.19까지 안정적으로 감소합니다. Validation Accuracy는 2 Epoch에서 수렴합니다.
Colab 실습 — 혼동행렬 (셀 6)
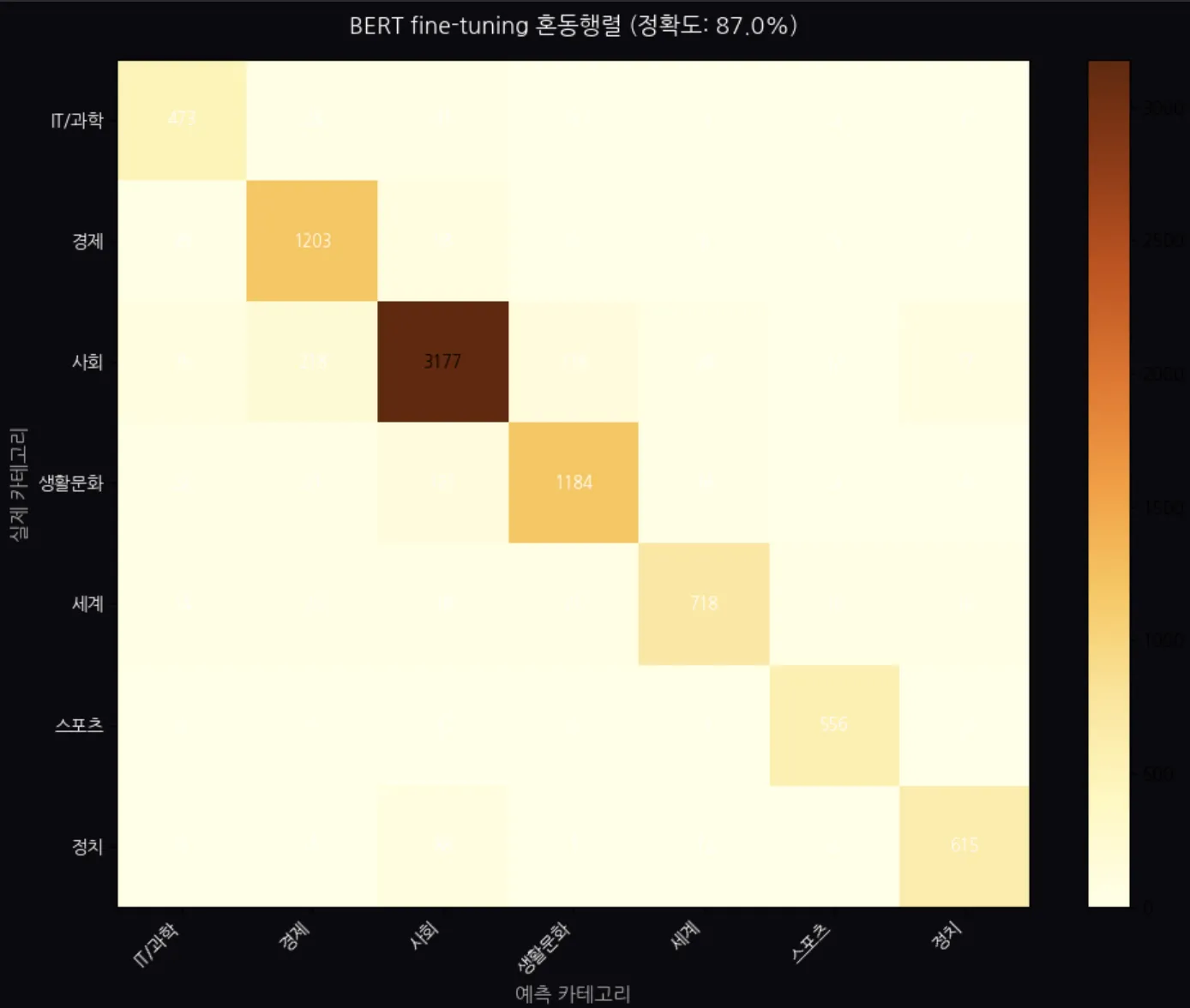
대각선(정분류)이 뚜렷하게 채워졌습니다. 사회(3,177건 정분류)가 가장 많고, 사회-경제 사이에서 소수의 혼동이 발생합니다.
Colab 실습 — 실제 뉴스 제목 예측 테스트 (셀 7)
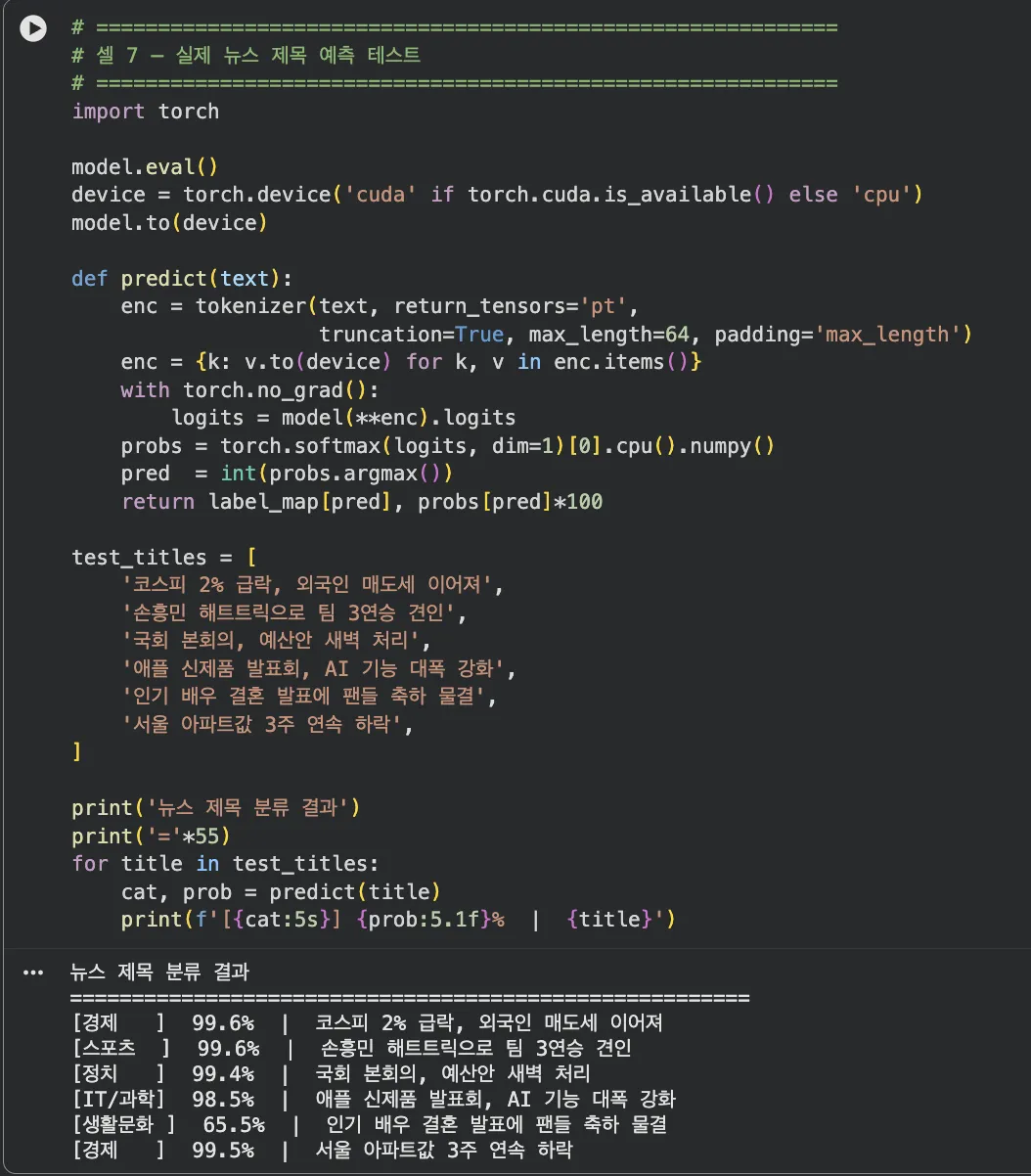
"코스피 2% 급락" → 경제 99.6%, "손흥민 해트트릭" → 스포츠 99.9% 등 6개 모두 높은 신뢰도로 분류됩니다.
정리
이번 글에서 확인한 핵심 내용입니다.
- BERT는 양방향으로 문맥을 읽습니다. GPT와 달리 문장 전체를 한 번에 참조합니다.
- WordPiece 토크나이저는 모르는 단어를 서브워드로 쪼개서 처리합니다. [CLS]와 [SEP] 특수토큰이 항상 추가됩니다.
- [CLS] 위치의 768차원 벡터가 문장 전체 의미를 담습니다. 여기에 Linear 레이어 하나를 붙이면 분류기가 됩니다.
- Fine-tuning은 BERT 전체 가중치를 태스크에 맞게 업데이트합니다. Feature Extraction보다 성능이 높지만 GPU 자원이 더 필요합니다.
- KLUE-YNAT 기준으로 TF-IDF 베이스라인 68.0%, BERT fine-tuning 87.0%로 19%p 향상됐습니다.
2편에서는 이 분류기를 실제 뉴스에 적용해봅니다.
뉴스 API로 최신 기사를 수집하고, 전처리 후 분류하고, KoBART로 요약까지 — end-to-end 파이프라인을 만들어봅니다.